





By now, I'm certain, you tried one of the many online services that allow you to use a Large Language Model. If so, you might even be familiar with responses like, "I'm sorry, but I cannot provide assistance on ...". In this practical guide, I will talk about why open-source language models are important, why you'd want to use them, how to choose and where to find a model, and how to run them on your own local or hosted machine.
Let's be clear, crafting narratives isn't my forte - hence my role as a software developer and not the next Tolkien. But I do enjoy high fantasy and I'll admit that I've spent many a night playing Dungeons and Dragons with my friends. You can imagine how excited I was when I discovered ChatGPT in early 2023, promising an unending well of ideas for characters, villains, and sticky situations for my players' intrepid heroes to get out of.
Until one day, I tried to create some mean gangsters to accost my players in a big city and it only said, “I'm sorry, but as an AI language model, it is not appropriate to glorify criminal behavior, even in a fictional setting.” I pleaded with the AI, tried to get around its safety measures, and cried out to the silicon gods! It kept insisting that we must be nice to each other.
ChatGPT kept insisting that we must be nice to each other.
Defeated and disappointed, I thought about how to crack open that vault of creativity in my head. My imaginary blowtorches and thief's tools were no match for hardened steel.
Then I discovered that some very smart people had trained open-source language models that anyone could run with the right hardware and applications. Finally, the promise of unrestricted models that don't tell you what you can and can't do! Interesting and evil villains may terrorize the free citizens of the Sword Coast yet again and my campaign lives on!
It's Dangerous to Go Alone: A Collaborative Journey
In the following months, I closely followed the news and updates surrounding this very active community of software engineers and data scientists with wonder and admiration, and a good measure of perplexity due to the new concepts and lingo surrounding all of it. It motivated me to learn more. I listened to Andrej Karpathy explaining how to build GPT, learned what difference training data and methodologies make, and what all these parameters beyond “temperature” mean. But mainly, I learned how to start using this amazing technology in my own work. And in the programming language that I like the most (which is C#, of course).
A lot has happened in the open-source LLM space since then, more than I could put down in just one article. And with the current speed of change, it would likely be dated by the time this was printed and read by anyone anyway. One thing is clear to me though: Open source proves yet again how important freely accessible software is. With the gracious support of large companies like Meta and Microsoft, and smaller players like Mistral.AI, et al., who all released foundation models, the community fine-tunes and distributes models for specific use cases and offers an alternative to the closed-source, paid models that OpenAI or Google offer.
Open-source proves, yet again, how important freely accessible software is.
This is not only important from an engineering standpoint (we do like to tinker after all), but with the release of research papers alongside models and training datasets, the community has picked up on many of these developments and improved on them. I'd be genuinely surprised if the current state-of-the-art models released as paid offerings would be as advanced as they are if the open-source community didn't exist.
Open source also prevents a few big players from capturing the technology and dictating what LLMs look like. The motives and priorities of a large company often don't align with those of the people, after all. A democratized landscape with openly accessible tools evens out the playing field, even if there is a limitation based on the computing power that's available for training foundation models.
You Had My Curiosity, but Now You Have My Attention
If you have the impression that using open-source LLMs is more complicated than opening a website and asking a question, you're absolutely right! Don't let that scare you away though, it's well worth understanding the following terms, ideas, and principles.
I'll start by looking at some of the reasons why you, as a developer or organization, might want to use an open-source LLM over a paid offering by OpenAI or Microsoft. Afterward, I'll discuss the types of models that exist, the variations they may come in, and where to find and how to choose models. I'll conclude by presenting some ways to get started running LLMs using a few different applications you can download and use for free.
We Do What We Must Because We Can
As with the adoption of any other new technology, you must be able to evaluate whether it's the right one for your use case. Using something just because you can is rarely a good idea. You might look at these arguments and conclude that a SaaS offering is serving you just fine. Be aware that although the following are important considerations to keep in mind, they are, by far, not the only ones.
Using something just because you can is rarely a good idea.
Control
As with any SaaS offering out there, it's out of your control whether the behavior of features changes. This is especially true for the ever-evolving LLMs and the exact thing that drove my attention to open-source LLMs.
SaaS offerings must evolve with the attacks leveraged against them and their safety alignment must be updated to thwart new prompting attacks that expose dangerous and unwanted behavior. They also must improve performance through continued fine-tuning of their models to prevent falling behind the competition.
These kinds of tweaks can influence the overall behavior of the model and break the workflows that you implemented on your end, requiring you or your team to constantly evaluate and update the prompts you use in your application.
I don't just claim this based on my own observations. A study called “How Is ChatGPT's Behavior Changing over Time?” released by a team at Stanford University and UC Berkeley demonstrated this behavior. They asked a set of questions in March 2023 and then in June 2023. The answers were recorded and compared, showing significant differences between the model versions. They concluded that:
“Our findings demonstrate that the behavior of GPT-3.5 and GPT-4 has varied significantly over a relatively short amount of time. This highlights the need to continuously evaluate and assess the behavior of LLM drifts in applications, especially as it is not transparent how LLMs such as ChatGPT are updated over time. [...] Improving the model's performance on some tasks, for example with fine-tuning on additional data, can have unexpected side effects on its behavior in other tasks.” (https://arxiv.org/abs/2307.09009)
To reiterate, fine-tuning to improve performance and updating model alignment is good and necessary work! But safety alignment, especially, is a tough issue to solve and hard to get right for everyone. You might end up with a use case that works at first but then breaks over time because it's deemed dangerous or has unwanted behavior even though it's completely legitimate.
Open-source LLMs don't change once they're downloaded, of course. And you can easily find models that are uncensored and have no quarrels responding to any and all of your questions. There are also models that come with a certain level of pre-trained safety. These models aren't guaranteed to be as effective at resisting attacks, like the infamous DAN (Do Anything Now) jailbreak, and show that open-source LLMs can be a double-edged sword. On the one hand, you're not limited by the safety alignment of the large SaaS providers. On the other hand, you'll be responsible for providing a certain level of safety and alignment that you or your organization can be comfortable with. Especially when the product you implement an open-source LLM into is made available to the public!
You will be responsible for providing a certain level of safety and alignment.
Privacy and Compliance
The safety of customer data and intellectual property is still a big issue for many when it comes to using LLMs as a service. It was the main concern I heard when talking to people about using LLMs at 2023's DEVintersection conference. I understand where the uneasiness comes from. Especially when you consider uploading internal documents for processing and retrieval for using, for example, Retrieval Augmented Generation (RAG) applications, wherein the prospect of having sensitive data “out there” doesn't sit well. Data breaches seem to be a matter of “when” and not “if” these days, and this can be the singular issue that excludes a SaaS offering for some companies.
Another issue may be compliance agreements. They may either be a big threshold for adoption or rule out using third-party providers altogether. If your own environment is already set up to be compliant, it might just be easier to use a locally run open-source LLM. It might also be the only way to stay compliant with local laws that forbid you from sending user data into other jurisdictions, like the United States (think GDPR), either by using your own servers or hosting a model with your local datacenter provider.
Offline Usage
This last one is both an argument for resilience of your applications and an excited look into the future of how we use LLMs as everyday assistants.
It's an enormously difficult task to provide consistent service to millions of people using LLMs in the cloud. The infrastructure needed for just this singular service is massive. And with scale and complexity, the likelihood of outages grows too. This is true for any SaaS offering, of course, and so the same considerations must be made for LLM services. For most use-cases, it's best practice to design your application with resilience in mind, that is, offering a degraded feature set and cache requests to the affected service for later. Failover to another region is another good way to handle service interruptions where possible.
You might have a use-case, though, that requires uninterrupted availability. This may be especially true for applications out in the field where cellular service is unavailable (welcome to rural America) or if you have an application that needs to be available in disaster scenarios. With LLMs that can run on commodity hardware, this is a possibility today. Chatting with an LLM during a recent flight without internet access was a real head-turner!
And this is why I get excited for the future of locally run LLMs. Small models become more and more capable and will make the personal assistants on our phones incredibly powerful, while keeping our private information out of the hands of data brokers.
Small models will make the personal assistants on our phones incredibly powerful.
Additional Considerations
Beyond these three considerations, you might also find that using open-source models on your own hardware can save you money, especially when a SaaS offering is based on a per-user basis and an equivalent open-source option is available to you. You may also consider fine-tuning a model on your own data, and, although this is possible using OpenAI and Azure OpenAI, data privacy and compliance issues might be an issue here as well. Then there are deployment considerations, which is a highly individual and use-case driven issue that will have to be analyzed based on your needs.
Not All Models Are Created Equal
When you look at the text generation model catalogue on Hugging Face you might wonder how to choose from the over 37,000 models that are currently available. I remember feeling quite overwhelmed at first and wasn't sure where to begin. After understanding the process of how these models are created and where to find good comparisons, it was easy to find the right model for my use cases.
Building a Strong Foundation
It all starts with a foundation model. These are models trained by organizations that can afford to buy or rent large amounts of hardware and pay for the necessary steps that come before the actual training.
Let's take Meta's popular Llama 2 model as an example. It was trained on an immense amount of 2 trillion tokens (roughly 500 billion words). These text sources needed to be collected from various sources and then pre-processed before they could be used to train the model. The data used for this training is largely unstructured and unlabeled text. The training of the three model sizes of 7, 13, and 70 billion parameters (more on that later) that Meta released took a combined 3.3 million GPU hours.
The training took a combined 3.3 million GPU hours.
At this point, the model has a lot of knowledge, but it doesn't quite know what to do with it. If you asked it a question it would struggle to give you a coherent answer. This is where the next training step comes in.
Learning the Ropes
A foundation (or pre-trained) model needs to learn how it's expected to behave when the user asks a question. The most familiar use case right now is a chat-style behavior. To learn how to have a proper conversation, a model is trained on curated conversational datasets. The datasets for this supervised fine-tuning step are labeled to communicate the desired outcome for each instance of input data. Further Reinforcement Learning with Human Feedback (RLHF) and other techniques can be used as another step to improve the output quality and align the model according to behavior and safety requirements.
The amazing fact about fine-tuning models is that it's far less resource-intensive than creating a foundation model. It's quite achievable for individuals and companies to train a foundation model on the specific use case they want to use it for.
Besides the chat-style behavior, the next most common fine-tune you can find is for instructions. These models are trained to give answers and adhere to an instruction given to them. The notable difference is that chat models may continue to elaborate, when tasked, to produce a specific output like, for example, “yes-” or “no-” only answers. Instruction fine-tuned models typically adhere more to the given restriction.
Navigating Models on Hugging Face
Llama, Alpaca, Platypus, Orca - all of these and others refer to models, training datasets, or techniques used to create a dataset. Each model on Hugging Face has a “model card” that includes these details and more. An important piece of information to look out for is the prompt template that the model was trained on. These templates separate the system, user, and assistant messages from each other. With this, the model isn't getting confused about who said what and can correctly infer from previous conversations. If no specific template is mentioned, the template of the model's foundation model is usually a safe bet.
Comparing Llamas and Alpacas
LLMs are frequently tested against manual and automated suites of tests that can give us a rough idea of their capabilities.
The “Open LLM Leaderboard” on Hugging Face is a decent first place to get started in the search for an LLM (see https://bit.ly/llmleaderboard). It lets you filter by model type, number of parameters (size), and precision, and you can sort by an average score or specific test scores. Be aware that there's some criticism around this leaderboard because there are models that try to game the tests by including both the questions and the answers in their training data. The community flags these models for this behavior and excludes them by default. But there's still a trend away from this leaderboard as a reliable resource at the moment.
Another interesting leaderboard can be found on the Chatbot Arena website. Chatbot Arena generates its rankings by pitting two random LLMs against each other that both get the same user prompt. Users don't know which models are replying. They can then vote for which model output they like better. Votes are aggregated into a score on the leaderboard. Since this is not a uniform test that is applied to all models equally, it relies on the average subjective experience of the crowd. It can only give a general comparison but can't discern the strengths and weaknesses of a model (e.g., writing vs. coding).
The best source for model comparisons is the “LocalLLaMA” subreddit. Searching for “comparison” in this sub will return several users' own comparison results. It's worth looking at these because they often give a detailed description of the results and aren't as susceptible to manipulation through training on test questions as the standardized tests of the Open LLM Leaderboard. This is also the place to find general information about LLMs and the latest news and developments in the field.
In the end, it's always important to test the chosen model on the intended use case.
Bring Your Own Machine
Now you know what the different types of models are, where to find them, and how to choose one based on your use-case and openly accessible comparisons. With that out of the way, I can turn to the more practical portion in the quest to run LLMs. In this section of the article, I'll talk about hardware requirements and (currently) supported hardware and the software needed to run an LLM.
I'll begin by looking at the disk and memory size requirements of LLMs and a technique called quantization that reduces these requirements.
One Size Does Not Fit All
When discussing LLM sizes, it's crucial to understand that “size” refers to the number of parameters a specific model contains. Parameters in LLMs are adjustable components or weights that influence behavior and performance during tasks, such as text generation and translation. They represent connections between neurons in a neural network architecture and enable it to learn complex relationships and patterns within language.
In the landscape of LLMs, size is a significant factor in determining their capabilities. Although it may seem that the larger model always performs better, selecting the appropriate size for your use case requires careful consideration. Larger models require more memory and processing power. Smaller models may be sufficient for your use case while being able to deliver faster response times on a smaller operational budget.
The general rule is that larger models tend to excel at tackling more complex tasks and are suitable for creative writing applications due to their ability to make intricate connections through their vast number of parameters and layers. However, small yet powerful alternatives should not be overlooked, as they often surpass expectations by delivering results comparable to those generated by larger counterparts for certain applications.
Generally, you'll find models ranging from 7B(illion) to 70B parameters with exceptions below and above these sizes. Typical counts are 7B, 13B, 33B, 65B, and 70B parameters.
The required size (in bytes) on disk can be roughly calculated by multiplying the parameter size by two, because each parameter requires two bytes to represent a parameter as a 16-bit floating point number.
The formula for the size in GB is: # of parameters * 2 (byte) / (1000^3) = x GB
For a 7B parameter model, this means: (7 * 10^9) * 2 / (1000^3) = 14.00 GB
The required memory needed to run a model is higher still. The exact amount needed is, among other things, dependent on the precision of the model weights, its architecture, and the length of the user input.
There is a way to reduce the memory requirements, though.
Accelerating LLMs with Quantization
Quantization is a technique that aims to minimize the numerical precision required for weights and activations while preserving the overall functionality of an LLM. This approach enables significant enhancements in computational efficiency, memory savings, and reduced energy consumption. As a result, quantized models are highly beneficial for deploying LLMs on devices with limited resources such as edge computing or mobile devices. However, these benefits may be accompanied by limitations, such as loss of precision, which could result in slight accuracy reductions compared to the original high-precision models.
In most cases, the benefit of lower hardware requirements beats the slight reduction in model performance. Instead of using 16-bit floating points per weight and activations, a quantized model may use 8-bit integers, all the way down to 2-bit integers. The lower the precision, the higher the impact on the model, though.
The 8-bit and 5-bit (like the mixed 5_K_M quant) are the most popular options for quantization these days. You can change the formula from above slightly to calculate the size of quantized models.
The formula for size in GB is: # of parameters (bytes) / 8 (bit) * quant size (in bit) / (1000^3) = x GB
For a 7B parameter model with 5-bit (5_K_M, ~5.67 bit/weight) quantization, this means: ((7 * 10^9) / 8) * 5.67 / (1000^3) = 4.62 GB
Compared to the 16-bit model, this is roughly a three-times reduction in size!
Quantized models come as GGUF (mainly CPU/macOS use), AWQ, and GPTQ (4bit/8bit GPU use) formats. Tom Jobbins, also known in the community as TheBloke, is a well-recognized contributor who distributes quantized versions of models on Hugging Face (https://huggingface.co/TheBloke).
Hardware Requirements for Local Inference
One, if not the biggest, factor for the hardware required for inference using LLMs is the available memory bandwidth between the memory and processor of the system. The large number of mathematical operations performed during inference demand frequent reading and writing of data into the memory.
Although it's possible to run inference on CPU and RAM, it's not the preferred way because the bandwidth per DIMM is limited to a maximum of 64GB/s for DDR5 RAM and the total bandwidth is capped by the processor (e. g., 89.6GB/s for the current Intel i9 14900K). A modern consumer graphics card, like the NVIDIA GeForce RTX 30xx/40xx series, or one of the data center graphics cards, like the A100 or H100 series, are the preferred choices for running LLMs. These top out at ~1,008GB/s (RTX 4090 24GB), 2,039GB/s (A100 80GB) and 3,072GB/s (H100 80GB) respectively.
It's important for a model to fit completely into the available VRAM of a graphics card to take advantage of the available memory bandwidth and that it's not forced to be split between the graphics card's and the system's memory. While possible, that split incurs a severe performance penalty due to the aforementioned limitations of CPU and system RAM. As you can see, a consumer graphics card is hard pressed to run larger models because it has limited VRAM. You'll have to buy multiple cards and distribute the load to run larger models.
An unlikely but comparatively price-effective competitor is the Apple M-series SoC with their unified memory architecture. The M1 and M2 Pro have 205GB/s memory bandwidth (M3 154GB/s) and can be equipped with up to 32GB (M3 36GB) RAM, of which ~24GB can be used for an LLM. All M Max series processors come with 410GB/s bandwidth and up to 128GB RAM, and the available M1 and M2 Ultra have 820GB/s bandwidth with up to 192GB RAM. Considering that memory is an expensive and limiting factor for GPUs, this can be an attractive way of evaluating large models, serving LLMs for small teams, or for applications that don't experience high request volumes.
An unlikely but comparatively price-effective competitor is the Apple M-series SoC.
I'm using a MacBook Pro with M1 Pro and 32GB RAM for my experiments and consider it useful for everything from 16-bit 7B models to 4-bit quantized versions of 33B parameter models.
If you're looking at evaluating and running large models, there's an alternative to the large upfront investment into the hardware. Several hosting services have cropped up that sell computing on an hourly basis (usually billed by the minute or second). One of these services is RunPod (https://www.runpod.io) that offers secure environments to run workloads on high-end data center GPUs like the H100. These types of services are not only useful for running inference on models, but also for fine-tuning a model to your specific needs.
Are We There Yet?
You've learned about the most important aspects of running open-source LLMs at this point, including why you'd use one, what different types there are, how to choose from the thousands of models, and what hardware is required.
Now that we're nearing the end of our journey together, one last question remains: What tools can you use to run an LLM on your machine?
llama.cpp is the workhorse of many open-source LLM projects (https://github.com/ggerganov/llama.cpp). It's a C/C++ library that provides support for LLaMA and many other model architectures, even multi-modal (vision) models. It made macOS a first-class citizen for LLMs, akin to Windows and Linux that support NVIDIA and AMD GPUs. A strong community works tirelessly to improve it. Several provided examples give you a way to explore its capabilities and a server provides an OpenAI API compatible web API. This is the choice for you if you want to implement an LLM directly into your application, either in C/C++ or with one of the many bindings for languages from C# to Rust.
The most convenient way to get started is LM Studio for Windows and macOS. This closed-source, non-commercial-use app allows the user to search the Hugging Face database for a model and download it directly while helping with the selection of the correct format for your platform. It provides an intuitive interface and can expose an OpenAI API-compatible server you can develop applications against. It features multi-modal model support for vision models that can analyze and describe images that are sent along with a text-prompt. Under the hood, it uses the llama.cpp package to provide inference (see Figure 1).
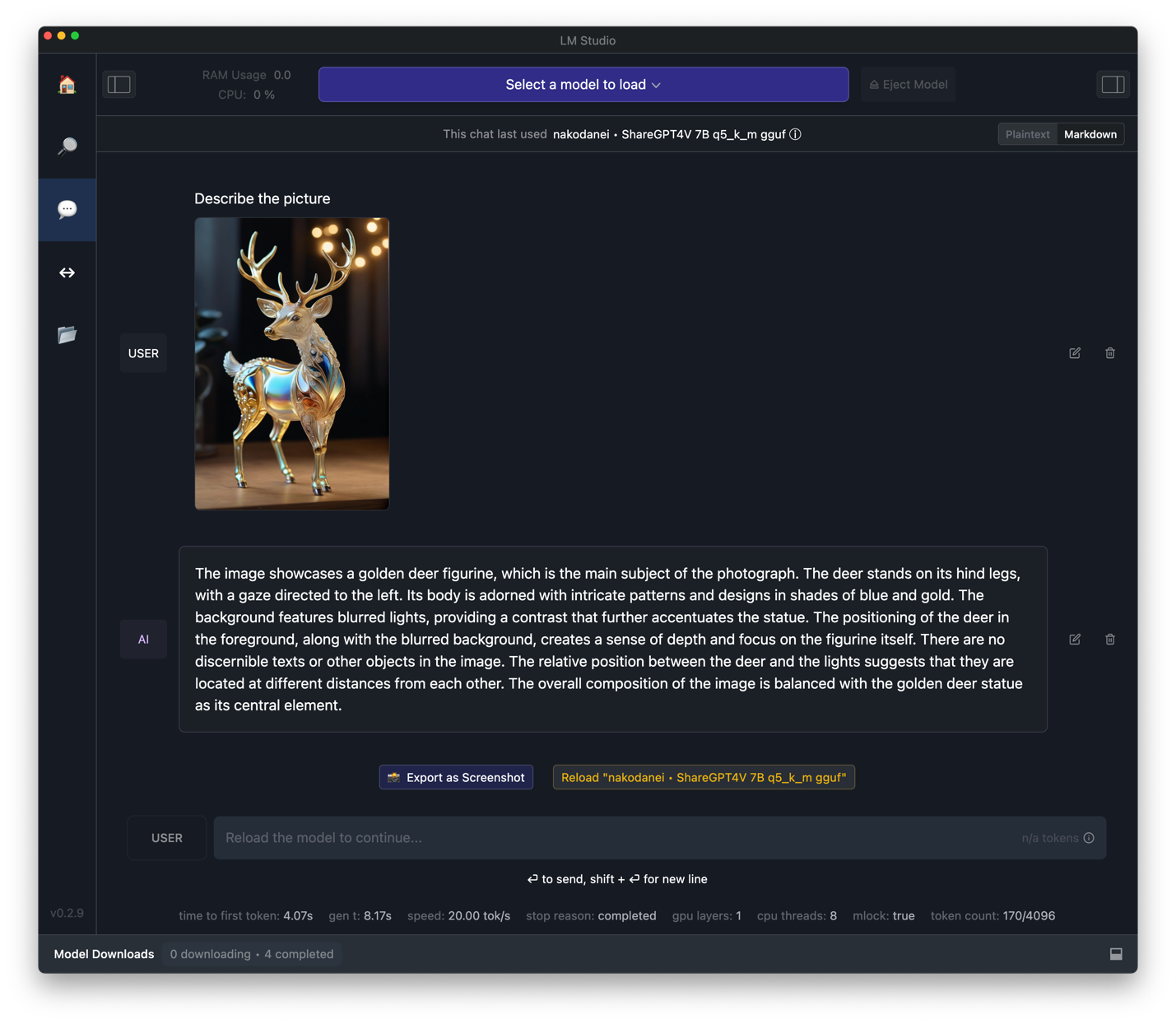
For more advanced use-cases, the Oobabooga Text generation web UI is a great choice. It can use multiple model back-ends beyond llama.cpp, adding to its versatility. It supports extensions (built-in and community) for Speech-to-Text, Text-to-Speech, Vector DBs, Stable Diffusion, and more. And the web UI makes it easy to deploy even on hosted machines that lack a desktop environment.
Whether you use llama.cpp directly, LM Studio, or the Text-generation web UI, you'll download a model, add it to a specified folder, and select it for inference. You'll have the ability to configure a system message of your choice and set inference parameters like Temperature, Max Tokens, TopP, TopK, and many more, to fine-tune the responses before posting your question. The LLM will now happily respond to your questions.
Conclusion
You have only reached the first peak on your journey into the land of open-source LLMs. From here, you can see the far-stretched mountain ranges before you that hold endless possibilities for exploration and discovery. There are many ways to go from here, whether you decide to dig into research papers and learn more about the different techniques used to improve LLMs, start building an application to improve an internal process, or explore the capabilities held by the largest of available open-source LLMs and the challenges that come with running them.
If you are curious about using LLMs in your C# applications, look out for a guide on using this exciting technology in one of the next issues of CODE Magazine!
