


Throughout my career, I've been on both sides of the interview table. I've interviewed other developers, either as a hiring manager or as part of an interview team. Of course, I've also sweated through interviews as the applicant. I also taught SQL Server programming for years, coached people preparing for technical interviews, and authored certification and test questions. I'm going to borrow from those experiences in this installment of Baker's Dozen, by giving you a chance to take a test on SQL Server and Transact-SQL topics. In the last issue of CODE Magazine, I started using the Baker's Dozen format to present 13 technical test questions on SQL Server topics, and I think that format will work well for this subject.
Life in Detail as a Technical Mentor
One of my favorite musical artists is Robert Palmer and one my favorite Palmer tracks is called “Life in Detail.” The song contains rapid-fire lyrical messages about reality checks, false conclusions, perspectives, and (painful) discoveries. Those occur in software development as well!
In my consulting business, I mainly serve as a technical database/applications mentor. Some days I write code, some days I lead in design efforts, and often I'm laying out work for others and going over some of the technical hurdles they might face. I have a million shortcomings in life (as friends and co-workers will attest), but one of my strengths is a photographic memory. Nearly every week, I work with developers on database technology topics that remind me of prior blog entries, interview and certification questions, classroom discussions, and webcast talking points that go back many years. In my opinion, one of the keys to success is recalling past issues and even prior mistakes, and how you solved/learned from them.
Often, discussions with other developers help to bridge technology gaps, address misunderstandings about how a specific database feature works, and why a feature might work acceptably in one scenario but not others. In other words, the dirty details and their role in reality checks-are precisely what Robert Palmer was talking about.
A few readers might be going on database technical interviews in the near future. I can't guarantee that any topic I cover in these articles will appear on a technical interview screening (though I suspect a few will). Regardless, the more a person can speak in terms of scenarios on a technical topic, the more likely they'll impress the interviewer.
What's on the Menu?
I'd categorize these 13 questions for intermediate developers. (These are the types of interview questions I'd expect a mid-level database developer to be able to answer). In the first half of this article, I'll cover the test questions, and then in the second half I'll cover the answers. Although this article isn't an interactive software product that requires you to answer before seeing the results, you'll at least have a chance to read the questions and try to answer, if you can avoid peeking to the second half of the article to see the answers!
- Knowing the differences between Materialized Views and Standard Views
- Obtaining the row count of every table in a database
- Determining when subqueries are necessary
- Understanding the use of NOLOCK
- Understanding the SQL Server Isolation Levels
- Understanding the SQL Server Snapshot Isolation levels
- Baker's Dozen Spotlight: Dealing with a long list of columns in a MERGE statement
- Knowing what DISTINCT and GROUP BY accomplish
- Understanding how to use PIVOT
- Generating multiple subtotals
- Capturing queries that other applications are executing
- Handling a dynamic GROUP BY scenario
- Diagnosing performance issues on Linked Servers and Parameterized Queries
Before I begin, I want to mention that references I make to specific SQL Server language features and product versions are for historical context. Some developers might have to support older versions of SQL Server. In this article, I refer to the MERGE and GROUPING SETS enhancements, which Microsoft added in SQL Server 2008. I also talk about the SQL Server Isolation Levels, which Microsoft added in SQL Server 2005. Unless I indicate otherwise, you can assume that any feature I reference from an older release still applies today.
Question 1: Knowing the Differences Between Materialized Views and Standard Views
SQL Server allows developers to create two types of views: materialized and standard. Name as many differences as you can between them, including when you might use materialized views, and which one (generally) performs better.
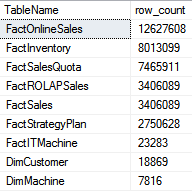
Question 2: Obtaining the Row Count of Every Table in a Database
Suppose you need to generate a result set that contains the row count for every table in a database (see Figure 1 for an example). Some of the tables contain at least hundreds of millions of rows. Your manager told you that your query will run frequently throughout the day. Describe how you'd write a query to accomplish this.
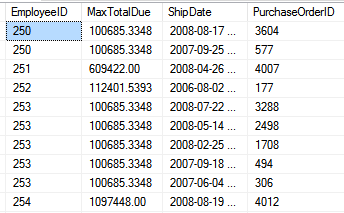
Question 3: Determining When Subqueries are Necessary
Using the AdventureWorks table Purchasing.PurchaseOrderHeader (which contains purchase order rows with columns for the EmployeeID, TotalDue, and ShipDate), you want to produce a result set that shows the highest total due dollar amount for each employee, along with the ship date(s). In the example in Figure 2, note that Employee ID 250 (who could have had thousands of orders) has two orders for a dollar amount of $100,685, one in 2008 and one in 2007. Employee ID 251's highest dollar amount is $609,422 for a purchase order in 2008.
You want to produce a result set that shows each employee, the highest dollar amount for that employee (across all orders for that employee), and the associated ship date(s) and Purchase Order ID(s).
Here's the question: Can you write a query with a single SELECT statement to produce this result set, or would you need to write a subquery (or two queries)?
Question 4: Understanding the Use of NOLOCK
Suppose you execute the following line of code in SQL Management Studio against a SQL Server table.
SELECT * FROM Purchasing.PurchaseOrderHeader
WITH (NOLOCK)
What does the WITH (NOLOCK) accomplish? Are there any pitfalls to using this? (Hint: Even for those who know the basics of this topic, there are some additional nuances of NOLOCK that people often don't talk about).
Question 5: Understanding the SQL Server Isolation Levels
I'll ask two questions relating to SQL Server Isolation Levels in questions 5 and 6.
First, suppose you have a procedure where you want to read a row (or a set of rows), and then lock the rows (so that no one else can update them) and perform multiple operations on the rows in the procedure. What is the least restrictive isolation level that allows you to read rows, such that the read itself locks those rows (and only those rows) for a period of time until I finish my transaction?
Question 6: Understanding the SQL Server Isolation Snapshot Isolation Levels
Here's another question on SQL Server Isolation Levels. In SQL Server 2005, Microsoft implemented the Snapshot isolation level. SQL Server specifically offers two forms of the SNAPSHOT isolation level. What are the names of these two, how do they differ from each other, and how do they differ from other SQL Server transaction isolation levels?
Question 7: Baker's Dozen Spotlight: Dealing with a Long List of Columns in a MERGE Statement
Readers of prior Baker's Dozen articles know that I frequently discuss the T-SQL MERGE statement that allows developers to combine multiple DML operations into one statement. I recommend the MERGE statement in data warehouse scenarios where developers read in a source table that might contain a certain number of rows to insert and update into a target table.
In a moment, you'll look at an example of a MERGE that performs the following:
- It compares the Source table with the Target table based on a composite key lookup (
BzKey1andBzKey2). - For any rows in the Source table that don't exist in the Target table (based on the composite key), it inserts them into the Target table.
- For any rows in the Source table that exist in the Target table (based on the composite key), it updates them in the Target table when at least one non-key column is different between the two tables. Stated another way, if there's a lookup match between the Source table and the Target table based on the composite key, and all of the non-key columns between the two tables are the same, there's no need to perform an update.
- It outputs the insertions and updates into a temp table (recall that the OUTPUT statement allows you to tap into the INSERTED and DELETED system tables that hold the state of insertions and the before/after state of updates).
MERGE TargetTable Targ
USING SourceTable Src
ON Targ.BzKey1 = Src.BzKey1 AND
Targ.BzKey2 = Src.BzKey2
WHEN NOT MATCHED
THEN INSERT (NonKeyCol1, NonKeyCol2)
VALUES (Src.NonKeyCol1, Src.NonKeyCol2)
WHEN MATCHED AND
(Targ.NonKeyCol1 <> Src.NonKeyCol1) OR
(Targ.NonKeyCol2 <> Src.NonKeyCol2)
THEN UPDATE
SET NonKeyCol1 = Src.NonKeyCol1,
NonKeyCol2 = Src.NonKeyCol2
OUTPUT $ACTION , INSERTED.*, OUTPUT.*
INTO #SomeTempTable
OK, now for the question. Suppose you have many tables where you'd like to implement the MERGE. Do you need to re-write a MERGE statement/procedure for each table and spell out each combination of columns? Does the MERGE statement have any type of wildcard feature in any of the statement sections, so that you don't need to list out each column? Is there any way to automate this?
There's no one magic answer to this question.
There's no one magic answer to this question. As an interviewer, I'm simply looking to evaluate a person's thought process, how the person might tackle this question, and whether the person has done it in the past.
Question 8: Knowing What DISTINCT and GROUP BY Accomplish
Suppose you want to summarize the Order dollars in AdventureWorks by VendorID. You can safely assume that NULL values do not exist for the VendorID and TotalDue columns. You want the result set to contain one row per Vendor ID with the summarized order dollars.
I have two questions. First, which of the three queries (A, B, and C) produces the correct results? There could be more than one correct answer. Second, will query A and B produce the same results, regardless of whether or not they are the correct answers?
-- Query A
SELECT VendorID, SUM(TotalDue) as VendorTotal
FROM Purchasing.PurchaseOrderHeader
GROUP BY VendorID
-- Query B
SELECT DISTINCT
VendorID, SUM(TotalDue) as VendorTotal
FROM Purchasing.PurchaseOrderHeader
GROUP BY VendorID
-- Query C
SELECT DISTINCT
VendorID, SUM(TotalDue) as VendorTotal
FROM Purchasing.PurchaseOrderHeader
Question 9: Understanding How to Use PIVOT
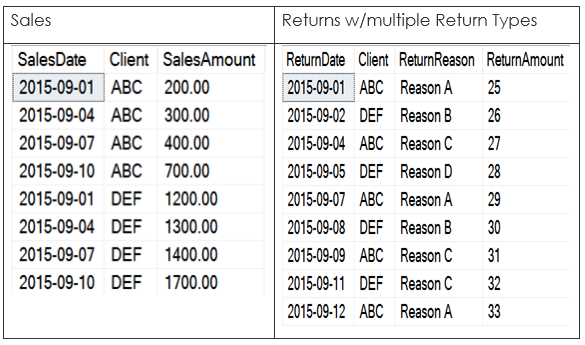
Suppose you have the data in Figure 3. It includes a table of sales data (on the left side of the figure) that includes sales amounts by client on specific days, and another table that lists sales returns by data, client, and a return reason (on the right side of the figure). I realize that most production systems would have a more elaborate table structure; I'm simply using the core necessary elements for this example.
In the end, you'd like to produce a result set that shows the sales by day and all possible Return Reasons as columns, knowing that the Return Reasons are dynamic (as seen in Figure 4).
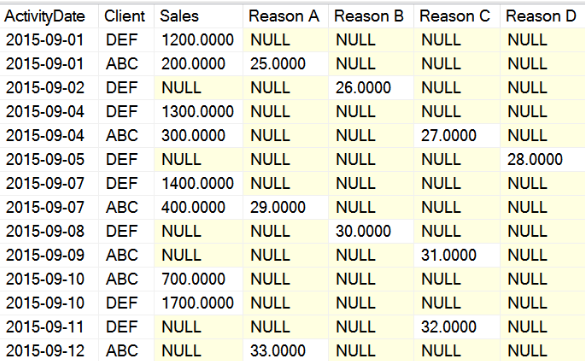
Note that there is nothing particularly “wrong” with the large number of NULL values. In any matrix-like result set of all possible dates and (in this case) sales reasons combinations, you might see a certain number of NULL data points. Analytically, days without any sales or returns might be just as important as days where they occur. (This could hypothetically represent sales for one person.)
How would you write a query to produce these results, in such a way that the query automatically accounts for new Return Reason codes?
Question 10: Generating Multiple Subtotals
Suppose you need to produce a result set with multiple levels of subtotals. Look at the results in Figure 5. The results show the following:
- One row per
Shipper NameandOrder Year, with a summary ofFreightandTotal Duedollars - One row per
Shipper Name, with a summary ofFreightandTotal Duedollars across allOrder Years - One row for the grand summary total of
FreightandTotal Duedollars
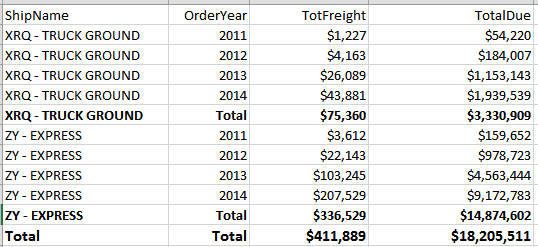
You might ask, “Why should we worry about writing a query to produce all of the subtotals? Isn't that what report writers are for?” In the majority of situations, a developer could use a report writer (such as SQL Server Reporting Services). However, a developer might work in an environment where no one has configured SSRS. Or perhaps the application must output the results to a format that SSRS doesn't support. Or maybe the application requires a smaller footprint/lower overhead than SSRS.
Assume that for this situation, you're not using a report writer or other tool available to summarize results, so you must generate a result set with the necessary totals.
Question 11: Capturing Queries Run by Other Applications
Suppose you have a third party application that accesses your SQL Server databases. The application appears to be performing poorly and is taking a long time to lock and query your data. You don't have the source code, and the vendor isn't being cooperative. You want to be able to prove that the vendor's code needs optimizations. How can you determine the queries that the application is generating?
Question 12: Handling a Variable GROUP BY Scenario
For this question, let's look at the orders in the AdventureWorks Purchasing.PurchaseOrderHeadertable. Suppose you want to retrieve orders and summarize the TotalDue dollar amount by year. Because the table contains both a ship date and an order date, you want to pass a parameter to the query to summarize either by Ship Year or by Order Year.
The results look like Figure 6 if you summarize by Order Year and Figure 7 if you summarize by Ship Year. You can generically refer to the appropriate year column as Order Year.
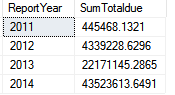
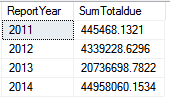
The query should summarize based on the parameter. Here's the question: Based on the parameter you pass to the query (for which date to use), do you need to use dynamic SQL to generate the SELECT and the GROUP BY?
Question 13: Diagnosing Performance Issues on Linked Servers and Parameterized Queries
I'll admit that this last question might seem esoteric to some developers, but those who access other database systems (such as Oracle, IBM DB2, etc.) using Linked Servers might appreciate the value of this question.
Suppose you use a Linked Server in SQL Server to access Oracle tables. In this example, the Linked Server is OracleLinkedServer, the table you want to query is OracleDB.OrderTable, and the business Key is the OrderNumber. You use each of the following three queries (A, B, and C) to return the row for OrderNumber 12345:
-- Query A (uses OpenQuery):
SELECT * FROM OPENQUERY(
OracleLinkedServer, '
SELECT * FROM OracleDB.OrderTable
WHERE OrderNumber = ''12345'' ')
-- Query B (uses four-part notation):
SELECT * FROM
OracleLinkedServer..OracleDB.OrderTable
WHERE OrderNumber = '12345'
-- Query C (uses four-part notation
-- with parameter)
DECLARE @OrderNumber varchar(5) = '12345'
SELECT * FROM
OracleLinkedServer..OracleDB.OrderTable
WHERE OrderNumber = @OrderNumber
Query A uses the OpenQuery function in SQL Server to access the Linked Server and pass a query string to retrieve the order row. Query B avoids the OpenQuery call by using the four-part naming convention to access the Linked Server. Query C is similar to Query B, except that Query C uses a parameter for the Order Number, instead of hardwiring the order number value.
In this example, assume that the OrderTable contains a very large number of rows.
You execute all three queries. Query A runs instantly, whereas Queries B and C are much slower. Why do you think Query A – and OPENQUERY – is so much faster? If your answer is “Because OPENQUERY runs faster,” then the question is: “Why?”
The Answer Sheet
OK, here are the answers. Let's see how you did.
Answer 1: Knowing the Differences Between Materialized Views and Standard Views
Here are the main points.
- A regular view is essentially a stored query. If you run a view 10 times, SQL Server executes the query that you defined in the view. SQL Server doesn't permanently store the results of the view. Subsequent executions might benefit from caching, but SQL Server must still query the source tables every time.
- A materialized view is also a query, but one where SQL Server stores the results. Usually this means a materialized view performs better than a regular view.
- You can create indexes on materialized views to further improve performance.
Let's take a look at an example. I'll use the Microsoft ContosoRetailDW test database, which contains tables with millions of rows. Suppose I want to create a simple view that joins two tables and summarizes sales by promotion. I can do it like this:
CREATE VIEW dbo.RegularView as
SELECT PromotionLabel, PromotionName,
SUM(TotalCost) as TotCost
FROM FactSales
JOIN DimPromotion
ON FactSales.PromotionKey =
DimPromotion.PromotionKey
GROUP BY PromotionLabel, PromotionName
Now I'll execute that view, and return the promotions that have a cumulative aggregated sale amount of $100 million. I'll also look at the Time and IO Statistics as well as the execution plan (Figure 8).
SET STATISTICS TIME ON
SET STATISTICS IO ON
SELECT * FROM dbo.RegularView
WHERE TotCost > 100000000
Table 'DimPromotion'.
Scan count 0, logical reads 56
Table 'FactSales'.
Scan count 5, logical reads 37,230
SQL Server Execution Times:
CPU time = 2266 ms, elapsed time = 641 ms.

Note the execution times in the statistics, as well as the execution plan. Although this view doesn't contain a large number of JOIN statements and the statistics don't represent a five-alarm emergency, let's now take a look at what you can accomplish with a materialized view.
create view dbo.Materializedview
(PromotionLabel, PromotionName, NumRows,TotCost)
with schemabinding
as
select PromotionLabel, PromotionName,
COUNT_BIG(*) AS NumRows,
SUM(TotalCost) as TotCost
FROM dbo.FactSales
JOIN dbo.DimPromotion
ON FactSales.PromotionKey =
DimPromotion.PromotionKey
GROUP BY PromotionLabel, PromotionName
GO
create unique clustered index IX_Temp on
dbo.Materializedview (PromotionLabel)
Note three things I've done here in the materialized view:
- First, although I've created a second view here with a different name, I referenced all the columns at the top, and added the keywords WITH SCHEMABINDING. This tells SQL Server to “materialize” the storage for this structure.
- Second, at the end, I've created a clustered index on the key field of the view (the Promotion Label). SQL Server permits us to create clustered indexes on materialized views for performance.
- Third, I've added a column using the aggregate function
COUNT_BIG(). SQL Server indexed views with aggregations (the sum ofTotalCostin the query) requireCOUNT_BIG. This helps SQL Server internally optimize certain operations on the original table.
Now let's test the view:
SELECT * FROM dbo.Materializedview
-- NOEXPAND forces SQL to use materialized
-- view
WITH (NOEXPAND)
WHERE TotCost > 100000000
Table 'Materializedview'.Scan count 1, logical reads 2
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Because SQL Server materialized (generated and stored) the results, you can see in Figure 9 that the cost is nothing more than a clustered index scan against the materialized view. SQL Server automatically keeps the materialized/indexed view in sync with the underlying physical tables, and automatically “pre-computes” any expensive joins and aggregations that a regular view needs to handle on the fly every time. For reporting and data warehouse/business intelligence applications, this increase in performance is significant.

There's one more item to discuss. Note that I used WITH (NOEXPAND) after I specified the materialized view in the query. This is a query hint to force SQL Server to use the indexed view. This is necessary because SQL Server, by default, expands view definitions until the database engine reaches the base tables. You want SQL Server to treat the view like a standard table with the clustered index you created. Using the NOEXPAND query hint gives you that guarantee. Microsoft covers this topic in an outstanding MSDN article: https://msdn.microsoft.com/en-us/library/dd171921(SQL.100).aspx.
Answer 2: Obtaining the Row Count of Every Table in a Database
There's one answer that's not optimal in large databases and that's using the COUNT() function. COUNT() is expensive on tables with large rows. Fortunately, there's a better way. SQL Server provides a series of dynamic management views (DMVs) that can provide us with row count information. The query below uses the SQL DMV called sys.dm_db_partition_stats to return the row count for each table partition. Regardless of whether the primary partition on a table contains one row or a billion rows, the DMVs return the information almost instantly.
SELECT SysObjects.name as TableName,
PartStats.row_count
FROM sys.indexes AS SysIndexes
JOIN sys.objects AS SysObjects ON
SysIndexes.OBJECT_ID = SysObjects.OBJECT_ID
JOIN sys.dm_db_partition_stats AS PartStats ON
SysIndexes.OBJECT_ID = PartStats.OBJECT_ID
AND SysIndexes.index_id = PartStats.index_id
WHERE SysIndexes.index_id < 2 AND
SysObjects.is_ms_shipped = 0 ORDER BY row_count DESC
Knowing to use DMVs instead of the COUNT() function to determine row count is one of several ways to determine whether a developer has worked with large databases.
Knowing to use Dynamic Management Views (DMVs) instead of the
COUNT()function to determine row count is one of several ways to determine whether a developer has worked with large databases.
There is one caveat here: Because of how the SQL Server DMVs determine row counts, the results might represent an approximation. Stated differently, at any one single point in time, the DMVs might return a slightly different count than the COUNT() function. But if you're trying to determine row counts on very large tables where SELECT COUNT(*) introduces performance issues, the tradeoff of DMV performance is probably well worth it.
Amswer 3: Determining When Subqueries are Necessary
I've written in the past about identifying patterns where subqueries are necessary. One such pattern is when you're aggregating across multiple one-to-many relationships. Another pattern is the one I've introduced in the question.
You want to produce a result set that shows each employee, the highest dollar amount for that employee (across all orders for that employee), and the associated ship date(s) and Purchase Order ID(s).
At the risk of turning this into a sentence-diagramming exercise, let's parse out some key points here. You want the highest dollar amount for each employee. You can easily do that with a simple SELECT, a MAX on the dollar amount for any one order, and a GROUP BY on employee. You also want to show other non-key fields associated with the order that represented the highest dollar amount. In other words, show each employee, the highest dollar amount for an order, and “oh yeah, by the way, show some other columns related to that highest order, like the ship date.” It's that last bit for which you need a subquery.
In layman's terms, you need to aggregate (find the maximum) the dollar amount by employee ID, and define that as a temporary table, or subquery, or common table expression. Then you need to take that temporary result and join it “back” into the original table, based on a match of the employee ID and the maximum dollar amount. Once you join back to the original table, you can pull any other columns associated with that highest order by employee. You simply cannot do this as one query:
;WITH MaxShipCTE as
(select EmployeeID,
MAX(Totaldue) as MaxTotalDue
FROM Purchasing.PurchaseOrderHeader
GROUP BY EmployeeID)
select MaxShipCTE.*, ShipDate ,PurchaseOrderID
from MaxShipCTE
JOIN Purchasing.PurchaseOrderHeader POH
ON POH.EmployeeID = MaxShipCTE.EmployeeID
AND
POH.Totaldue = MaxShipCTE.MaxTotalDue
ORDER BY EmployeeID, ShipDate desc
I've seen code that tries to do this as one query. Of course, SQL Server generates an error because you must include any non-aggregate columns in the GROUP BY. Then, if someone decides to include the ShipDate and PurchaseOrderID columns in the output, the level of granularity in the aggregate is no longer only by Employee, but also by the Employee, Date, and PurchaseOrder ID. You must use a subquery!
-- Incorrect, because we need to GROUP BY
-- on all non-aggregated columns
select EmployeeID, ShipDate, PurchaseOrderID,
MAX(Totaldue) as MaxTotalDue
FROM Purchasing.PurchaseOrderHeader
GROUP BY EmployeeID
Answer 4: Understanding the Use of NOLOCK
Suppose you need to run a query that joins two tables (an order header and an order detail table). The query must read across a substantial number of rows and will take several seconds or longer. During that time, when the query executes, by default, SQL Server places a shared lock on the rows. As a result, you can potentially run into two issues.
First, no SQL Server process can physically update those rows while the query is reading the rows. This is because the shared lock prevents an update (write) lock from executing until the query finishes reading the rows. Depending on organizational workflow, this can cause problems if users need to frequently update rows where other processes are performing lengthy queries. Second, if a lengthy UPDATE first occurs, SQL Server places a write lock on those rows. As a result, any lengthy SELECT that places a shared lock can't execute while the UPDATE is running. In other words, if the shared lock occurs first, the write lock can't execute until the shared lock releases. Conversely, if the write lock occurs first, the shared lock can't execute until the write lock releases.
Now the question becomes: Can you somehow run the query in such a way that SQL Server doesn't place any shared read locks on the rows? The answer is yes, by using NOLOCK. You can place the syntax WITH (NOLOCK) after each table, and SQL Server won't place a shared lock on the rows. Is the problem solved then? Well, yes and no. Although NOLOCK eliminates the need for users to wait for locks to clear, it introduces a new problem. If other processes execute multiple-table UPDATE transactions, that lengthy SELECT WITH (NOLOCK) might wind up reading data in the middle of a transaction. In other words, it's a “dirty read.” This is precisely why DBAs call NOLOCK a dirty read:-because you're reading UNCOMMITTED data.
Some environments discourage the use of NOLOCK, because reading uncommitted data-can potentially generate an incomplete set of results, especially if a dirty read occurred while transactions were still executing. Other environments recognize this but still use NOLOCK when they only expect result sets to reflect an approximation of the data. Although developers sometimes use NOLOCK for expediency, they need to be aware that the results might not be 100% accurate.
There is one other downside about NOLOCK, beyond the generally recognized problem of picking up uncommitted data or incomplete multiple-table transactions. If you execute a query WITH NOLOCK while other simultaneous INSERT/UPDATE operations cause database page splits, it's conceivable that the query will either miss/skip rows entirely, or it might count rows twice. If you want to read more about this, do a Web search on “SQL Server,” “NOLOCK,” and “PAGE SPLIT,” and also the keywords “INDEX ORDER SCAN” and “ALLOCATION ORDER SCAN.” You'll find several online articles that cover this situation.
There are multiple scenarios where WITH NOLOCK's benefit of avoiding lockout situations comes at a price of inaccuracy. Again, developers looking for a quick solution and who are only concerned with an approximation of results might still be satisfied with the results of NOLOCK. But as you'll see in Question 6, Microsoft implemented a new transaction isolation level in SQL Server 2005 (snapshots) that reduces the need for NOLOCK.
Answer 5: Understanding the SQL Server Isolation Levels
The answer to what transaction isolation level specifically allows you to read rows and keep them locked until your transaction is finished is the REPEATABLE READ isolation level.
For an explanation of REPEATABLE READ, imagine that I need to read the value of a single row and keep it locked so that no other process will modify the row. After I obtain this lock, I might need to run a few processes and then update the row, knowing that no one touched it in between.
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
BEGIN TRANSACTION
SELECT * FROM Purchasing.Vendor
WHERE BusinessEntityID = 1464
-- With a REPEATABLE READ LOCK, no one
-- can UPDATE this row until I finish
-- the transaction
-- Perform other processes
UPDATE Purchasing.Vendor
SET SomeColumn = 'NEW VALUE'
END TRANSACTION -- lock is released
Note: Some might have responded with SERIALIZABLE. Although both REPEATABLE READ and SERIALIZABLE address the situation, the question specifically asked which of the least restrictive isolation levels addresses the scenario. REPEATABLE READ is a little less restrictive.
Answer 6: Understanding the SQL Server Isolation Snapshot Isolation Levels
Microsoft introduced the Snapshot isolation level in SQL Server 2005. The Snapshot isolation level comes in two flavors: a regular (or as some people would say, “static”) snapshot, and a more actve snapshot that essentially turns every query that uses the default READ COMMITTED isolation level into a dynamic snapshot.
The Snapshot isolation level addresses the problem back in Question 4. The problem in Question 4 is that NOLOCK prevents lockout conditions but raises the possibility of reading dirty, uncommitted data. Avoiding NOLOCK (i.e., using the default READ COMMITTED isolation level or even any higher level) means the possibility of delays or lockout conditions.
The Snapshot isolation Level avoids both problems by reading the last “good” (i.e., committed) row version from TempDB. You can turn on the Snapshot isolation level by configuring the database to manage snapshots (i.e., rowversions in TempDB):
ALTER DATABASE AdventureWorks2014
SET ALLOW_SNAPSHOT_ISOLATION ON
Once you've configured a database to use the regular Snapshot isolation level, you can use the isolation level as part of any stored procedure. If you need to read data that another process is updating, SQL Server neither forces you to wait, nor returns uncommitted data. Instead, SQL Server returns the last good committed version. This is major functionality that continues (to this day) to reduce the headaches of many database developers.
SET TRANSACTION ISOLATION LEVEL SNAPSHOT
BEGIN TRAN
SELECT * FROM someTable
-- will return rows from last good
-- committed version,
-- without locking out and without returning
-- uncommitted data
Using this posed two challenges. First, it meant that developers needed to add references to the Snapshot isolation Level in every procedure. Second, and more specific to the behavior, any “snapshot” was basically static. In other words, in the example above, if someone updated/committed to the table after you read from the table, any subsequent read that you perform in the transaction still uses the “old” snapshot. Some might view this as good, and some might want any subsequent read to reflect any committed changes from the last few seconds.
Microsoft added a second flavor of snapshots; in my opinion, this is one of the most powerfully elegant features of SQL Server. You can enable READ_COMMITTED_SNAPSHOT in the database, and it automatically turns EVERY SINGLE Read Committed operation (either explicitly or implicitly) into a dynamic snapshot!
ALTER DATABASE AdventureWorks2014
set read_committed_snapshot on
GO
Answer 7: Baker's Dozen Spotlight: Dealing with a Long List of Columns in a MERGE Statement
Unfortunately, there's no way to specify all columns in an INSERT or UPDATE clause with any kind of asterisk or other wild-card character. However, some developers create a utility or function that generates a long string of MERGE syntax by reading from a data dictionary or even the sys.tables and sys.columns system tables.
Imagine that you had a Target Product table and an Incoming Product table from some ETL load operation. Now imagine that you had twenty different tables following that pattern: Each has a target table and a mirror incoming table. You could call a function and pass the names of the tables, and the function could generate some or all of the MERGE syntax for you. It might not be perfect, but it's still far better than writing out all the MERGE code by hand! For instance, take a look at the following:
CREATE TABLE dbo.TargetProduct
(ProductPK int identity,
ProductBzKey varchar(20),
ProductName varchar(20),
ProductPrice money)
CREATE TABLE dbo.IncomingProduct
(ProductBzKey varchar(20),
ProductName varchar(20),
ProductPrice money)
SELECT [dbo].[tvfGenerateSQLMerge]
('dbo.TargetProduct',
'dbo.IncomingProduct', 'ProductBzKey')
The function dbo.tvfGenerateSQLMerge takes the two input table definitions and the definition for the business key and generates the entire string. The function generates the syntax for the MERGE that you'd otherwise to have write by hand!. Listing 1 shows the entire function and Listing 2 shows an example of the results.
Listing 1: A reusable function to generate a MERGE
CREATE function [dbo].[tvfGenerateSQLMerge]
(@TargetTable varchar(max) , @InputTable varchar(max),
@BzKeyColumn varchar(max) )
RETURNS varchar(max)
as
begin
DECLARE @SchemaName varchar(100) =
(select substring(@TargetTable,1,
charindex('.',@TargetTable)-1))
DECLARE @CoreTableName varchar(100) =
(SELECT REPLACE(@TargetTable,@SchemaName + '.',''))
DECLARE @ColumnList TABLE (ColumnName varchar(100))
INSERT INTO @ColumnList
SELECT Columns.name from
sys.columns columns
join sys.types types on
columns.user_type_id = types.user_type_id
where is_identity = 0
AND OBJECT_ID =
(SELECT tables.OBJECT_ID FROM sys.Tables tables
join sys.schemas schemas
on tables.schema_id = schemas.schema_id
where tables.Name = @CoreTableName and
schemas.name = @SchemaName)
declare @crlf varchar(max) = char(13) + char(10)
declare @UpdateSyntax varchar(max) =
(select (stuff ((SELECT ', ' + ColumnName + ' = Src.' +
ColumnName FROM @ColumnList
WHERE ColumnName <> @BzKeyColumn
for xml path ('')), 1, 1, '') ) )
declare @SourceFieldList varchar(max) = '(' +
(select (stuff ((SELECT ',' + ColumnName FROM
@ColumnList for xml path ('')), 1, 1, '') ) ) + ')'
declare @CheckForUpdateSyntax varchar(max) =
(select replace( replace(
(select ( (SELECT 'Src.' + ColumnName + ' <> Targ.' +
ColumnName + ' OR ' FROM @ColumnList
WHERE ColumnName <> @BzKeyColumn
for xml path ('')) ) ) ,
'<' , '<'),
'>' , '>') )
set @CheckForUpdateSyntax = '(' +
substring(@CheckForUpdateSyntax , 1,
len(@CheckForUpdateSyntax)-3) + ')'
DECLARE @MergeSyntax varchar(max) = ' MERGE ' +
@TargetTable + ' Targ' + @crlf
SET @MergeSyntax = @MergeSyntax + ' USING ' +
@InputTable + ' Src ON Targ.' +
@BzKeyColumn + ' = Src.' + @BzKeyColumn + @crlf
SET @MergeSyntax = @MergeSyntax +
'WHEN NOT MATCHED ' + @crlf +
' THEN INSERT ' + @crlf +
' ' + @SourceFieldList + @crlf
SET @MergeSyntax = @MergeSyntax + ' VALUES ' +
@SourceFieldList + @crlf
SET @MergeSyntax = @MergeSyntax + ' WHEN MATCHED ' +
@crlf + ' AND ' + @CheckForUpdateSyntax + @CRLF
SET @MergeSyntax = @MergeSyntax +
' THEN UPDATE SET ' + @UpdateSyntax + @crlf
SET @MergeSyntax = @MergeSyntax + @crlf + ' OUTPUT $Action; '
return @MergeSyntax
end
Listing 2: Result for a MERGE
MERGE dbo.TargetProduct Targ
USING dbo.IncomingProduct Src
ON Targ.ProductBzKey = Src.ProductBzKey
WHEN NOT MATCHED
THEN INSERT
(ProductBzKey,ProductName,ProductPrice)
VALUES (ProductBzKey,ProductName,ProductPrice)
WHEN MATCHED
AND (Src.ProductName <> Targ.ProductName OR
Src.ProductPrice <> Targ.ProductPrice)
THEN UPDATE SET ProductName = Src.ProductName,
ProductPrice = Src.ProductPrice
OUTPUT $Action;
Answer 8: Knowing What DISTINCT and GROUP BY Accomplish
The answer is both A and B. Both queries generate the correct results. Query C fails because the SELECT contains an aggregation and a non-aggregated column, but no GROUP BY on the non-aggregated column.
Note that Query B contains a DISTINCT. As it turns out, the DISTINCT is not necessary because the GROUP BY accomplishes the same thing and more, since the GROUP BY also allows you to aggregate. Some developers use DISTINCT in addition to a GROUP BY. In almost all cases, the DISTINCT isn't needed.
Answer 9: Understanding How to Use PIVOT
Before I get into the SQL end, some might reply that you could use the dynamic pivot/matrix capability in SSRS. You simply combine the two result sets by one column and then feed the results to the SSRS matrix control, which spreads the return reasons across the column axis of the report. However, not everyone uses SSRS (although most people should!). Even then, sometimes developers need to consume result sets in something other than a reporting tool. For this example, let's assume that you want to generate the result set for a Web grid page. You need to generate the output directly from a stored procedure.
As an added twist; next week there could be Return Reasons X and Y and Z. You don't know how many return reasons there could be at any point in time. You simply want the query to pivot on the possible distinct values for Return Reason. Here is where the T-SQL PIVOT has a restriction: You need to provide the possible values. Because you won't know that until run-time, you need to generate the query string dynamically using the dynamic SQL pattern. The dynamic SQL pattern involves generating the syntax, piece by piece, storing it in a string, and then executing the string at the end using a SQL Server system procedure. Dynamic SQL can be tricky, as you have to embed syntax inside a string. In this case, it's your only true option if you want to handle a variable number of return reasons.
I've always found that the best way to create a dynamic SQL solution is to determine what the “ideal” query would be at the end (in this case, given the Return Reasons you know about). After you establish the ideal query, you can then reverse-engineer it and build it using Dynamic SQL. When implementing a dynamic SQL solution, always write out the model for the query you want to programmatically construct.
When implementing a dynamic SQL solution, always write out the model for the query you want to programmatically construct.
And so, here is the SQL you need, if you knew those Return Reasons (A through D) were static and wouldn't change. You can find the query in Listing 3, which does the following:
- Combines the data from SalesData with the data from ReturnData, where you hard-wire the word Sales as an Action Type from the Sales Table, and then use the Return Reason from the Return Data into the same
ActionTypecolumn. That gives you a cleanActionTypecolumn on which to pivot. You're combining the two SELECT statements into a common table expression (CTE), which is basically a derived table subquery that you subsequently use in the next statement (to PIVOT). - Uses a PIVOT statement against the CTE that sums the dollars for the Action Type in one of the possible Action Type values.
Listing 3: Example of PIVOT that we want to generate (final result)
;WITH TempResultCTE AS
(SELECT SalesDate AS ActivityDate, Client,
'Sales' AS ActionType, SalesAmount AS Dollars
FROM dbo.SalesData
UNION ALL
SELECT ReturnData.ReturnDate AS ActivityDate, Client,
ReturnReason AS ActionType, ReturnAmount AS Dollars
from dbo.ReturnData)
SELECT ActivityDate, Client, [Sales],
[Reason A], [Reason B], [Reason C], [Reason D]
FROM TempResultCTE
PIVOT (SUM(Dollars) FOR ActionType IN
( [Sales],
[Reason A],[Reason B],[Reason C], [Reason D]) )
TEMPLIST
If you knew with certainty that you'd never have more return reason codes, Listing 3 is the solution. However, you need to account for other reason codes. You need to generate that entire query in Listing 3 dynamically as one big string - right where you construct the possible return reasons as one comma-separated list.
Listing 4 shows the entire T-SQL code necessary to generate (and execute) the desired query. There are three major steps in constructing the query dynamically.
Listing 4: SQL procedure to generate the PIVOT dynamically
DECLARE @ActionSelectString nvarchar(4000) ,
@SQLPivotQuery nvarchar(4000)
-- Step 1, Generate the list of columns by doing a SELECT DISTINCT
-- on the reason codes, and then using the STUFF and FOR XML PATH
-- technique to build a comma separated list
;WITH ListTempCTE as
(SELECT 'SalesAmount' AS ActionType , 1 as OrderNum
UNION
SELECT DISTINCT ReturnReason as Actiontype,
2 as OrderNum FROM ReturnData )
SELECT @ActionSelectString =
stuff ( ( select ',[' +
cast(ActionType as varchar(100)) + ']'
from ListTempCTE
ORDER BY OrderNum, ActionType
for xml path('') ), 1, 1, '')
-- End of step 1
-- this dynamically yields [SalesAmount],[Reason A],
-- [Reason B],[Reason C],[Reason D] in @ActionSelectString
-- Step 2 Now that we've built the necessary select strings
-- as variables, we'll start generating the core query. Here's
-- where we the original model is so critical
-- Start by generating the original CTE
DECLARE @CRLF VARCHAR(10) = CHAR(13) + CHAR(10)
SET @SQLPivotQuery = ';WITH TempResultCTE as
(select SalesDate as ActivityDate, Client,
''Sales'' as ActionType, SalesAmount as Dollars
FROM dbo.SalesData ' + @CRLF +
'UNION ' + @CRLF +
' SELECT ReturnDate as ActivityDate, Client,
ReturnReason as ActionType, ReturnAmount
from dbo.ReturnData) ' + @CRLF + @CRLF
-- Step 3, continue by concatenating with the action string
set @SQLPivotQuery = @SqlPivotQuery +
' SELECT ActivityDate, Client, ' + @ActionSelectString
+ ' FROM TempResultCTE ' + @CRLF +
' PIVOT ( SUM(Dollars) for ActionType in ('
+ @ActionSelectString + ')) TEMPLIST '
+ @CRLF + @CRLF
EXEC sp_executesql @SqlPivotQuery
The first step is that you need to generate a string for the columns in the SELECT statement (for example, [SalesAmount], [Reason A], [Reason B], [Reason C], [Reason D]).
You can build a temporary common table expression that combines the hard-wired “Sales Amount” column with the unique list of possible reason codes (using a SELECT DISTINCT). Once you have that in a CTE, you can use the nice little trick of FOR XML PATH('') to collapse those rows into a single string, put a comma in front of each row that the query reads, and then use STUFF function to replace the first instance of a comma with an empty space. This is a trick that you can find in hundreds of SQL blogs. This first part builds a string called @ActionSelectString that you can use further down in the SELECT portion of the query.
The second step is where you begin to construct the core SELECT. Using that original query as a model, you want to generate the original query (starting with the UNION of the two tables), but by replacing any references to pivoted columns with the string (@ActionSelectString) that you dynamically generated above. Also, although not absolutely required, I've also created a variable to simply any carriage return/line feed combinations that you want to embed into the generated query (for readability). You'll construct the entire query into a variable called @SQLPivotQuery.
In the third step, you continue constructing the query by adding the syntax for PIVOT. Again, concatenating the syntax, you can hard-wire with the @ActionSelectString (that you generated dynamically to hold all the possible return reason values).
After you generate the full query string, you can execute it using the system stored procedure sp_executesql.
To recap, the general process for this type of effort is:
- Determine the final query based on your current set of data and values (i.e., build a query model).
- Write the necessary T-SQL code to generate that query model as a string.
- Determine the unique set of values on which you'll PIVOT, and then collapse them into one string using the
STUFFfunction and theFOR XML PATH('')trick. This is arguably the most important part.
Answer 10: Generating Multiple Subtotals
Those who have read prior Baker's Dozen articles know that I've stressed the value of GROUPING SETS, which Microsoft introduced in SQL Server 2008. GROUPING SETS allows developers to define multiple sets of GROUP BY definitions (thus the name). Although report writers reduce the need to generate multiple levels of subtotals in a result set, not all queries are consumed by report writers. Listing 5 shows an example of GROUPING SETS.
Listing 5: Example of GROUPING SETS
SELECT CASE WHEN GROUPING(SM.Name)=1 THEN 'Total'
else SM.Name End
as ShipName,
CASE WHEN GROUPING(Year(OrderDate))=1 THEN 'Total'
else CAST(YEAR(OrderDate) AS VARCHAR(4)) end
as OrderYear,
SUM(Freight) as TotFreight, SUM(TotalDue) as TotalDue
FROM Purchasing.ShipMethod SM
JOIN Purchasing.PurchaseOrderHeader POH
ON SM.ShipMethodID = POH.ShipMethodID
where SM.ShipMethodID in (1,2)
GROUP BY GROUPING SETS
(
(SM.Name, YEAR(OrderDate)),
(sm.name), ()
)
Answer 11: Capturing Queries Run by Other Applications
I've asked this question many times in technical interviews, and I've always looked for a two-word answer: SQL Profiler. SQL Profiler is a management tool that comes with SQL Server. It allows you to define a trace against a database, and to view all queries and stored procedure execution references that hit a particular database. I've found it to be very helpful on many occasions!
SQL Profiler is extremely valuable when trying to determine specific query syntax that's hitting the database.
Answer 12: Handling a Variable GROUP BY Scenario
Some developers might conclude that dynamic SQL is necessary to account for the variable nature of the GROUP BY. As it turns out, you can specify a CASE statement in the GROUP BY definition! Take a look at the following code snippet, which uses a CASE statement in the GROUP BY to aggregate by the selected option.
DECLARE @DateOption int = 1
SELECT CASE WHEN @DateOption = 1
THEN YEAR(OrderDate)
ELSE YEAR(ShipDate)
END as ReportYear,
SUM(Totaldue) as SumTotaldue
FROM Purchasing.PurchaseOrderHeader
GROUP BY
CASE WHEN @DateOption = 1
THEN YEAR(OrderDate)
ELSE YEAR(ShipDate) END
ORDER BY ReportYear
The query also uses a CASE statement in the SELECT clause to match the column in the GROUP BY definition. You don't need to construct the query dynamically just because you have a variable GROUP BY definition. Sometimes you can't avoid dynamic SQL, but first check to see if there's an alternative approach that's practical and won't affect performance.
Sometimes you can't avoid dynamic SQL. Just make sure that there isn't an alternative approach that's practical and won't affect performance.
Answer 13: Diagnosing Performance Issues on Linked Servers and Parameterized Queries
As I stated in the question, this is definitely an esoteric topic. I encountered the subject about two years ago, where I noticed dramatically different performance on what seemed to be the same linked server query.
The reason that A can be much faster than B and C boils down to this: Although B and C use the four-part naming and essentially bypass the OPENQUERY call, they sometimes force the linked server driver to pull down ALL the rows from the source table, and then perform the filtering/WHERE clause locally in SQL Server. If the source table is large, this dramatically harms performance. Only by using OPENQUERY and passing the entire query as a string can you have a near-guarantee that the entire query (and the WHERE clause) will be executed at the remote server end. Although the four-part convention might seem cleaner (especially if you try to parameterize the query), you risk SQL Server pulling down all rows.
Final Thoughts:
As I stated at the beginning of the article, I'm going to use this format for some of my Baker's Dozen articles in the future. In my next column, I'll present a 13-question test on topics in SQL Server Reporting Services. Stay tuned!
