


With Sync Services for ADO.NET, developers can easily optimize their online experience by caching data locally within the easy-to-deploy SQL Server Compact embedded database engine.
In this article, I’ll cover how Sync Services for ADO.NET was designed to fit the growing developer needs for caching data locally in online-optimized, offline-enabled applications.
There’s nothing new about wanting to cache data, or enabling users to work offline. The problem has been that enabling this functionally has been just too hard as the technologies required have been complex to deploy, manage, and haven’t really been focused on developers or productivity. Most applications are designed to solve some business problem requiring the developer to spend most of their time focusing on the business components of the application. All the infrastructure bells and whistles are cool, but it’s typically hard to justify the time spent on something the end user doesn’t see.
Microsoft designed Sync Services for ADO.NET to simplify the integration of local caching and synchronization into your application. It focuses on a goal of “Simple things should be simple while complex things should be enabled.” Sync Services for ADO.NET ships in two major upcoming products. Visual Studio 2008 marks the first release of the technology and ushers in unparalleled ease of use with an integrated Sync Designer leveraging SQL Server Compact 3.5 as the local cache. The second release of Sync Services for ADO.NET ships as a part of SQL Server 2008 enabling further server configuration simplicity with greater performance for sync-enabled applications. Sync Services 2.0 incorporates the Microsoft Sync Framework and enables additional support for non-relational data stores in collaborative, peer-to-peer topologies. This article discusses the project goals and functionality enabled with Sync Services for ADO.NET. For more info on the Microsoft Sync Framework, please read Moe Khosravy's article, Introducing the Microsoft Sync Framework-Next Generation Synchronization Framework.
Saving Leftover Pizza, or Shopping for Fresh Pasta and Sauce
When developers start thinking about caching, it’s helpful to consider there are multiple models to caching. I like to break them down into two distinct categories I call Passive Caching and Active Caching. With Passive Caching, the client portion of the application simply caches results to queries as they’re returned from the server. There’s not a lot of complexity here and it can be somewhat minimal impact to add to your existing application architecture, but as we’ll see, the benefits are minimal as well. With Active Caching, the application proactively seeks out to pre-fetch data that the client may require. Instead of pre-fetching answers to the individual queries, the application will retrieve the raw data required to answer the questions.
An alternative way to think about passive caching is the same way that you may shop for food. You could order out for pizza, Chinese food, or in some cities, you can have just about anything delivered directly to your home. Now imagine that instead of just saving the leftovers, you could actually “copy” the delivery and save it in your refrigerator. The refrigerator represents your local cache. The next time you’re hungry for Chinese food or pizza, you’re all set; you simply open the cache. But what if you want spaghetti and meatballs? You could place another order for delivery or you could dissect the pizza w/meatballs and the Chinese noodles to create the spaghetti. This can get quite complex, not to mention strange.
Turning back to the data example, what if you cached queries for Products.ProductName LIKE ‘a%’ or Products.Category = ‘Parts’. If you ask those same questions again, you can leverage the cache. But what if you ask for the top five products? If you just look at the cache, you only get the top five products that start with ‘A’ in the ‘Parts’ category. This starts to represent the limits of Passive Caching.
With Active Caching, your application will have brought down the raw materials to answer the questions. Just as you may shop for the raw material such meat, pasta, and spices, you can cache the appropriate amount of raw data. Sometimes raw data may be too detailed. Mom may not approve, but you might buy pre-prepped foods such as canned tomato sauce, which you then spice up to satisfy your unique taste. De-normalizing the data as it’s brought down to the client may be your tomato sauce. However, buying one of everything at your food store isn’t practical either. Determining the right subset can help you cook up the results you need locally without having to replicate the entire enterprise database. Microsoft Outlook uses this same model with Exchange Server. The appropriate filter of data, your inbox, calendar, tasks etc., are brought down to your cache and you then search, filter, and group the data locally, offloading the details from Exchange Server.
De-normalizing the data as it’s brought down to the client may be your tomato sauce.
Simplifying Data Access by Caching Data Locally
In addition to the benefits of Active Caching, another reason to cache data is it can actually simplify your overall development. While many applications may start fairly simple, allowing the client to directly query the database, many applications quickly move into the enterprise or need to communicate over the public Internet. To limit the server exposure, clients communicate via services which are responsible for opening the connections to the database behind the firewall. This architecture quickly adds a lot of complexity to your development. As seen in Figure 1, for each question your users ask the server, the development team would need some subset of the following:

- Stored procedures and/or views for each query on the database
- Configuration of permissions on each of the objects
- Load testing and tuning of the queries as the server has a multiplier of users asking intersecting questions
- Indexes supporting the WHERE clauses of the sprocs & views
- Service contract wrapping each sproc/view with potentially a custom object definition for the result shape
- Client proxies for each service API
- And of course the supporting UI to ask and answer each question
Making even the simplest change to the queries or results can be painful to implement across the entire stack requiring many roles in your development team to get involved. Back to my pizza example, what if you wanted extra cheese, or you wanted everything but onions on the “everything” pizza? Since you’re getting pre-cooked meals, you must go back to the food store or possibly to the supplier. Of course this isn’t very practical. To solve the problem, many development teams automate the creation of these various tiers, however inevitably there are changes that require database tuning for each interleaving query. Once the application goes into production, it’s difficult to make changes as the changes typically trickle across all tiers, requiring a new version of the entire stack.
By leveraging this pre-fetch, Active Caching model, you can now simplify your application development. The DBA and service developer now maintain a set of services that serve out raw data, or essentially your version of your local food store. Just as the food store has frozen pre-cooked dinners, or even hot, ready-to-eat meals, the services will likely offer a blend of sync services and live services that may not be practical to “cook up” locally. As you can see in Figure 2, with the raw data local, the UI designer, client developer, and end user can be quite productive, asking all sorts of interesting questions without having to worry about the impact to the central resources. This can not only be productive for development, but extremely powerful to end users as they can now ask complicated questions that could have caused havoc to the multi-user server. The local query may not always be the most efficient query, but only the individual user is affected as there’s no multiplier of users on a local cache. This reduces the workload to the production server as it only needs to return changes to the raw data.
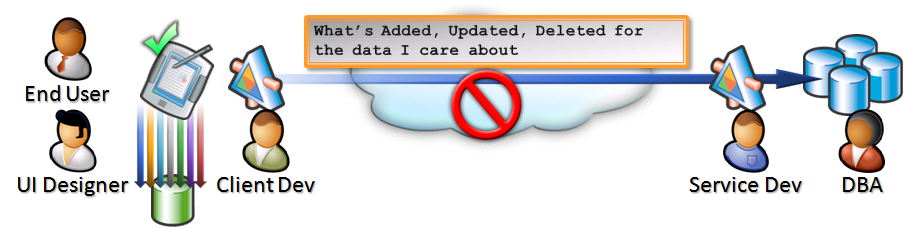
Micro Management or Delegation
In addition to the change management issues above, how much duplication of effort should you implement within your application? Though I am writing this article for a special CoDe Focus issue of CoDe Magazine, typically Rod Paddock (Editor-in-Chief of CoDe) would create a theme for each magazine and then find appropriate authors for each article. They may enlist a writer like me for a topic; they’d provide me a target page count, a Word template, and CoDe Magazine publishing guidelines. I then go offline and write the article. When done, I submit it for editing. A few days later I’ll get the article back with the edits. (The number of edits typically relates to how well I followed the guidelines.) I review the changes, making sure the underlying meaning isn’t lost and submit it again for “validation”. If all is accepted, the article goes into layout and publishing. If not, we repeat the same validation and editing loop. This model scales as Rod employs the expertise of great editors such as Erik Ruthruff for overall content quality and delegates the technology expertise to the individual authors.
Now imagine this process in the “online” electronic model. As I write, I’d submit each paragraph, heading, and figure to CoDe for validation. Since I’m not as structured as some writers, I tend to write out my thoughts, chunk them up, and continually reorganize them. This can make my style challenging to edit, so imagine if I submitted my content as I write it. This wouldn’t be very practical as Erik has other articles he needs to edit. If Erik has to micro-manage my writing, I’d create too much work for him, which begs the question, why enlist me to write the article? We’ve all been in this situation before thinking it’s too much trouble to explain and you should just do it yourself. But if you did that for everything, could you get everything done you needed to do? This delegation of responsibilities is how most things scale.
Just Because You Can, Doesn’t Mean You Should
Consider an order management system. For each order, and each line item, how much of the system needs to be involved? Does the server really need to know the details for how each line item is added? Or, similar to the article editing process, should the user get the reference data they need to create the order including the product catalog, categories, pricing, and customer info. As they create orders, users could save them locally until they are ready to be submitted. The server then receives completed orders and revalidates them for accuracy. It’s just software, so why not have all the logic on the server?
As corporate data centers evolve, the amount of central processing is causing them to grow at an exponential pace. While data centers grow, client computers are leaving lots of processing power “on the table”. This is starting to look a lot like the mainframe to PC revolution all over again. The difference this time may be balancing both the use of the client and the central servers. In the mainframe days, the client sent each keystroke to the server. Browsers offload entry and minimal validation to the client. Is bringing reference data to the client just a continuum of the PC evolution?
Browsers offload entry and minimal validation to the client. Is bringing reference data to the client just a continuum of the PC evolution?
By offloading some of the validation to the client, applications can better leverage each tier in the architecture and empower users to make important and quick decisions, while focusing the server on validating completed orders. Just because companies can centrally run all the application logic doesn’t mean it’s the best overall solution for those data centers or the end users who get frustrated at the latency and the requirement that they be tethered to the network. Using this layered, empowered approach, you’ll likely find that you can make many enhancements in one portion of the application without affecting other tiers. If you already have the reference data on the client, you can likely cook up other enhancements by simply versioning the client app and leaving the central services alone.
How to Keep Your Cache Up to Date
Now that you may be convinced having a local cache can help your clients make better decisions, how do you keep the cache up to date? In my food shopping comparison, you use up resources and need to replenish them when inventories get low. With reference data, you don’t “use up” data, but rather need to get updates to the data. With Active Caching, you bring down the raw materials. But similar to food shopping, you don’t re-purchase everything; you just get “the updates.” There are a few models to tracking changes. The server could keep track of all the clients or the clients can track their own reference points.
As each client asks, “What changed for me?” the server can send its change list. The problem with this model is scalability. While this may work for a small number of clients, as you get to the thousands, this model tends to fall over as the server must track changes for each client. Rather than have the server track each client, what if the server simply tracked when changes were made? As each client synchronizes with the server, the client simply stores the reference point of the server, so later on, it can ask for what’s changed since the last reference point.
So imagine this scenario: On Monday Adam, your user, installs the Order Entry application. Adam downloads his product line from the overall catalog and the customers for his region. After a two-day road trip, he reconnects to the corporate servers. Rather than asking the servers for what data it has for Adam, the application asks what’s changed since Monday for his product lines and his customers. In Sync Services for ADO.NET, the storing of the server’s reference point on the client is known as an anchor-based tracking system. This works really well for centrally managed data systems that need to support a large number of clients.
Painting the Big Picture
Before jumping into the details for Sync Services for ADO.NET, it may help to understand a number of key design goals and priorities that our team had in mind.
- Simple things should be simple while complex things should be enabled.
- Work within friction free, non-admin, Web deployment models.
- Be developer-oriented and leverage their domain-specific skills for each type of data source.
- Deliver an end-to-end experience built on a layered component model.
- Enable independent server and client configuration empowering the client application to determine the data it needs, while freeing the server to version independently offering additional services.
- Enable rich eventing on all tiers for conflict detection and business rule re-validation for domain-specific data sources.
- Enable easy movement/refactoring between two-tier, n-tier, and service-oriented architectures.
- Be protocol and transport agnostic leveraging the various transports, protocols, and security models developed by other smart folks at Microsoft (Web services, WCF, …).
- Enable endless scalability of the number of clients synchronizing with the server.
- Provide a common sync model for all types of data, not just relational data, but files and custom data sources.
- Ensure data can be exchanged in a variety of connectivity patterns including centralized and collaborative, peer-to-peer topologies.
- I’ll expand on these points a bit below, providing a bit more context. As we started to scope the effort of accomplishing these goals, we considered the common data sources that developers required. The most obvious were files and relational data. XML data sort of fell into a combination of files and unstructured relational storage. In many cases developers were choosing XML storage as it was too hard to deploy anything else. For Sync Services for ADO.NET version 1.0 (hereafter, V1) we decided to focus on relational data in a centralized topology, but carefully designed the system to support other data sources in the future. Be sure to read Moe Khosravy’s article, Introducing the Microsoft Sync Framework-Next Generation Synchronization Framework, covering the broader goals for the sync platform including peer-to-peer topologies.
- As we scoped V1 to relational data, we elaborated on the domain-specific data sources:
- Leverage a developer’s ADO.NET experience while being DBA-friendly for server configuration.
- Deliver a good, better, best programming model enabling any ADO.NET server database, provide a designer for SQL Server, and use SQL Server 2008 to deliver the best overall performance and simplest to configure.
The Power of SQL Server in a Compact Footprint
While many IT-supported applications were successful deploying SQL Server Express, the majority of applications didn’t have direct IT support. Many of these applications were persisting their data as XML using serialized DataSets as they couldn’t use SQL Server Express due to its deployment requirements. With our V1 scoping to relational data and our design goals prioritizing non-admin, Web deployment models, we knew we had to enable a local store that could deliver the power of SQL Server in a compact footprint.
Since 2001, SQL Server has had an embedded database engine available to the Windows Mobile platform known as SQL Server CE. Targeted at devices, Microsoft designed it for constrained environments, but it still had the power to handle relatively large amounts of data in a compact footprint. With a footprint under 2 MB, it became a popular choice for applications that need the power of SQL Server in a compact footprint. Several applications in Windows Vista, Media Center PC, and MSN Client all embedded this engine within their applications. You likely didn’t even know you had SQL Server Compact running, and that’s one of its key advantages. It’s simply embedded cleanly within each application.
In 2005, SQL Server CE became SQL Server Mobile to recognize its expanded usage on the Mobile platform of the Tablet PC. With Visual Studio 2005 focusing on client development, we knew we couldn’t wait for Visual Studio 2008 to enable developers looking to cache data for optimized online or those building offline applications. We knew we’d take a while to complete Sync Services and SQL Server Mobile simply needed a licensing change. With Visual Studio 2005 Service Pack 1 we released SQL Server Compact 3.1 as the successor to SQL Server Mobile and SQL Server CE to address all our current Windows desktop operating systems.
Some of the key benefits of SQL Server Compact include the following:
- ~1MB for the storage engine and query processor.
- Consistent engine and data format for all Windows operating systems from the phone to the desktop.
- Runs in-process (i.e., embedded).
- Deployed as DLLs eliminating the need for a Windows service.
- Supports central installation with traditional MSI (requires administrative rights).
- Supports private deployment of the DLLs within the application directory (enabling non-admin deployment).
- Full side-by-side support for multiple versions enabling different applications to embed SQL Server Compact without fear that other applications using newer versions may destabilize their application.
- Rich subset of query programming of SQL Server.
- Rich subset of data types of SQL Server.
- Robust data programmability through ADO.NET with native programmability through OLE DB.
- ISAM-like APIs for bypassing the query processor, working directly against the data.
- Updatable, scrollable cursors eliminating the need for duplicate, in-memory copies.
- Support for up to 4GB of storage, with increasing storage in future versions.
- Rich sync technologies including Merge Replication, RDA, and Sync Services for ADO.NET.
- Full support for SQL reporting controls.
- Single-file code-free file format enabling a safe document-centric approach to data storage.
- Support for custom extensions enabling double-click association with your application.
- Support for network storage, such as network redirected documents and settings.
- Concurrent application support from multiple processes or threads enabling sharing of data on a single user’s machine.
- Best of all, it’s free to deploy, license, distribute, and embed within your applications.
- With SQL Server Compact 3.1 shipping with Visual Studio 2005 SP1, developers can fill the need between XML storage and SQL Server Express. With Visual Studio 2008, SQL Server Compact 3.5 ships as the default local database with integrated designer support including the support of Sync Services for ADO.NET and LINQ to SQL. With the release of the ADO.NET Entity Framework, SQL Server Compact will be used to persist ADO.NET entities locally within your application.
- Future versions of SQL Server Compact will continue to take advantage of the unique embedded nature to provide an integrated experience within your application programming model. SQL Server Express will certainly continue for developers requiring the same programming model with our data service SKUs, including Workgroup, Standard and Enterprise. SQL Server Express and SQL Server Compact are not meant to compete, but rather provide overlapping technologies enabling the unique needs of custom applications. They are best when used together with SQL Server Express as the free entry point to Microsoft’s data service platform and SQL Server Compact as the local cache utilizing Sync Services to synchronize the shared data and local cache.
Simple to Complex
As developers are continually challenged with new emerging technologies, it becomes difficult to invest a lot of time learning a technology just to get the simple things done. To enable the simple scenarios with the complexity as needed, Sync Services took an incremental approach to its design. This includes simple snapshot caching, enabling developers to add incremental changes, or ultimately the ability to send changes from the local store back up to the server.
Additionally, many applications may start off as two-tier applications and over time they expand requiring n-tier architectures. Rather than assume you must re-architect the application to make this move, Sync Services was designed to easily move from two-tier to n-tier architectures, including service-oriented architectures (SOA). Figure 3 shows how the components are broken into groupings. You can see server components, client components, and a SyncAgent which orchestrates the overall synchronization process.
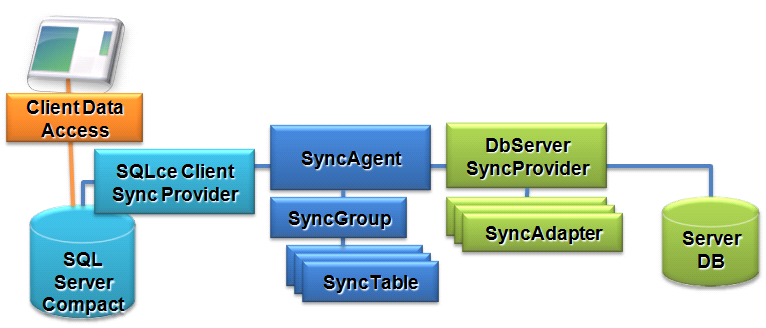
Building On Your ADO.NET Skills
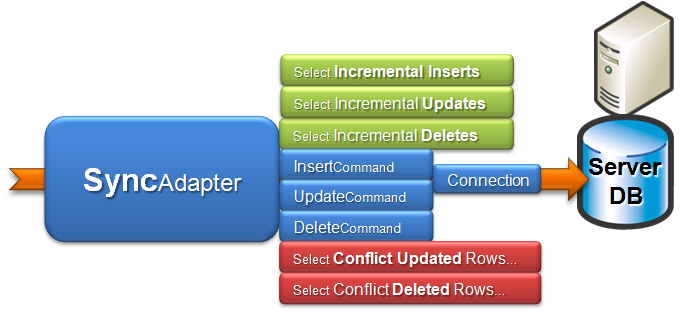
One of the significant improvements between classic ADO and ADO.NET was the ability to drill into and configure the commands which were executed against the server. With ADO.NET, components such as the DataAdapter retrieve data from your database populating a disconnected DataSet sending the data across the wire. As inserts, updates and deletes are made, the DataAdapter can shred the changes based on the RowVersion in the DataSet, executing insert, update and delete commands that may have been configured for you, or customized to suit the needs of your specific application using custom T-SQL, sprocs, views or functions. However the DataAdapter is designed for a one-time retrieval of data. It doesn’t have the infrastructure to retrieve incremental changes. As seen in Figure 4, Sync Services uses a SyncAdapter, which is based on the DataAdapter programming model. The SelectCommand is replaced with three new commands for retrieving incremental changes.
Configuring each command and its associated parameters can be quite tedious, especially when you just need the basics. Similar to the SqlCommandBuilder, Sync Services adds a SqlSyncAdapterBuilder which allows you to specify a few configuration options to create a fully-configured SyncAdapter. While Sync Services can work with any ADO.NET provider, the SqlSyncAdapterBuilder is specific for Microsoft SQL Server enabling the “Better on SQL Server” design goal.
Server Configuration
Figure 3 shows the green portions representing the server-side configuration. As most database servers are shared servers for several applications, each application may only require a subset of the data, or the data may need to be reshaped or de-normalized before it travels down to the client. For this reason, Sync Services exposes granular configuration with ADO.NET DbCommands enabling any ADO.NET data provider. For each logical table you wish to synchronize, a SyncAdapter is configured.
One of the challenges with DataAdapters is the ability to update parent-child relationships. With common referential integrity patterns, child deletes must first be executed before the parents can be deleted. Likewise, parents must first be created before children can be inserted. The DbServerSyncProvider contains a collection of SyncAdapters that enables the hierarchal execution of commands based on the order of SyncAdapters in the collection.
Client Configuration
The client has two main components. The client provider, in this case the relational store of SQL Server Compact, and the SyncAgent which orchestrates the synchronization process. You could sort of think of the SyncAgent as the thing that does the food shopping for you once you’ve given it the shopping list, and location of the food store. While server databases tend to be shared resources, client databases are typically specific to the application. With this design simplicity there’s no need for configuration of the individual commands for each local table. However as client applications get installed on potentially thousands of clients, there are a number of other deployment options. Other configuration options such as what subset of server data each client actually requires and the ability to group several tables within a transactional sync operation can be achieved with a SyncGroup configured through the Configuration object of the SyncAgent. Once the SyncAgent is configured with a RemoteProvider, LocalProvider and the SyncTables, you can simply call the Synchronize method.
In two-tier architectures the RemoteProvider is the DbServerSyncProvider. Later in this article, in the section called “Going N-tier with WCF,” I’ll discuss how you move from a two-tier architecture to something with multiple tiers. To enable different data sources ranging from relational databases to files, as well as custom objects, Sync Services follows a standard provider model. Sync Services 1.0 includes a relational provider for SQL Server Compact, or the SqlCeClientSyncProvider.
Configuring the SqlCeClientSyncProvider only requires a connection string for the local database with the default option to automatically create the local database and schema. Similar to the auto creation of the database, the SyncTable configuration enables options for creating the tables and whether local changes to the table should be synched back to the server. Several events are available within the client and server providers enabling conflict detection and business rule validation.
Designer Productivity
To meet our developer productivity design goal, Visual Studio 2008 adds a Sync Designer to simplify configuration of Sync Services for ADO.NET. Similar to the design goals for Sync Services, the Sync Designer starts simple and lets you incrementally add complex requirements as needed. The Sync Designer focuses on the following:
- Configure SQL Server databases for change tracking, including tracking columns, tracking tables (known as Tombstone tables) and triggers to maintain the tracking columns.
- SQL scripts generation for later reuse and editing when moving from development to production.
- Generation of typed classes for instancing the sync components, similar to the typed Dataset and TableAdapter experiences.
- Auto creation of the local database and schema, including primary keys.
- Separation of client and server components to enable n-tier scenarios.
- Creation of WCF service contracts for n-tier enabled applications.
The Visual Studio 2008 Sync Designer is focused around read-only, reference data scenarios, so you won’t see any configuration for uploading changes. However, the designer does generate the upload commands-they’re just not enabled. Similar to typed DataSets, you can extend the designer-generated classes through partial types enabling the upload commands with a single line of code per table. By selecting “View Code” from the Solution Explorer context menu on the .sync file you can reconfigure the Customers table to enable bidirectional synchronization as seen in Listing 1.
Other features of Sync Services that aren’t enabled through the designer but can be extended through partial classes are:
- Filtering of columns or rows
- Foreign keys, constraints, and defaults
- Batching of changes
To get a feel for the designer simply add a Local Database Cache item to any non-Web project type. The Local Database Cache item aggregates the configuration of Sync Services for ADO.NET and SQL Server Compact 3.5 for the local cache. The designer will enable connections to SQL Server databases and will automatically create a SQL Server Compact 3.5 database. With the server database selected, you can add tables to be cached based on the default schema of the user id in the SQL Server connection string. By checking one of the tables the designer will configure the server tracking changes using “smart defaults”.
If you can’t make server-side changes to your database, and the data is small enough to just retrieve the entire result each time you sync, you can change the “Data to download” combo box to “Entire table each time,” also known as snapshot. When performing snapshot sync, the tracking combo boxes become disabled as the SQL Server configuration options aren’t required. Assuming you want incremental changes, you can then choose which columns will be used to track the changes. The designer will default to adding an additional DateTime column for LastEditDate and CreationDate. If your table already has TimeStamp columns for last updates, you can select the existing column. Sync Services stores a common anchor value for last edit and creation columns, so you’ll need to either use DateTime or TimeStamp on both the last edit and creation tracking columns. Since you can only have one TimeStamp column per table, you’ll notice that if you choose TimeStamp for the LastEdit comparison, the creation column will default to a BigInt. Timestamps are really just big integers serialized in binary form.
Tracking Deletes
Tracking deletes is an interesting problem. If you synchronize with the server on Monday, and come back on Wednesday asking what’s changed, how does the server know what’s deleted unless it keeps a historical record? There are a couple of different approaches to tracking deletes. Prior to the Sarbanes-Oxley (SOX) compliance days, it was typical to just delete aged data. However, between SOX and increased disk storage, applications are keeping the deleted data around. While it’s important to keep the deleted data on the server, it’s typically not necessary to clog up your clients. When each client synchronizes, Sync Services simply requests the list of primary keys that should be deleted locally.
Tombstones
A standard model for tracking deletes is to create a separate table that contains the primary keys for deleted rows. Just as cemeteries use tombstones to leave an indicator of what once was, tombstone tables have become the standard in many sync-enabled systems. Another interesting analogy is how tombstones, if not managed, could eventually cover the earth leaving no room for the “active participants.” Luckily data is a lot less emotionally sensitive so a standard model is to purge tombstone records after a period of mourning. How long you keep your tombstones is related to a balance of disk space, database sizes, and how long you expect your users to work offline. The pre-SQL Server 2008 model could utilize a scheduled task to run daily to purge tombstones that are older than a configured number of days. Furthering our goal to make Sync Services run “Best on SQL Server,” SQL Server 2008 adds a feature known as SQL Server Change Tracking that dramatically simplifies this server configuration and reduces the overhead by tracking changes deep within the SQL Server engine. Change tracking incorporates a change retention policy that automatically purges historical changes based on the per-table configured value.
Since Visual Studio 2008 ships prior to SQL Server 2008, and developers may need to target pre-SQL Server 2008 servers, the Sync Designer will default to creating a Tombstone table and the associated triggers to maintain the tracking information. As with the rest of the SyncAdapter configuration, if the designer-generated commands don’t fit your needs, you can easily customize these commands using sprocs, views, and functions. Sync Services simply needs a DbCommand with results for the specific command, in this case the list of primary keys to delete. As you move to SQL Server 2008, your configuration becomes easier, and your sync-enabled database will simply perform better.
Setting the Hierarchical Order
Once you’ve added the cached tables, the Sync Designer will configure your server and save the creation and undo scripts for inspection and re-execution when moving from development to production. Back in the Configure Data Synchronization dialog box, you’ll see your list of tables. It may not be that important for reference data, but if you intend to send your changes back up to the server, and you want to make sure parent records, (such as the OrderHeader table) are inserted before OrderItems and OrderItems are deleted before OrderHeader rows are deleted, you can use the arrows to shuffle the list of tables sorting the parents above their children. The designer sets the order of SyncAdapters within the DbServerSyncProvider. Clicking OK to finish the Sync Designer configuration will configure the Sync Services runtime, generate the classes for use within your application, and execute the Synchronization method to automatically generate the SQL Server Compact database with the schema and data you’ve selected. As the Sync Designer completes it adds the newly created SQL Server Compact database to your project which triggers Visual Studio to automatically prompt to create a new typed DataSet for your newly added SQL Server Compact data source.
Sync Services, SQL Server Compact and LINQ
Similar to building houses, it’s difficult to build the second floor when the basement is still being completed. Because of the parallel development of LINQ, Sync Services and the Microsoft Sync Framework, Sync Services for ADO.NET 1.0 uses DataSets and DbCommands for its programming APIs. Future releases of Sync Services will be extended to work with the new LINQ programming models.
The Sync Services, Active Caching approach synchronizes data between two or more data sources. The orange box in Figure 3 shows how interacting with the data in SQL Server Compact is completely up to the application developer. SQL Server Compact continues to support the typed dataSets and TableAdapter programming model from Visual Studio 2005 as well as the updateable, scrollable cursor using the SqlCeResultSet. With the new LINQ programming model, developers may use LINQ to SQL or LINQ to Entities. While Visual Studio may auto-prompt to create typed dataSets, this is simply based on providing a consistent experience with what developers may already be used to with Visual Studio 2005. Developers wishing to use LINQ to SQL or LINQ to Entities can simply cancel this dialog and use the appropriate tools to generate classes over tables within their SQL Server Compact database. For more information on LINQ to SQL and LINQ to Entities, see the article, LINQ to Relational Data: Who’s Who? by Elisa Flasko in this issue of CoDe.
Going N-tier with WCF
One of the challenges developers faced in Visual Studio 2005 was how to easily refactor Typed DataSets from two-tier to n-tier architectures. ADO.NET factored DataSets and DataAdapters as separate components allowing the DataAdapters and their associated commands and connections to be hosted on the server. DataSets could be shared on the client and server reusing common business rule validation and schema. However, in Visual Studio 2005, the Typed DataSet Designer didn’t easily enable this scenario. Late in the Visual Studio 2005 cycle we prototyped a number of different solutions which eventually lead to the following design.
In Visual Studio 2008, both typed DataSets and the Sync Designer now support full separation of the client- and server-generated code. Within the Sync Designer, clicking the advanced chevron will expose the n-tier configuration options. Here you can target the client- and server-generated classes to different existing projects within your solution. If you close the dialog and add a new “WCF Service Library” project to your solution you can use the designer to generate your server classes into a WCF service project.
The Sync Designer will not only generate the server provider classes into the WCF project, it will also generate a WCF service contract wrapping the configured server sync provider and its associated interface. At the top of the generated file, a few commented snippets are included for configuring your WCF service. With the classes separated and the WCF service fully configured, you simply need to glue them back together by generating a service and its associated proxy.
Multiple Inheritance and Organic Onions
One of our design goals for Sync Services was to minimize dependencies on external components and leverage other teams building transports, services, and security models. Developers may need to work over Web services, use the more powerful features of WCF, work over REST, use their own custom transports, or serialize data in a customized format. As you can see in Figure 5, we designed Sync Services to work over stateless service models. All that’s needed is a matching service and proxy. With Sync Services 1.0 using DataSets, developers can leverage the out of the box serialization of DataSets, or they can use LINQ to transform DataSets to their own custom payload. Keeping with the food metaphor, they may convert the DataSets to serialized jellybeans. On the client, the developer simply converts the jellybeans back to a Dataset, handing it to the SyncAgent, and they are good to go.
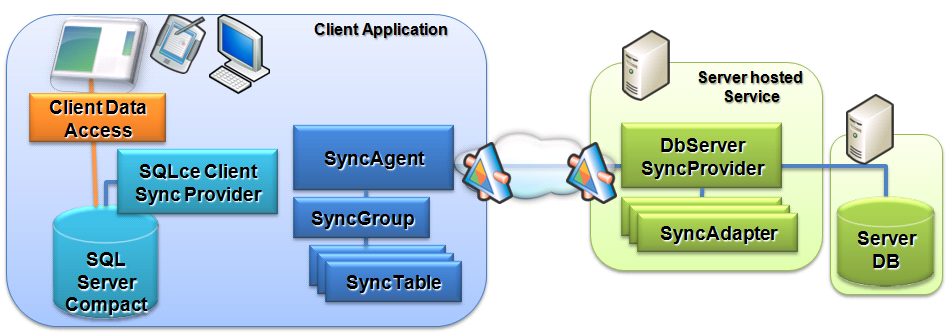
One of the design challenges we faced with enabling transport-agnostic programming was the base class requirements of many components. Web services and WCF proxies require their own base classes. The RemoteProvider on the SyncAgent requires its own base class of a SyncProvider. To get around the multiple inheritance issues we added a wrapper class to Sync Services enabling delegation to the appropriate base class. Since the wrapper class was generic, but wrapped other proxy classes, we initially called it the OrganicOnion class. As we moved into production this was changed to the less creative, but more professionally named ServerSyncProviderProxy class. To glue the SyncAgent back together with the configured ServerSyncProvider in the WCF project, developers can add the code similar to Listing 1 in the partial class of the Sync Designer.
With this configuration, your application can easily work over two-tier architectures, n-tier or service-oriented architectures with minimal impact to your code.
A Quick Recap
In this article I’ve covered why caching data isn’t just about enabling offline functionality and is a common practice in other scenarios such as the food supply chain. Caching can ease your development cycle, enabling decoupled tiers so you can independently update components of your applications, and of course, you’re that much closer to enabling full offline scenarios. By comparing the caching scenarios to other real world issues, and walking through the configuration of Sync Services for ADO.NET using Visual Studio 2008, I’ve hopefully demonstrated the need and productivity gains for caching reference data, tracking deletes, sending updates and simply moving from two tiers to n-tier over WCF. As your applications scale to more complex requirements, Sync Services can be reconfigured to your unique needs. As you need to enable different data sources or support collaborative topologies, your investments in Sync Services can be expanded with the Microsoft Sync Framework. As your companies roll out SQL Server 2008, features like SQL Server Change Tracking and Sync Services for ADO.NET will deliver the best developer experience with the greatest performance for sync-enabled applications.
It’s Not a Matter of If, but When. Are You Ready?
You can always tell the difference between experienced and novice motorcycle riders by the protective gear they wear. As the experienced will tell you, it’s not a matter of if you fall; it’s a matter of when. By building systems that can leverage a local cache, your users, and your business will be protected from the inevitable. With SQL Server Compact, Sync Services for ADO.NET, and the Microsoft Sync Framework you have more productive and powerful tools enabling applications to easily integrate redundancy into your applications. Done right you can reduce the workload to your central services empowering your users to work anytime, anywhere. When they’re connected, things may work better, but when they’re not, they can continue to be productive producing revenue for your company. Although networks and wireless continues to be available in more locations with faster bandwidth, they’re not going to be available everywhere, and if you assume your users won’t have a problem, well, I guess you haven’t fully experienced motorcycle riding.
Listing 1: Extending the Sync Designer, enabling bidirectional synchronization and N’ Tier sync with WCF
Partial Public Class NorthwindCacheSyncAgent
Private Sub OnInitialized()
' Enable Customers to sync with the server
Me.Customers.SyncDirection = _
SyncDirection.Bidirectional
' Glueing the SyncAgent.Remote provider to
' a WCF service proxy
Me.RemoteProvider=New ServerSyncProviderProxy(
New SyncServRef.NWCacheSyncContractClient())
