


In part two of this series on optimizing SQL Server queries I’m going to continue with some T-SQL scenarios that pit one approach versus another. I’ll also look at what SQL developers can do to optimize certain data access scenarios. I’ll also compare approaches with temporary tables versus table variables, and stored procedures versus views.
If you missed part 1 of this article, you can find it in the July/August 2012 issue of CODE Magazine (available online at www.codemag.com, Quick ID: 1208111). The sample files in this article come from the AdventureWorks2008R2 demo database, which you can find on CodePlex.
What’s on the Menu for Part 2?
In part 2 of this series, here are the items I’ll cover:
- SQL Server parameter “sniffing”
- Filtered indexes
- Indexed views (also known as materialized views)
- Union versus Union ALL
- Scenarios where the snapshot isolation level can be helpful
- Scenarios where the “dirty read” isolation level won’t leave you feeling “dirty”
- Another looking at windowing functions
- Differences between table variables and temporary tables
- Using sp_executesql vs EXECUTE when dynamic SQL is necessary
- A performance tip when using T-SQL with SQL Server Integration Services
- A performance tip when inserting a large number of rows inside a loop into a table
- ROW and PAGE index Compression in SQL Server 2008R2 versus ColumnStore Index compression in SQL Server 2012
- Another SSIS tip when using T-SQL
Tip 1: SQL Server Parameter “Sniffing”
A query that might seem optimized during testing might not perform as optimized when parameterized in a stored procedure.
Take a look at the beginning of Listing 1 - I’ve created an index on the PurchaseOrderHeader table, based on the OrderDate index. To test the query, I try to retrieve orders with an order date greater than or equal to 9/5/2008. The execution plan confirms that the optimizer performs an efficient index seek. However, because I didn’t add any type of covering index on the other columns I wished to return, SQL Server also performs a key lookup into the clustered index to retrieve all the other columns.
Then I try to retrieve all orders based on the date of 9/3/2008 (which will return more data). SQL Server elects to discard the index seek and determines that a more brute force index scan is more efficient. So SQL Server (in this example) established a threshold for when to use the combination of an index seek/key lookup versus an index scan.
The situation gets worse - as Listing 1 continues, it executes a stored procedure that receives a number of days as a parameter (@NumberDaysBack), and returns all orders that are within that specific number of days from the most recent order date. Surely if you execute the procedure and pass in a number of days that would be within the threshold of 9/5/2008 (from above), SQL Server would still generate an index seek - correct?
Not quite. Even if you run it for one day (i.e., orders between 10/22/2008 and 10/23/2008) the optimizer uses an index scan. So what is going on? If you look at the statistics (Figure 1), you will see something interesting - even though SQL Server only retrieved one order, the estimated number of rows was 1203! In this situation, SQL Server is anticipating (or “sniffing”) for a much more conservative estimate of the # of rows it will need to retrieve (basically, 30%). This is why developers should always test stored procedures, even if they believe the core queries are optimized.
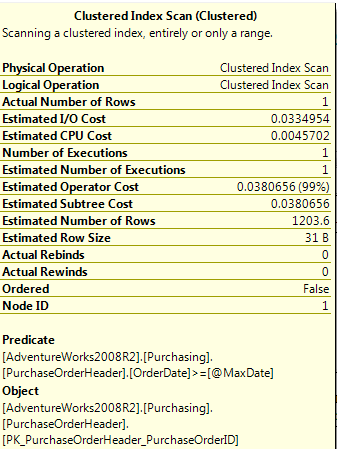
So how can you command SQL Server to optimize this query to handle cases where you have a high degree of selectivity? Listing 1 continues on with an ALTER statement on the query, where you can do one of three things: either OPTIMIZE with an expression for a much greater degree of selectivity, force a statement RECOMPILE, or force the optimizer to use an index seek. NOTE: developers should thoroughly test these scenarios (or place limits in the calling application on parameter values) to make sure these optimizer hints don’t lead to unexpected behavior.
Tip 2: Filtered Indexes
Microsoft implemented a new feature in SQL Server 2008 that has gone under the radar of many people: a filtered index, where you can place a scope expression as a WHERE clause on an index. This will increase performance on queries that frequently retrieve a common key that represents a small portion of the table. Sometimes in a large table, you might need a high level of “seek selectivity” on just a handful of business entities.
Listing 2 shows an example of a filtered index (in this case, a covering index) on Vendor ID 1492 - perhaps this is a very important vendor. A query on that vendor will result in an index seek on the filtered index, whereas a query on other vendors will result in a scan.
NOTE: while not covered in the Listing 2 example, another use for a filtered index would be on a nullable column where the value is not null.
This is somewhat of a “niche” enhancement and won’t be necessary for certain applications. But like the old saying goes, “When you need it, you really need it!”
Tip 3: Indexed/Materialized Views
Suppose you have a view that returns a high number of rows that you frequently execute. You can help performance by creating an indexed view (essentially materializing the results). This can help with performance.
Listing 3 shows an example of an indexed view, whose use might wind up outperforming the original query. The code creates the view with the SCHEMABINDING set - this is required for an indexed view, as you don’t want any underlying DDL changes to occur on the tables that would affect the view. Next, the code creates a clustered index to drive the physical order of the materialized view. It’s now likely that queries into this view (which lists each vendor and the sum of the orders) will be faster than running the query by itself.
Additionally, SQL Server uses indexed views in another scenario - one that is becoming a little more popular in Analysis Services settings. When SSAS developers create ROLAP solutions, any aggregation definitions (in the SSAS project) will ultimately create indexed views back in the relational database source. There are limitations - the SSAS project can only work against tables (not views themselves), and the fact table measures cannot permit NULL values. You can find more information by searching MSDN on the keywords “ROLAP” “aggregations” and “indexed views.”
NOTE: Some of the new features in SQL Server 2012 provide even more potential for better performance. In this instance, the new columnstore index in SQL Server can often outperform a materialized view, in scenarios where a columnstore index is appropriate.
Tip 4: Union versus Union ALL
Years ago I proposed to handle a scenario (of appending transaction rows from five different sources) using a UNION. The reaction was, “I’ve heard UNION is very slow.”
Well, that depends. Yes, a UNION can be very slow, since SQL Server must check for duplicates across all column values. However, a UNION ALL will suppress a duplicate check, and will usually outperform a regular UNION.
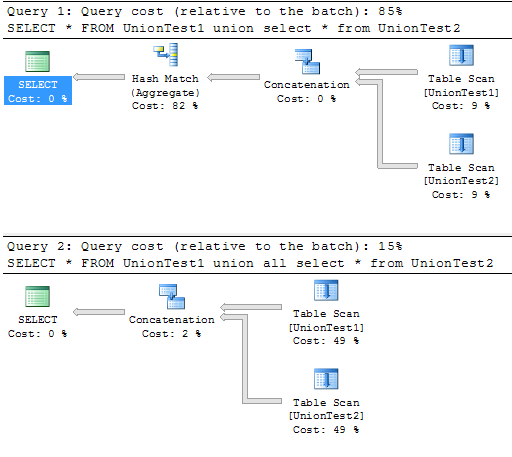
In Listing 4, I create two tables with one million random value rows in each table, and then perform both a UNION and a UNION ALL to create one result set that appends both tables together. Figure 2 shows the cost of the two queries in the batch: the UNION has a cost of 85% of the entire batch, because of the costly hash match (to eliminate any possible duplicates), whereas the UNION ALL has a much lower cost (because there is no check for duplicates).
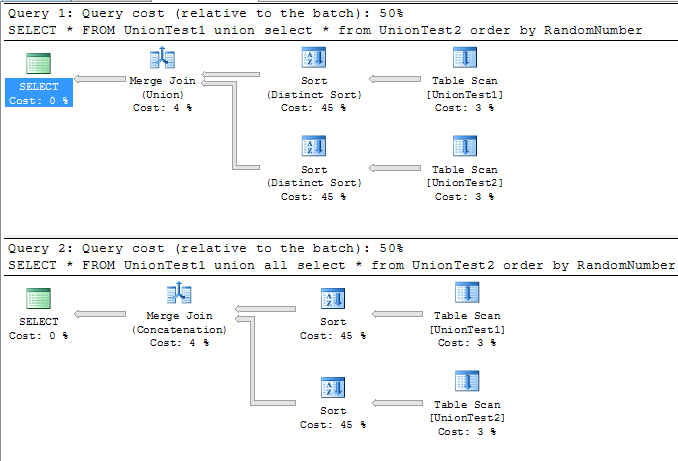
Having said all that, there’s the “800-pound elephant in the room” - the use of an ORDER BY statement. If you place an ORDER BY at the end of both queries, the cost is more 50-50! (see Figure 3). While the UNION must perform a more costly DISTINCT SORT instead of a regular SORT, you lose some of the performance from the first query. A rule of thumb with queries is to only use an ORDER BY at the end if absolutely necessary!
Tip 5: Using the Snapshot Isolation Level
Suppose you’re querying data at the same time inserts/updates/deletes are occurring - a common concurrency scenario.
By default, querying in SQL Server attempts to issue a shared lock (using the isolation level READ COMMITTED). Unfortunately, if write locks have been placed on the data by other transactions, the querying processing must wait until the write locks have cleared.
In a few instances, developers will get around this by using the “dirty read” isolation level, which is potentially fraught with danger. So what’s the alternative - sit and wait?
Fortunately, SQL Server 2005 implemented the snapshot isolation level, and specifically the read committed snapshot. READ COMMITTED SNAPSHOT essentially turns EVERY read committed query (including regular queries that haven’t specified an isolation level) into a dynamic snapshot that reads the last good committed version! It almost sounds too good to be true! Listing 5 walks through a basic scenario:
- Turn on READ COMMITTED SNAPSHOT for the database.
- User A starts a transaction to update a row, but does not yet commit the transaction.
- User B reads from the row. In a dirty read (READ UNCOMMITTED) scenario, the read would pick up the uncommitted value. In a normal READ COMMITED scenario, User B would have to wait for User A’s transaction to finish. But because we’ve essentially turned every READ COMMITTED into a “dynamic snapshot,” User B returns the last good committed version.
- User A performs a COMMIT.
- User B reads the row again-and will see the updated and committed value!
Tip 6: A Use for the Read Uncommitted (Dirty Read) Isolation Level
OK, once in a blue moon (a very blue moon), you might want to simply query to get back raw data - you are not concerned with consistency or “dirty data” - you simply want a result set against data that is frequently being updated - and you want the data as quickly as possible with no read locks.
While generally not advised (unless in an extremely controlled environment), you can do a dirty read. You can do this either by using an isolation level of READ UNCOMMITTED, or by using the WITH (NOLOCK) optimizer hint. Use at your own caution!!!!
SELECT Name as VendorName,
SUM(TotalDue) AS VendorTotal
FROM Purchasing.PurchaseOrderHeader
with (nolock)
JOIN Purchasing.Vendor
with (nolock)
ON VendorID = BusinessEntityID
GROUP BY Name
Tip 7: Using Windowing Functions to Calculate Percent of Totals
Much has been made the last few years about WINDOW functions in SQL Server (i.e., the ability to aggregate “over” a set…or window…of rows).
Listing 6 shows two different methods for doing a SUM “OVER” to implement a % of total. This is becoming more and more a requirement in even basic analytic queries.
The first method uses the “SUM of a SUM” in order to calculate the denominator in a % of total calculation. The second method “pre-aggregates” the sum of order dollars for each vendor, and then sums that number in the denominator in the outer portion of the common table expression.
Tip 8: Differences between Temporary Tables and Table Variables
A common discussion in SQL Server forums is the use of temporary tables versus table variables. Most developers know the general differences between the two; however, there are some subtle differences that make one better than the other in certain contexts. Table 1 “pits” the two together.
General recommendation: For a fairly small list of rows, a table variable is probably better. For a much larger list that you might need to index, a temporary table is often a better choice.
Tip 9: Scenarios for Using Dynamic SQL
A short but important tip if you use dynamic SQL in stored procedures. After you construct a string that contains the SQL query to execute, ALWAYS use EXEC sp_executesql (@SQLString) instead of EXEC (@SQLString). The former provides better protection against dynamic SQL and is more likely to promote query plan reuse.
Tip 10: A Performance Tip when Inserting Rows Inside a Loop
Recently I had to create a large (10 million row) test table. Just like most people, I created a loop and manually inserted rows inside the loop. But after about 10 minutes of what seemed like lackluster performance, I decided to put it inside a transaction, where a single COMMIT would occur at the end.
The result was significant!!!
Listing 7 shows an example that creates 100,000 rows into a test table - with the option of using a BEGIN TRANSACTION and COMMIT TRANSACTION so that SQL Server would buffer the 100,000 rows until the COMMIT took place. Using the transaction approach meant the loop only took 5,150 milliseconds to run, while taking out the transaction approach meant the loop took 36,420 milliseconds to execute. That’s a difference of a factor of almost 7!!!
Tip 11: Using Page/Row Index Compression versus Columnstore Indexing
SQL Server 2008 implemented row and page compression. ROW compression will avoid storing zeros and null values. PAGE compression will compress duplicate values that occur across rows.
-- Use Row compression to avoid storage
-- of zeros and null values
CREATE NONCLUSTERED INDEX IX_Compression_ROW
ON Person.Address (City,PostalCode)
WITH (DATA_COMPRESSION = ROW ) ;
-- Use Page compression when there is
-- a higher level of frequently occuring data
CREATE NONCLUSTERED INDEX IX_Compression_PAGE
ON Person.Address (City,PostalCode)
WITH (DATA_COMPRESSION = PAGE) ;
Once again, the columnstore index in SQL Server 2012 will provide more compression (and better performance) than the Page-level compression.
Tip 12: A Performance Tip when Using T-SQL as an OLE DB Data Source in SQL Server Integration Services
More and more people are using SQL Server Integration Services (SSIS) and that’s a good thing. Having said that, it’s important to be aware of scenarios where SSIS is not as optimized with SQL Server as you would think.
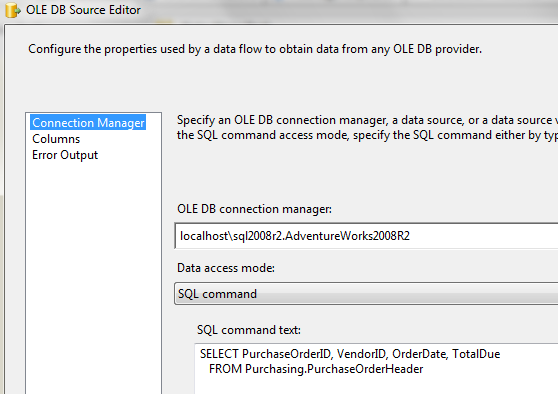
Consider Figure 4 - an OLE DB source where we define a subset list of columns in the interface. After all, we don’t want all the columns in the pipeline, correct? Otherwise, that would be like a SELECT *, correct?
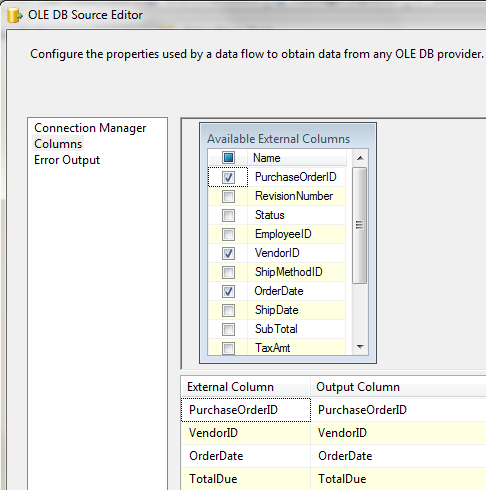
Unfortunately, look at SQL Profiler in Figure 5 - as it turns out, SSIS generated a SELECT * anyway. Ouch!!!

So it’s better to put an in-line statement (Figure 6) - or better yet, write a stored procedure and have SSIS call the procedure!!!!
While I personally love SSIS, I’ve learned over the years to be very careful about relying on the SSIS components for generating T-SQL queries. In most cases, developers are better off writing their own queries (or procedures) and using SSIS as a mechanism to control workflow of SQL (and other) tasks.
While I personally love SSIS, I’ve learned over the years to be very careful about relying on the SSIS components for generating T-SQL queries. In most cases, developers are better off writing their own queries (or procedures) and using SSIS as a mechanism to control workflow of SQL (and other) tasks.
Tip 13: A Performance Tip when Using T-SQL to Update Rows in SQL Server Integration Services
Here is another SSIS performance tip: the SSIS data flow pipeline is a wonderful thing - but be careful about certain operations in the data flow if the number of rows in the pipeline is huge.
Suppose you’re using the SSIS data flow pipeline as a source of a large number of updates? In SSIS, you use the OLE DB command to perform an update (Figure 7). This is perfectly acceptable for a pipeline that isn’t large (i.e., 100,000 rows or less).
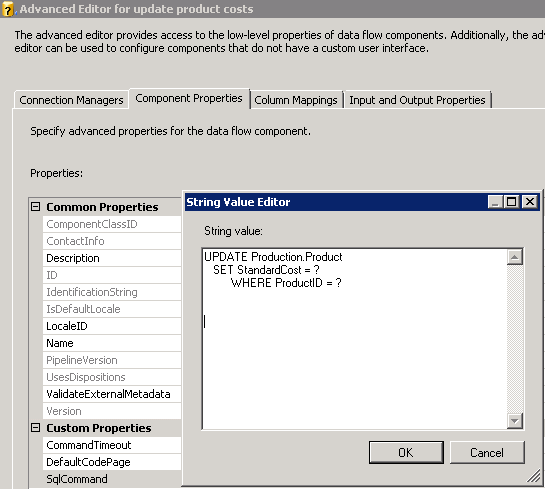
However, the larger the pipeline, the more overhead and more performance issues you’ll have. Just like you want set-based operations in T-SQL for larger operations, you should strive for the same thing in SSIS. Otherwise, you’re using SSIS as a glorified forward-only cursor, which isn’t exactly the most optimized approach.
So what’s the solution? In my Baker’s Dozen article on new features in SSIS 2012 (CODE Magazine, May/June 2012, Quick ID: 1206021), I showed an example of using a staging table to hold updated values, and then using one single UPDATE (or even MERGE statement) at the end.
Next Time in the Baker’s Dozen
In the nearly seven years that I’ve been writing articles for CODE Magazine, I’ve evolved from writing about .NET topics to writing about .NET/Data topics, to writing almost exclusively on data topics. (I often joke that I “crossed over to the dark side.”) Well, the next Baker’s Dozen will represent my biggest jump into “the dark side of data” to date - I’m going to present 13 tips for becoming more productive in data warehousing. This next article will dig a little deeper into theoretical and even abstract concepts, but very important concepts. (And yes, there will be some SQL code to demonstrate these concepts!)
