


As applications become more complex, designing with components becomes a very important factor in the successful completion of projects.
This article discusses n-tier application design, why it's important to modern application development, and shows strategies for breaking out the tiers using Visual FoxPro.
Let's say you work for an organization that uses an accounting system that was developed in-house. Your boss asks you to create a contact management application that uses the accounting customers table as the source of contacts (you can't use a commercial application like Act or Maximizer because they have their own contact files). So, you create a form with controls bound to the fields in the customers table, and incorporate business rules to insure that the postal code can't be left blank, and credit limits over $15,000 have to be approved by a manager. Everyone in the company likes and uses your application.
Then, one day, your boss tells you that the current accounting system isn't cutting it anymore and they're buying a commercial accounting system. She wants you to modify the contact management application to work with ACCPAC. Since ACCPAC uses Pervasive SQL (formerly Btrieve) as its database engine, you have a problem ? you can't bind controls directly to the Pervasive data. You purchase one of the third-party libraries for accessing Pervasive data (such as DBFTrieve), and completely change the form. Now the data from Pervasive goes to and from form properties, and the controls in the form are bound to these properties. Of course, although the business rules are still the same, the code that implements them must be rewritten, because the data is no longer in a cursor. You roll the new application out after several months, and it works great.
Then, one day, your boss tells you that due to company growth, the accounting system is being upgraded to the SQL Server version of ACCPAC. Since you can hit SQL Server data with remote views, you completely redo your form again so it's more like the first version, although the data is in views rather than tables. Not everyone is happy with the first implementation, though, because it's really slow over the network. So, you implement bandwidth-saving features like eliminating grids and getting only the data you actually need. You've spent a few more months at the drawing board, but now it works again.
Then, one day, your boss tells you that to save on WAN costs, the company wants remote offices to access the contact management application over the Internet…
Getting the picture? Business needs change. Unless you want to redevelop that application every time something changes, you need to use a more flexible design. Although, like OOP, n-tier architecture isn't the magic bullet to solve all of your problems, it makes for a better design because it relies heavily on components that can be swapped in and out as business needs change.
What is N-Tier?
To understand application design, it's often useful to think in layers. The pieces that the user sees and interacts with can be called the user interface (UI) or presentation layer. The code that determines which records are valid and how data should be organized can be called the business layer (“business” because this code usually implements what are called “business rules”, such as not allowing a new invoice if the customer is over his credit limit). The code that reads from and writes to the data store can be called the data layer.
The applications we've all written in the past have had these layers, but they were usually hidden by the fact that everything was kept in one place. You create a form with controls bound to the fields in a table. The Valid method of a textbox ensures that valid data is entered for that field. The Previous and Next buttons do a SKIP ?1 and SKIP, respectively, then call the Refresh method of the form to update the controls. When the user clicks on the Save button, the code in the Click method of the button makes sure the information is correct (for example, the postal code hasn't been left blank), then updates the table with TABLEUPDATE. Of course, like most smart developers, you don't put all of this code into every form. Instead, you create a maintenance form class that handles all the common tasks, so that each form created from it has just the necessary code (often just the business rules) and controls that make that form unique.
The problem with this design is that everything is bundled together. What if you want to import some records from another source rather than typing them in? You still need to do data validation, so you end up doing one of two things: running the maintenance form with the NOSHOW option and calling its validation method (ugh!), or copying and pasting that code from the form into the import PRG (double-ugh!). A better approach is to pull the validation code out of the form and put it into its own module (PRG, class, etc.). Now, you can call that module from any process that needs to validate the data. The validation rules have been separated from the UI.
The same thing holds true for data access. In the contact management scenario, every time the data store changed, the form had to almost completely be redone, because every aspect of it (controls and code) was intimately bound to the data access mechanism. Our import program would also need to be rewritten, since it can't use APPEND FROM for Pervasive data, for example. Instead, what if we create a data access component that handles the details of getting and saving records, and presents a common interface (programmatic, not visual) to any process that needs data access? Should this component be the same one that implements the data validation? No, because even though the data access mechanism changed in our scenario, the business rules stayed fairly constant.
What we've done is separate the UI, data validation (or business rules), and data access layers into separate components. That's the basics of n-tier design.
Why the “n”? This used to be called 3-tier because of the three layers involved, but as applications grew more complex, sometimes more than three layers were needed. For example, although credit card processing would obviously fall into the business layer, it might be handled by a different component (even on a different machine). What we think of as the business tier, could really consist of several layers. Therefore, the term “n-tier” is used generically to describe an architecture that consists of multiple layers.
Misnomers
N-tier is all about design and architecture, not implementation. This means that:
- N-tier doesn't necessarily involve COM, DCOM, or COM+. Although Microsoft's marketing literature for Windows DNA would lead us to believe otherwise, n-tier just means that individual duties are split into components that talk to each other. COM is a great mechanism for inter-process communication, but n-tier is still a viable solution even if you're just developing a VFP application that won't ever expose services to VB, Excel, or IIS. Of course, you should strongly resist the temptation to use the famous last words "we'll never need to ...".
- N-tier doesn't necessarily mean multi-language or multi-platform. Not every application will have a VB or DHTML front-end. Even Internet-based applications can use a fat VFP app on the client side.
- N-tier doesn't necessarily mean distributed (that is, different components running on different computers). You could create an application where everything, including the data store, is on the same machine, and it would still make sense to use an n-tier architecture.
Advantages of N-Tier
There are a lot of good reasons to use n-tier architecture in your designs:
Maintainability: It's much easier to maintain, debug, and deploy components than it is to change monolithic applications. "Let's see, was that validation code in the Valid method of the textbox, in the Click method of the Save button, in the Save method of the form, in the Save method of the form class, in the application object ...".
Reusability: The Holy Grail of programming can actually be reached when components are used. As I mentioned earlier, if the business rules are placed into their own component, that component can be used anywhere there's a need for data validation: a VFP form, an import PRG, an Excel spreadsheet, a VB app.
Flexibility: When business needs change, the ability to simply replace an old component with a new one is very compelling. In the contact management scenario, with an n-tier architecture, changing data stores would simply mean swapping the data access component for a different one. The business and UI layers wouldn't change (OK, that may be a little simplistic, but certainly the impact on those layers is much less than what happens in a monolithic application).
Scalability: IBM has a great TV commercial for their e-business solutions. Three or four kids run up to an ice cream truck, and the vendor happily serves them. Then more kids come. Soon, the vendor is surrounded by thousands of kids, but he doesn't have the resources to service them. We certainly want to avoid that problem with our applications. While you can put a monolithic application on a bigger box as demand increases, what if it increases a thousand-fold, as may be the case for a Web app? The fastest computer in the world may not help, because everyone is trying the hit the same machine simultaneously. Also, if you're using a database that is licensed by the connection, the costs skyrocket as more users come online.
Components allow an implementation in which different pieces of the application run on different machines, or even multiple copies of the same component run on multiple load-balanced servers. Database connections can be pooled, so users are attached to the database only when they're actually getting or storing data.
Distribution: It's pretty much impossible to create a Web application without using components, because by definition, different parts of the application reside on different machines. Also, it's much easier to update a component on a server than an entire application on every client's desktop.
Designing the Layers
Let's take a look at some ideas for designing the layers.
Data Layer
The data layer is the only layer that talks to the data store. Here we keep details like where and how the data is stored, how to access it, whether or not to use transactions, and whether tables are accessed directly or only through stored procedures. This provides security: if the business layer doesn't know where the data is located, it can't go and mess things up; flexibility: you can change to stored procedures from direct table access, and the business layer won't know the difference; and scalability: the data layer might maintain its database connection only for as long as it takes to do a single task, thus minimizing current connections.
How data is read from and written to the data store, and how the data layer transfers data to and from the business layer, are design decisions you'll have to make. You'll base those decisions on the data store used, company policies (such as: data can only be accessed through stored procedures), and the needs and abilities of the various components.
ADO is typically used on the client component side (using disconnected, client-side recordsets), since it provides a language-independent, object-oriented interface to data. I know people who've created a data object that exposes fields in a table as properties of the object, but you should carefully consider this approach from the standpoint of scalability. For example, if the data object is instantiated on a server using DCOM, every access to a “field” will require a round-trip to the server to get the value. On the data store side, direct access might be used if the data store is VFP tables, ODBC might be used with either remote views or SQL passthrough, or ADO could be used here, as well.
Other design decisions: You can create a single object that deals with all of the data; one object per “entity,” such as customer or order; or something in between. You can have a generic GetData method that must be told what data to get, or specific methods like GetCustomerData and GetOrderData that know exactly what to do.
Business Layer
The business layer acts a middle tier between the UI layer and the data layer. It typically implements business rules, such as “the contact name can't be left blank” and “you can't submit an order if the customer is over her credit limit”. It's the only component that talks to the data layer, so the UI can't take a shortcut to avoid the business rules. The business layer should know nothing about how or where the data is stored or accessed - it should be aware only of the data attributes, such as field names, data types, sizes, and permissible values.
ADO is often the data mechanism of choice for communicating with the data layer. But, how data is sent to the UI layer is really an implementation rather than design issue. ADO, RDS, and XML are all possibilities, and a specialized business object that creates a VFP cursor could also be used in special circumstances.
As with data objects, you can create a single business object that contains all of the business rules; separate business objects for the various entities; or something in between. It's also possible to build sophisticated object hierarchies by aggregating objects that contain other objects. For example, an invoice object may include both a customer and a lineitems object.
UI Layer
The UI, or presentation, layer can be anything that presents an interface to the user and talks to the business layer. VFP or VB forms, Excel documents, and HTML or DHTML documents (usually served up by ASP or some other Web server process) are all typical clients. In our contact management scenario, one client might be a VFP form that's part of an app for local users, and another might be an HTML page displayed in a browser at remote offices. Both of these clients get a record from the customers table via the business object, display it, and allow the user to edit it and save the changes. The business object will validate the data and either inform the UI client that there's a problem with the data, or submit it to the data object to update the data store.
Contacts Design
Let's redesign our contact management application using an n-tier architecture. Some people in our organization will use a VFP application for data entry, while others, because they're spreadsheet jockeys, will use Excel for data querying. Although I didn't create one, an ASP page would certainly be another useful example using this design.
Figure 1 shows the model for this design. UI Object is a placeholder for any UI layer object; it has references to a business object called Customer and an ADO RecordSet. Customer is a subclass of BusinessClass, an abstract business object, and provides the business layer for customer records. Another business object, Orders, isn't shown in this diagram. BusinessClass has a reference to a data class called DataClass, which provides data layer services. DataClass maintains a reference to an ADO Connection object.
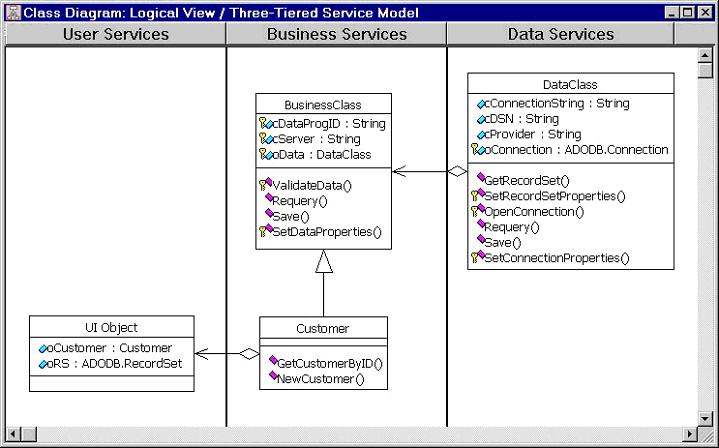
This model consists of the following tiers:
- UI: This could be a VFP form, Excel spreadsheet, ASP page, etc.
- Business: Implements business rules for customers and orders and acts as a middle tier between the UI and data layers.
- Data: Provides data handling services. This actually consists of several sub-tiers: DataClass (the data object), ADO (for data access), and the DBMS which actually stores the data (the Jet engine for this example).
Let's look at these tiers in more detail. Source code for this article is available from the Technical Papers page of www.stonefield.com. Because of space limitations, we won't look at all the code in this article; please refer to the source code for details.
Data Layer
DataClass (in LAYERS.VCX) is based on COMBase (see sidebar) and uses ADOVFP.H as its include file. This class uses ADO as the mechanism to marshal records between itself, the business layer, and data sources. It keeps a reference to an ADO Connection object, so it can talk to the data source. However, it doesn't maintain any reference to a RecordSet object. Instead, the business layer will pass a RecordSet into various methods of DataClass.
DataClass is marked OLEPublic, making it a COM object, because although it can be subclassed for additional behavior, it's a usable class by itself.
The Init method simply creates an ADO Connection object into the oConnection property:
PROCEDURE Init
This.oConnection =;
createobject('ADODB.Connection')
ENDPROC
The Destroy method closes and destroys the connection:
PROCEDURE Destroy
with This
if .oConnection.State = adStateOpen
.oConnection.Close()
endif .oConnection.State = adStateOpen
.oConnection = .NULL.
endwith
ENDPROC
The protected OpenConnection method is responsible for opening the connection to the data source if it isn't already open. In this class, there are two ways you can specify what data source to open: by setting the cDSN property to an ODBC data source name, or by setting the cProvider and cConnectionString properties to an OLE DB Provider and connection string, respectively. OpenConnection calls the protected SetConnectionProperties method to set some properties of oConnection (this method could be overridden in a subclass to set additional properties), then opens the connection and returns .T. if successful.
PROTECTED PROCEDURE OpenConnection
local llReturn
with This
* If the connection isn't already open, open it.
if .oConnection.State <> adStateOpen
* Set properties of the connection object first.
.SetConnectionProperties()
* If we aren't using a DSN, the Provider and
* ConnectionString properties of the connection
* object have been set, so open the connection.
* Otherwise, use the DSN to open the connection.
if empty(.cDSN)
.oConnection.Open()
else
.oConnection.Open(.cDSN)
endif empty(.cDSN)
* Return .T. if the connection was opened.
llReturn = .oConnection.State = adStateOpen
else
llReturn = .T.
endif .oConnection.State <> adStateOpen
endwith
return llReturn
ENDPROC
GetRecordSet fills an ADO RecordSet object with records, using the specified command. Rather than creating and returning a RecordSet itself, it accepts the RecordSet to work with as a parameter. GetRecordSet first ensures that the connection is open, then cancels any pending changes and closes the RecordSet if it was open. It then connects the RecordSet to the data source, calls the protected SetRecordSetProperties method to set some properties of the RecordSet (this method could be overridden in a subclass to set additional properties), and opens the RecordSet. It then disconnects the RecordSet and returns .T. if the RecordSet was successfully opened.
PROCEDURE GetRecordSet
lparameters toRS, tcCommand, tnCursorLock
local lnCursorLock, llReturn
with This
* Open the connection if necessary. If we succeeded,
* carry on.
if .OpenConnection()
.ResetError()
* If the lock wasn't passed, use the default value (optimistic).
lnCursorLock = iif(vartype(tnCursorLock) = 'N', ;
tnCursorLock, adLockOptimistic)
* If the recordset is already open, close it.
if toRS.State = adStateOpen
toRS.CancelBatch()
toRS.Close()
endif toRS.State = adStateOpen
* Set properties of the recordset, then open it.
toRS.ActiveConnection = .oConnection
toRS.LockType = lnCursorLock
.SetRecordSetProperties(toRS)
toRS.Open(tcCommand)
* Disconnect the recordset.
toRS.ActiveConnection = .NULL.
llReturn = toRS.State = adStateOpen
* We couldn't open the connection, so return .F.
else
llReturn = .F.
endif .OpenConnection()
endwith
return llReturn
ENDPROC
The Save method updates the data source with changes in the passed RecordSet. Like GetRecordSet, it first ensures that the connection is open, then determines how to save the RecordSet; if the RecordSet uses batch optimistic locking, the update is wrapped in a transaction. The RecordSet is connected to the data source, and either Update or UpdateBatch is used to update the data source. If the update fails, Cancel or CancelBatch is used to undo the changes. Then the RecordSet is disconnected again and a value indicating success or failure is returned.
PROCEDURE Save
lparameters toRS
local llReturn
with This
* Open the connection if necessary. If we succeeded,
* reset the error flag and determine how to save the recordset.
if .OpenConnection()
.ResetError()
do case
* If we have a batch optimistic recordset, start a
* transaction, do a batch update, and either commit or
* rollback as necessary.
case toRS.LockType = adLockBatchOptimistic
.oConnection.BeginTrans()
toRS.ActiveConnection = .oConnection
toRS.UpdateBatch()
if .lErrorOccurred
.oConnection.RollbackTrans()
toRS.CancelBatch()
else
.oConnection.CommitTrans()
endif .lErrorOccurred
toRS.ActiveConnection = .NULL.
* If we have an optimistic recordset, update it.
case toRS.LockType = adLockOptimistic
toRS.ActiveConnection = .oConnection
toRS.Update()
if .lErrorOccurred
toRS.Cancel()
endif .lErrorOccurred
toRS.ActiveConnection = .NULL.
* We don't have an updatable recordset, so raise an error.
otherwise
error 'The recordset is not updatable.'
endcase
llReturn = not .lErrorOccurred
else
llReturn = .F.
endif .OpenConnection()
endwith
return llReturn
ENDPROC
The Requery method (we won't look at it here) connects to the data source and requeries the passed RecordSet.
Business Layer
BusinessClass (in LAYERS.VCX) is based on COMBase. This class doesn't know anything about data; it has no connection to any data source and doesn't maintain a reference to a RecordSet. It's simply a go-between for clients and the data layer to ensure that business rules are satisfied. It keeps a reference to a DataClass object.
Because it must be subclassed to implement the exact business rules needed, BusinessClass is not marked OLEPublic (so it's not a COM object).
The Init method instantiates a DataClass object into its protected oData property. The ProgID for the object is stored in the cDataProgID property; if the object exists on a different machine (that is, the object should be instantiated using DCOM), the cServer property should contain the name of the server. After instantiating the object, the SetDataProperties method is called to set properties of the data object. This method could be overridden in a subclass to, for example, tell DataClass what data source it should connect to, in case you don't want to create a subclass specifically for a given data source.
Although the Init method of a COM object can't receive parameters, if this class is instantiated as a VFP class (usually for debugging purposes), it'll accept a ProgID for the data class. That way, although cDataProgID may be set to something like Contacts.DataClass, you can pass DataClass to have that class instantiated as a VFP object. This makes it possible to debug both the business and data objects in VFP, which is next-to-impossible to do if they're instantiated as COM objects.
PROCEDURE Init
lparameters tcProgID
local lcDataProgID
with This
lcDataProgID = iif(vartype(tcProgID) = 'C' and ;
not empty(tcProgID), tcProgID, '')
do case
case not empty(lcDataProgID)
.oData = createobject(lcDataProgID)
case empty(.cServer)
.oData = createobject(.cDataProgID)
otherwise
.oData = createobjectex(.cDataProgID, .cServer)
endcase
.SetDataProperties()
endwith
ENDPROC
The Save method accepts a RecordSet object and calls the protected ValidateData method (abstract in this class) to ensure that the data is valid. If so, the Save method of the data object is called to do the actual work of updating the data source. If that method fails, the data object's cErrorMessage property is put into this object's cErrorMessage property, so a client can see what went wrong. The method returns a value indicating success or failure.
PROCEDURE Save
lparameters toRS
local llReturn
with This
.ResetError()
do case
* Validate the recordset. If it failed, return .F.
case not .ValidateData(toRS)
llReturn = .F.
* Have the data object save the recordset. If it failed,
* get the error message and return .F.
case not .oData.Save(toRS)
.cErrorMessage = .oData.cErrorMessage
.lErrorOccurred = .T.
llReturn = .F.
* Everything worked, so return .T.
otherwise
llReturn = .T.
endcase
endwith
return llReturn
ENDPROC
The Requery method simply passes the RecordSet to the Requery method of the data object.
That's it for the code in this class. You'll need to subclass it to implement specific methods and business rules for your requirements. Let's look at a couple of subclasses: Customer and Orders.
Customer (in CONTACTS.VCX) is designed to work with records from the Customers table in the Access Northwind sample database that comes with Visual Studio. It's marked as OLEPublic because it's a COM object. cDataProgID is set to Contacts.DataClass so it uses the DataClass data object built into the same DLL. The SetDataProperties method sets the provider and connection string for the data object. For demo purposes, I put code into ValidateData to not allow a fax number of 999-999-9999; obviously, a real class would have real rules in this method.
I added a couple of new methods to this class. GetCustomerByID accepts a RecordSet and an ID value, then uses the GetRecordSet method of the data object to fill the RecordSet with all fields from the Customers table for the specified customer number. It returns .T. if the record was found, and .F. if not found, or if something went wrong (if it returns .F., cErrorMessage will be empty if it simply didn't find a matching record). NewCustomer accepts a RecordSet and puts an empty customer record into it. It uses GetCustomerByID, passing it a non-existent key value, so the RecordSet will have the correct structure, then uses the AddNew method of the RecordSet to create the new record.
Orders (in CONTACTS.VCX) is designed to work with records from the Orders and Order Details tables in the Northwind database. Like Customer, it's marked OLEPublic, cDataProgID is set to Contacts.DataClass, and SetDataProperties sets the provider and connection string for the data object (although it uses the MSDataShape provider since this class creates hierarchical RecordSets).
This class has one custom method, GetOrdersForCustomer, that accepts a RecordSet and a customer ID, and fills the RecordSet with a hierarchical cursor of orders and order details.
UI Layer
To show how the business class layer can be used with any kind of UI layer, I created three examples of different clients. The first one, TESTBUSINESS.PRG, does everything in code and displays results only through MESSAGEBOX dialogs. It first gets and displays the record for the ALFKI customer:
oBusiness = createobject('Contacts.Customer')
oRS = createobject('ADODB.RecordSet')
oBusiness.GetCustomerByID(oRS, 'ALFKI')
messagebox('Found customer ALFKI: ' + ;
trim(oRS.Fields('CompanyName').Value))
Next, it tries the change the fax number to 999-999-9999, which isn't allowed by the business object, so an error is displayed:
oRS.Fields("Fax").Value = '999-999-9999'
llOK = oBusiness.Save(oRS)
if not llOK
messagebox("Cannot save change to customer ALFKI:" + chr(13) + chr(13) + oBusiness.cErrorMessage)
endif not llOK
It then creates a new customer and saves it:
oBusiness.NewCustomer(oRS)
oRS.Fields("CustomerID").Value = "STONE"
oRS.Fields("CompanyName").Value = "Stonefield Systems Group Inc."
oBusiness.Save(oRS)
Finally, it deletes the new record:
oRS.Delete()
oBusiness.Save(oRS)
The second example is a VFP form, CONTACTS.SCX, shown in Figure 2. This form has a pageframe with two pages. The first page has controls bound to fields in the RecordSet referenced in the oRS property of the form (for example, txtCompanyName has Thisform.oRS.Fields('CompanyName').Value as its ControlSource). The second page has a Microsoft Hierarchical FlexGrid which displays the hierarchical orders data in the oOrderRS RecordSet. The Load method of the form instantiates the oRS and oOrderRS RecordSets as well as Customer (oCustomer) and Orders (oOrders) business objects.
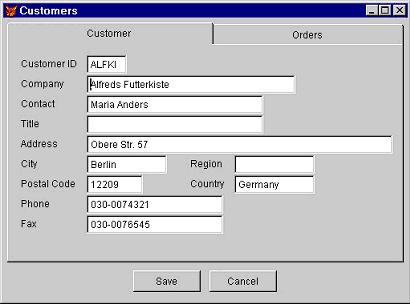
Note that in this case, these objects are instantiated as VFP classes rather than COM objects, just to show how debugging can be done. The Valid method of txtCustomerID uses oCustomer.GetCustomerByID to fill oRS with information for the specified customer and oOrders.GetOrderForCustomer to fill oOrderRS with information about orders for that customer. If the customer isn't found and you choose “Yes” when asked if you want to create a new customer, the NewCustomer method of the form calls oCustomer.NewCustomer to create an empty RecordSet. Save and Cancel buttons allow you to save or cancel changes.
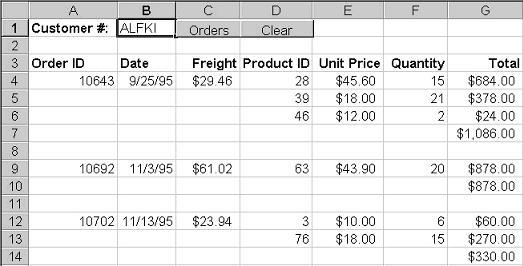
The final example is an Excel spreadsheet, ORDERS.XLS, that displays the orders for the specified customer and calculates totals. The GetOrders macro, fired when you click on the Orders button, instantiates RecordSet and Contacts.Orders objects and uses the GetOrdersForCustomer method to fill the RecordSet with orders for the customer number entered into cell B1. A loop then displays the contents of the RecordSet in the spreadsheet, totaling each order as it goes.
Summary
As developers, we need to move away from putting all of our eggs (UI, business rules, and data access) into one basket (form, PRG, etc.). Even applications that serve a small number of users on a LAN can benefit from an n-tier architecture, and will certainly be much easier to maintain, scale up, or deploy as an Internet application in the future. The biggest challenge for VFP developers in designing n-tier applications is learning not to put data access or business rules into the UI.
