


Nearly every professional endeavor contains processes and methods associated with carrying out tasks in that discipline. Those with experience will recommend these as practices, with the idea that following these practices leads to better, cleaner, and more productive outcomes. In the world of data warehousing, many industry journals report that Extract/Transform/Load (ETL) development activities account for a large majority (as much as 75%) of total data warehouse work. When you combine that statistic with the palpable and sobering objective of a data warehouse as the “single version of trust,” good processes are essential.
I've studied the large volumes of material on data warehouse ETL practices and have collected many useful thoughts along the way. I've worked on many data warehouse initiatives, led several data warehouse projects, and also taught and mentored on the subject. Because of this, CODE Magazine asked me to write an article on the subject, so, in my traditional Baker's Dozen format, I'll present thirteen tips that you can incorporate into your data warehouse ETL projects. Because this general topic is so deep, I'm writing it as a two-part article. This first part presents 13 general tips that focus on practice and methodology, although I'll go into a certain level of detail when necessary. The second part will apply these tips to a specific data warehouse project using the newest features in SQL Server, and will focus on applying those methods using Microsoft technologies.
“But what if I don't work in Data Warehousing?”
Even if you don't build full-blown data warehouses, you might still benefit from this article. If your job includes retrieving (extracting) data from one location, manipulating/validating (transforming) that data in the middle, and then saving (loading) that data somewhere else, you might find value from some of these tips. Many ETL processes have a series of common patterns/activities, whether the end-game is a full-blown data warehouse or some type of operational transaction system or data store.
Related Article
What's on the Menu?
Here are the topics for today:
- Populating the end-result data model as early as possible
- Defining a high-level roadmap of physical data sources and processes
- Establishing necessary source data, profile source data, and source primary keys
- Extract logic
- Identify and account for any specific data type challenges
- Define primary keys in source data, and what happens when source systems delete data
- Use of the MERGE and composable DML and extract engines
- Baker's Dozen Spotlight: Collecting all activity in ETL logs
- Capturing periodic snapshots of data
- Source system verifications
- Messaging and alerts
- Scheduling and source dependencies
- Baker's Dozen Potpourri: Miscellaneous ETL thoughts
Required Reading
I've been building database applications (transactional, data warehouse, and reporting databases) for thirty years. I taught SQL Server and Data Warehousing for five years. I've held leadership roles in data warehousing for a decade. Although aggregate counts of activity don't automatically translate into meaningful experience, I'll put my professional reputation on the line by making a recommendation that served me and others well: if you work in this space, you should read the Ralph and Julie Kimball series of books on data warehousing and dimensional modeling. Read them again and again. Read them until your eyes bleed. I've found countless tips on data warehouse modeling and ETL subsystems from these books and website articles. If you're new to the Kimball methodologies and want to start exploring, here's a good place to start: http://www.kimballgroup.com/data-warehouse-business-intelligence-resources/. You can also find a good overview that accompanies the ETL book here: http://www.kimballgroup.com/2007/10/subsystems-of-etl-revisited/. I almost envy anyone who is about to dive into the Kimball world for the first time. That's how good these resources are.
Ralph and Julie Kimball retired at the end of 2015. Fear not: This only strengthens the resolve of those who partnered with the Kimball family. Joy Mundy (http://www.kimballgroup.com/author/joy/) continues to teach. Margy Ross and Bob Becker lead Decision Works Consulting (https://decisionworks.com/). These are the Data Warehouse Jedi Masters, and you owe it to yourself and your clients to read as much of their material as you can and analyze how you can apply their recommendations to your applications.
Additionally, I recommend my prior CODE Magazine article from March/April 2013, where I talk about implementing the Kimball Dimensional modeling patterns: http://www.codemag.com/article/1304071
#1: Populate the Data Model with Test Data as Early as Possible
Throughout many of my Baker's Dozen articles over the years, I've recommended that developers “begin with the end in mind.” In this article, a key phase in the ETL process is understanding the end game. What data model do you want to populate?
Populating data warehouse fact and dimension tables with sample data can go a long way toward making sure that all subsequent activities align with the end goal; and not just ETL activities but reporting as well.
In my prior CODE Magazine article on dimensional modeling (http://www.codemag.com/article/1304071), I presented the industry-standard case for creating fact and dimension tables. I won't repeat all the details about fact and dimension tables, other than just to generally reiterate some general concepts:
- Fact tables contain the measures that users want to aggregate (sales, quantities, costs, etc.).
- Dimension tables contain the master table business entities (product categories, customer markets, etc.).
- As a starter, link fact tables and dimension tables are linked by surrogate integer keys.
- Dimensional modeling relates to how you specifically define and relate these tables so that the business people can use the data to answer many questions, such as viewing aggregations by this business entity, by that business entity, over time, etc. Within those scenarios, there are a myriad of possibilities. The Kimball methodology shows many patterns for covering these possibilities.
Figures 1 through Figure 5 show a few rows from a basic fact sales table and related dimension tables.





By populating even a handful of rows, ETL developers have a model to use for populating actual rows. Report designers who need to create reports in parallel with ETL efforts can get a head start on report development.
Here's one final thought on populating a data model. Note that Figure 5 contains a column for a size and size range. Suppose you had a product file of 10,000 product items, and 8,500 distinct size (or weight) values down to a fraction of a centimeter or kilogram. Ask this question: Would users want to aggregate sales by a large number of distinct sizes/weights? Or would users prefer to view sales by a smaller number of meaningful ranges of sizes/weights? If the answer is the latter, then developers and business users will need to come up with rules for ranges. If you want to impress your family and friends with fifty-cent words, this process of taking a large number of attribute values and synthesizing them into a more suitable collection of values is known as discretization.
#2: Define a High-Level Roadmap of Physical Data Sources and ETL Processes
There's an old expression, “Nothing can be done in life without an idea.” My corollary is that you can't build an IT system without (among other things) a high-level roadmap or overview.
Figure 6 is one such example of an overview of ETL processes for a data warehouse system. Yes, it's the proverbial “30,000-foot view” of a system, but the picture contains just enough annotations to start identifying components, sequences, sub-systems, etc. There are just enough to details to identify where you want ETL logging and verification procedures. This can help initiate more detailed conversations on generic reusable toolsets, staging management, fact and dimension loads, audit log data points, etc.
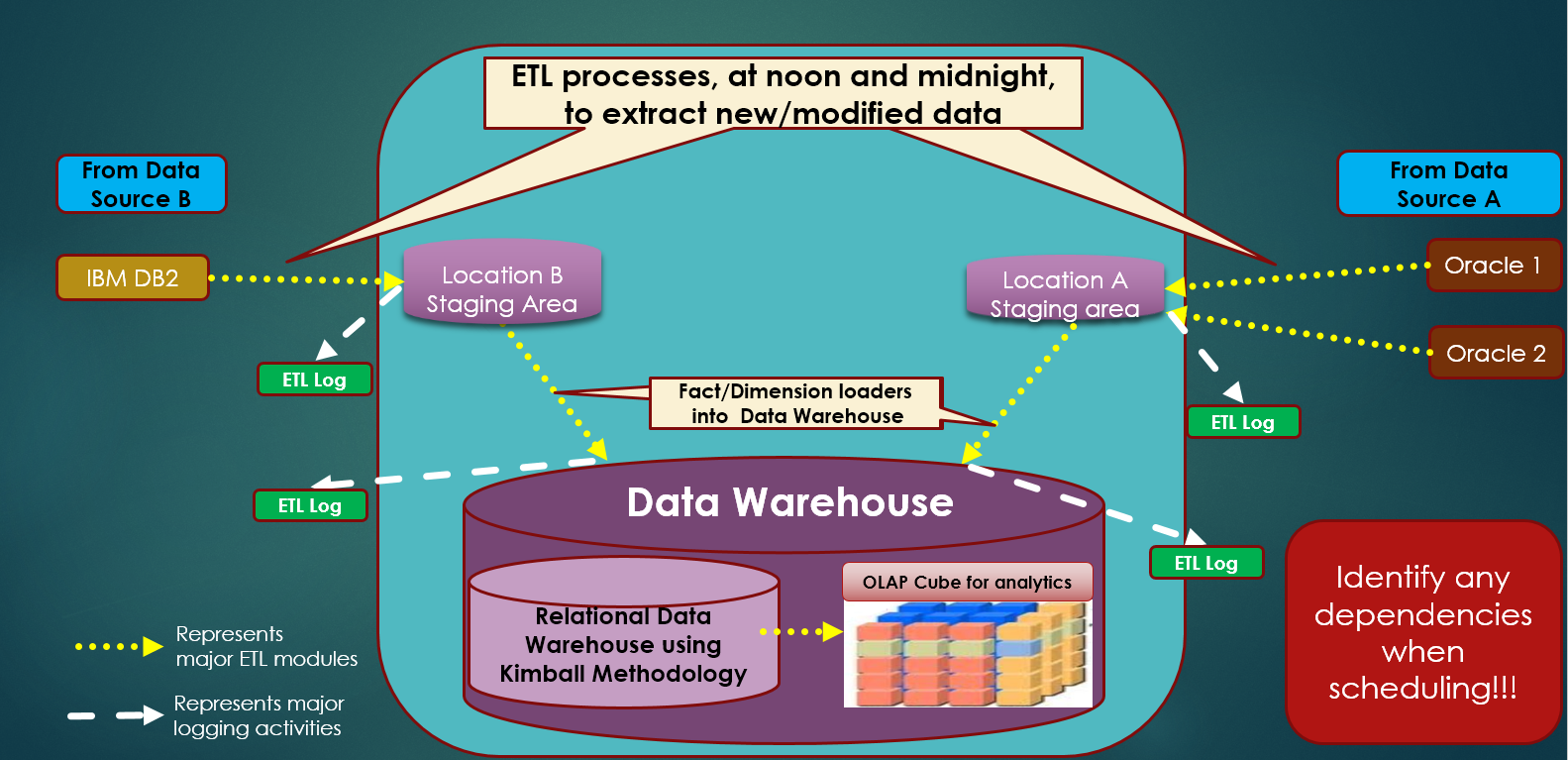
#3: Profile Source Data and Define Source Primary Keys
When I start working with a new client (or start a new database project for an existing client), I always remind them that there will be a discovery phase for studying the source system(s). In recent years, sometimes database vendors have promoted their built-in profiling tools that promise to aid in the discovery of source data.
These tools certainly have their value to help quickly identify key database relationships, ranges of values, column anomalies, etc. However, they are just that: one tool in the process. At the risk of sounding like an old-timer, there's just no substitute for good old-fashioned analysis of source data. A profiling tool can speed up identifying which columns store NULL values, but it's not likely to identify instances where repurposed columns don't contain the values you expected. A profiling tool can tell you which columns might serve as candidates for unique keys, but likely won't clue you in to whether there are gaps in pricing effectivity dates or other missing holes in data that only hand-written SQL queries will catch. A profiling tool can tell you when character columns contain out-of-range values, but probably can't tell you if there are patterns in the data that are inconsistent with what the business expects.
By the time I'm finished with the discovery phase, I've created dozens of profiling queries to validate what the DBAs for the source system have told me. If you can quickly and effectively pound out SQL queries, it'll help you as an ETL developer. For my current ETL project, I have over 100 SQL queries to profile and sanity-check source data and ETL results.
If you can quickly and effectively pound out SQL queries, it'll help you as an ETL developer.
Related to this, it's absolutely imperative that you identify primary key definitions in every source table, and also everything associated with those key definitions. You can't possibly hope to read source data into a data warehouse correctly if you don't know the grain statement (granularity) of the rows in every table. Beware, though. On more than one occasion, the source system DBA inadvertently gave me information on a uniquely defined row that turned out to be inaccurate/incomplete. Trust but verify!
#4: Define Extract Logic
Extracting data from source systems is the proverbial heart of the ETL system. There are enough practices (and horror stories) to fill a book. Here's a checklist of major items and things to consider:
- Deciding between “Truncate and Load” (T&L) versus incremental extracts. Don't scoff at T&L - if a source table is fewer than 100,000 rows, it's usually harmless. But because many source tables are hundreds of thousands or millions of rows (or more), you need to extract incrementally, based on the last time the system extracted data.
- Most incremental extract scenarios use a last date modified/timestamp column. However, in some cases, a source system doesn't have a timestamp column, and you'll need to rely on a transaction date that the source system might back-date. For instance, I had a client with an invoice table that only stored the invoice date but no timestamp. We couldn't rely solely on the invoice date value with respect to the date of the last extract, because the client sometimes posted an invoice date from several days before. We had to be conservative and extract all invoices with an invoice date in the last seven days. Yes, we extracted more than we needed, but it was safe.
- It should go without saying that your testing of extract logic should include verification procedures. I'll talk about that in Tip #10.
- Make sure to profile how long your extract processes take. Although you might not be able to control it, there's always the chance that additional indexes in the source system can help with extract performance.
- Here's one you might not immediately think of: the default isolation level of the source database when querying from a source system! If you're extracting during the day/normal business hours, your extract queries can't disrupt the existing OLTP processes.
- Finally, make sure you understand as much as possible about the source system. Does it use Triggers or Change Data Capture or any other mechanism to log source system updates? Does it effectively use timestamps? Are there ever situations where source system DBAs manually update key tables without setting the timestamps? Does the source system have referential integrity? How does the source system handle cascading updates? These are things every ETL developer should know.
I cannot emphasize how critical this is. Read and test your extract code again, and again, and again. It seems that I can't write an article without using a movie quote. In the movie “Outbreak,” Dustin Hoffman's character passionately tells his medical team, “Go back and test the area again. And then test it again. And then when you're finished, test it again!” OK, there's some drama in the scene, but the point is that testing and verifying extract logic should be taken very seriously!
I've used this expression for years: “Water freezes at 32 degrees.” You might think you've accounted for every extract scenario (and therefore frozen the water), when in fact the water is still 34 degrees because you've left one extract scenario warm. Find that freezing point where you have everything “down cold.”
Water freezes at 32 degrees. You might think you've accounted for every extract scenario (and frozen the water), when the water is still 34 degrees because you've left one extract scenario warm. Find that freezing point where you have everything “down cold.”
#5: Identify Any Specific Data Type Challenges
Did you hear the joke about the SQL Server who walks into a DB2 bar, asks for the TIME, and gets shut down? Well, OK, it's not much of a joke, although the problem that can occur is one that probably makes a developer want to go visit a bar!
Here was my lesson learned from three years ago when I worked on a project to read IBM/DB2 data into SQL Server. I ran the following query to profile some data.
SELECT * FROM OPENQUERY
( [DB2_LinkedServer_DEV],
'SELECT * FROM SomeDB2Schema.SomeDB2Table
FETCH FIRST 100 ROWS ONLY')
Instead of seeing 100 rows, I only saw about a dozen rows, followed by the following error: Error converting data type DBTYPE_DBTIME to time. Unfortunately, the error didn't indicate the specific column with the problem!
I'll spare the ugly details of how I found the problem (and the ugly bad words I screamed along the way). Basically, DB2's TIME data type (DBTYPE_DBTIME) permits a value of 24.00.00 and SQL Server does not permit such a value in its corresponding TIME type. In this instance, a date of September 3, 2014 and a time of 24.00.00 basically amounted to a date of September 4. In the query, I evaluated the time column, and adjusted the date (by adding a day) and time accordingly.
SELECT DateCol, CAST(TimeCol as Time) AS TimeCol
FROM OPENQUERY
( [DB2_LinkedServer_DEV],
'SELECT *
CASE WHEN TimeCol = ''24.00.00''
THEN DateCol + 1 DAYS
ELSE DateCol END AS DateCol,
CASE WHEN TimeCol = ''24.00.00''
THEN ''00.00.00''
ELSE TimeCol END AS TimeCol
FROM SomeDB2Schema.SomeDB2Table
FETCH FIRST 100 ROWS ONLY')
This is just one example of a data type challenge, but it illustrates how data types can differ in various database platforms.
#6: Identify Scenarios When Source Systems Delete Data
In the world of data warehousing, the concept of DELETE is a four-letter word. Furthermore, some regulated industries (such as health care) might have restrictions against deleting rows.
Imagine this scenario: You're incrementally extracting data from an Oracle or DB2 source system several times a day, based on insertions and updates in the source system. Then you learn that the source system deletes some rows and has no log you can read to determine the key of the deleted row and the deletion time. In the absence of that information, how can you identify and then flag the corresponding row in the data warehouse as a deleted row?
Depending on the proximity of the source database with respect to the target data warehouse, the answer ranges from “with difficulty,” to “practically impossible.”
Here are two ways to handle this. First, you could set up a monthly job to “truncate and re-load” the entire source table (or a partition, if the source system partitions based on week, month, etc.). That effectively refreshes your data warehouse table to match the source system. Second, you could pass a list of the data warehouse source keys to the source system, query the matching keys in the destination system, and then mark the data warehouse keys as inactive/deleted. However, depending on table sizes, these approaches might not be practical or even possible.
Related to this, please don't ever delete rows in a production data warehouse system - or at least don't delete rows unless you log them. If you're designing a transaction OLTP system, consider how outside systems can identify and retrieve all of the DML activities in your system.
If you're designing a transaction OLTP system, consider how outside systems can identify and retrieve all of the DML activities in your system.
#7: Use of the MERGE and Composable DML and Extract Engines
Although I'm trying to focus on general practices (and minimize specific technology features), I also want to take a moment to talk about some major functionality that Microsoft added in SQL Server 2008 that you can use in ETL scenarios. One is a general feature called composable DML, which allows you to take data from the OUTPUT clause of a DML (i.e., INSERT, UPDATE, DELETE) statement, use it as a derived table, and insert it into another table. The second is a specific language feature called MERGE, which combines the features of an INSERT and an UPDATE into one statement, with the ability not only to add conditions for inserts and updates, but also to leverage composable DML.
ETL developers can make great use of these two features, as many ETL processes need to handle scenarios like the following:
- Read in one million rows from a source system, where maybe 5,000 constitute new rows, 20,000 constitute existing rows where some non-key column has changed, and the remaining rows require no action.
- Read in rows, perform INSERT and UPDATE operations, and then redirect the results to a log table.
- Preserve version history (i.e., Type 2 Slowly Changing Dimensions) when an ETL operation detects a change to a significant column.
I've written examples of composable DML and the MERGE statements in several prior CODE Magazine articles. Most recently, I provided code listings in the November/December 2015 issue, as well as the January/February 2016 issue.
Some developers have commented that the MERGE syntax is difficult to master. Some have even stated that it's more than twice as complicated as the sum of the complexities of the INSERT and UPDATE statements that MERGE essentially combines. Although I think MERGE is a great feature, I don't discount the comments of developers who find MERGE difficult. I'll even go so far as to say that ETL environments with many tables and many columns to check (for changes) can mean needing to write a large amount of code. This happens to be the argument some make against database triggers - they can require LOTS of code.
But wait! Don't some developers wind up building code/template generators to get around this? Yes, they do. That's a segue to my next point:
In Part 2 of this article when I show a full ETL example, I'll demonstrate not only how you can use composable DML with MERGE, but I'll also build on the concepts I covered in the Jan/Feb 2016 CODE issue, where I presented the case for a function to read a data dictionary and generate MERGE code automatically.
#8: Baker's Dozen Spotlight: Collecting All Activity in ETL Logs
There are many ingredients in a good data warehouse. An important one is brainstorming sessions over different ETL components. I love whiteboard sessions where the team thinks through every possible scenario and solution. One of my favorite types of brainstorming sessions is on what to capture in ETL audit logs. Just like Windows Event logs and network logs tell us nearly every system activity that occurred days or weeks ago, ETL logs can store all sorts of information, such as:
- When extracts occurred and how long they took to execute (so that you can view extract performance over time)
- The number of rows inserted/changed/flagged for deletion
- Any errors (either system errors, or simply validation errors because the ETL rejected certain rows)
- The keys generated from insertions
ETL and Data Warehouse log files are like auto insurance. You put time and money into them for months or even years, possibly without incident. But just like insurance, when you need the contents of a log for an extract three weeks ago, you really need it!
As much as possible, stop and think about all the times you might want to go back and say, “On this date, how many rows did we do such and such?”
#9: Capturing Periodic Snapshots of Data
Here's a corollary to the prior tip about creating ETL log files: Have you ever thought to yourself, “I wish we could see the state of the source database right before we ran month-end reporting two months ago?” Although it might not be possible or practical to go back and recreate source database history for any day over the last two years, there could be specific events (e.g., month-end processing) where you want to capture the state of the database at the time.
In Part 2 of this article, I'll talk about specific features in SQL Server (everything from temporal tables to Change Data Capture logs) to help facilitate snapshots and how to recreate a “point in time” representation of the source data. Additionally, you might want to recreate the state of your staging area based on that point in time. Finally, make sure to factor snapshots into any physical capacity planning of your database size.
Make sure to factor snapshots into any physical capacity planning of your database size.
Remember this: if you're not capturing snapshots and discover a year later that you need them, and you also discover that source systems no longer have the “point in time” raw data that you're looking for, you're in trouble! Think about a plan for periodic snapshots of data.
#10: Source System Verifications
Recently I took my daughter to a science show that focused on space travel. There were plenty of breathtaking videos and pictures of planets and other wonderful things in space. However, what caught my attention the most was the myriad of system checks and verifications that go into their work. For them, it's constant. Although most data warehouse scenarios aren't 100% life and death, maybe we should treat them as such.
One set of verifications I stress in data warehouse ETL methodology is source system verifications. For instance, if there were 15,987 shipment transactions in the source system for all of yesterday, resulting in shipment revenue of $7,933,123, the ETL processes should show the same amount after the ETL extractions occur. The only exception might be late arriving shipments posted in the source system after midnight for the previous day, although you could factor that into the verification as well.
Note that there could be two levels of verification: verifying the source system against what you've loaded into your staging area, and verifying the source system against your staging area and against your final data warehouse destination. If you see discrepancies in the first, you might have an extract issue. If you see discrepancies in the second, it probably means that your source extract is working but you're dropping (or double-counting) data when you're loading into the final model.
Treat those verification counts like money you think you're posting to your bank account. If you know you made five deposits into the bank before closing time, but only four showed up the next day, you'd be very concerned! Treat the data the same way.
If users come to you saying that your new system is wrong because the source system shows different numbers, you want to be prepared. If you're doing systematic source verification checks, you can stay on top of it. If you're spending hours every week responding to support calls and researching why numbers are different, it might mean that you didn't set up the necessary verifications to begin with.
If users come to you saying that your new system is wrong because the source system shows different numbers, you want to be prepared. If you're doing systematic source verification checks, you can stay on top of it.
#11: Messaging and Alerts
I went through a period when I was paranoid about whether overnight processes worked properly. I knew that users would be running reports very early the next morning, and I wanted to make sure they wouldn't run into issues. I watched ETL results in the middle of the night for long enough to know there wouldn't be user issues that morning. I was excessively paranoid. I did this for a year, during which time there were maybe seven incidents. That's roughly 2% of the nights in a year. My heart might have been in the right place, but my head didn't address it correctly. I was getting up at 2 AM and then at 5 AM to make sure there wouldn't be any issues around 7 AM.
What I should have done from the beginning (and eventually did) was carve out some time to work with my team on coming up with messaging and alert procedures so that any fatal error or verification failure triggered phone calls. Yes, it meant some researching of phone technology because different phone models handle messages and alerts in different ways. If you DO receive that 3 AM call, you want to make sure that the phone will awaken the deepest of sleepers!
The DevOps people are probably chuckling when they read this, because this approach of “baby-sitting” automated jobs has been a dirty anti-pattern (and rightly so) in their books for a long time. Without going into blog-level commentary, waking up in the middle of the night to check processes might seem “valiant and heroic” to head off early morning issues. It's also very foolish and ultimately self-defeating. I'll freely admit that I went far too long before I made changes, and I don't want others to make the mistake I made.
#12: Scheduling, Source Dependencies, and Parallelism
Back in Figure 6 on the high-level process, developers and architects can follow the flow and identify different jobs. They can also go further and start to identify the following:
- When jobs should run (a source system might not be ready for extracts from prior business day until after 1 AM)
- The sequence of events (you can't start certain jobs until you know that others are finished)
- Opportunities for parallelism (if you can extract from 30 tables in parallel instead of succession, it might help with performance)
As a team lead, I know I can't think of every sequence in every step every time. Talking through these issues can be a great team-building exercise.
#13: Baker's Dozen Potpourri: Miscellaneous ETL thoughts
Here are some random tips with a few notes. Admittedly, a few of these might be repetition from prior tips in this article.
- Avoid row-by-row ETL operations on large tables. The great SQL author Joe Celko has written many books and articles that demonstrate set-based solutions for querying data. Row-by-row processes won't scale well. Yes, that means you might need to analyze queries and perhaps investigate index strategies; badly-implemented queries can perform WORSE than row-by-row operations. Still, a well-designed set-based solution is best.
- A related note: Although I'll talk about this in more detail in the second part of this article, I definitely recommend spending some time researching the in-memory optimizations that Microsoft implemented in SQL Server 2014 (and greatly enhanced in SQL 2016). Even if you only use in-memory optimized tables to speed up staging table operations, the functionality can have a big positive impact on ETL processing time.
- As difficult as it might seem, maintain the documentation on data lineage. Imagine if someone asks a question, “For data warehouse column ABC or data warehouse report XYZ, where does that come from in the source system?” If your answer is, “Let me check the code,” there's failure here.
- If your ETL fails midway through the process, can you restart at the point of failure? The answer to this and related questions will probably indicate how modularly you've built your procedures. Although database environments and ETL tools are usually not object-oriented the way development languages can be, there's no reason you can't build ETL components that will stand up to the vetting of fire-drill testing.
- Keep a log of every time you stopped to make sure an ETL process ran correctly. Additionally, keep a log of every time you had to fix a bug/mistake that you realistically could have prevented. Add up the number of instances and minutes/hours over the course of a month. I'm not saying that it should be zero every month, but more than a handful means that you should look at system checks and notifications. Good systems don't require babysitting, and watching over late-night processes like Batman keeping an eye on Gotham isn't heroic. It's ultimately harmful. Yes, you might need to take days or even weeks to come up with better solutions. You might even need to fight a manager or team lead who balks at committing time. Here's where you fight them at their own game, by documenting the hours of lost productivity.
- Never assume that you're extracting/receiving data during ETL processes in a timely fashion. The source data might contain effective dates, and you might be receiving “late-arriving data.” If your ETL processes include logic for effective dates and you receive data later than the effective date, your ETL might need to make adjustments. I recommend doing some Web searches on “Type 2 changing dimensions” and “late-arriving data” for more information on this specific ETL pattern.
- If you're using Microsoft SQL Server Linked Servers to retrieve information from other database platforms (Oracle, IBM DB2, etc.), be careful with them and test out the various ways you intend to use them. Linked Servers can be great for retrieving data from source system, but they also have restrictions and nuances, some of which I'll cover in the next issue.
- Most people have heard the classic narrative about developers and users arguing if you put them in the same room. Although that does happen, here's something more common: Put business users in the same room to talk about a new system (and/or to talk about old source data), and you'll hear the users debate or even argue about the functional use and business application of the system/data. Just as developers on a team have different visions that can make a team look less than cohesive, business users have different interpretations and expectations. Here's a dirty little secret: Businesses patch their rules as often as developers patch code and some patches are more visible than others. Why am I mentioning this? Because this can impact ETL development, as the business might give conflicting requirements that affect where and how you extract data, the rules for loading data warehouse fact/dimension tables, etc. There are no simple answers here. Even experienced project managers struggle with this one. As an analyst, I'm trained to ask many questions and seek sanity checks from users; often this complicates matters because business users learn of things they might otherwise not have known (and also don't agree with). Most have heard the expression that a data warehouse represents “one version of the truth.” My corollary is that a good data warehouse team might have to work through dozens or even hundreds of untruths and semi-truths in source data until they achieve the “one true version.”
Discipline is Not the Enemy of Enthusiasm
I own tons of movie DVDs from many film genres. I love to quote movies, although my family and friends roll their eyes when I do it repeatedly. I love the movie “Glory Road” and sometimes used lines from the movie when I worked as an instructor. I'm going to close this article with a quote that resonates with the theme of good practices. In the movie “Lean on Me.” high school principal Joe Clark (played by Morgan Freeman) takes over a deeply-troubled high school and uses strong discipline to improve basic skills test scores. Yes, the movie is a dramatized version of a real-life story, and Joe Clark used some tactics I would never advocate. However, he tells students, "Discipline is not the Enemy of Enthusiasm." Words and ideas can be very powerful, and these words convey a compelling message: Adhering to rules and practices doesn't necessarily mean discouragement.
Yes, adhering to good practices takes time. In the beginning, good practices might seem more of a roadblock to productivity than a pathway. That's where leadership and experience come in, to help show how to repeat good approaches over time: not “by rote,” but rather by showing the connection between good approaches and good outcomes (fewer errors, fewer bad results). Just think how happy you might be in six months if you take action that leads to fewer support headaches and fewer instances of saying, “I wish we had been logging this all along because we'd be in a much better place.”
Less than three months ago, I had to take serious action on some things I was doing very badly. The specifics don't matter. At first, I wasn't celebrating the fact that I had to drastically alter some approaches, but all along I tried to focus on how much better off I'd be. Three months later, I'm much happier than I was, and I'm eager to keep doing it. Always focus on outcomes!
Also remember that not all practices are created equally. Once again, that's where experience comes in - to help identify the good ones and help to demonstrate which bad ones are indeed “bad.” Good practices are organic and seminal.
Thank You, Rod Paddock
I've been writing for CODE Magazine since 2004 and have penned nearly 50 articles. In almost all cases, I came up with the article theme. This time, Rod Paddock (CODE Magazine's Chief Editor) told me he was looking for some content on ETL practices. I slapped myself in the head for not thinking of it before, because it's a subject I've truly lived with for a long time. It's great to work with a Chief Editor who comes up with the good ideas, and it's also an honor to have the opportunity to promote the very Kimball data warehouse and ETL methods that have served people well for over a decade! The Kimball books literally changed my life, and although I don't expect to change any reader's life with one article, I sincerely hope that I've offered some practices that will help ETL environments.
Tune in Next Time: Same Bat Channel, Same Bat Station…
Many years ago, I worked on a large public-sector application for which I won awards from the United States Department of Agriculture. I've been refactoring it to create a community data warehouse ETL demo. In my next article, I'm going to present portions of the ETL application, and will reference the content from this article. Stay tuned!
