


Basic error handling in SQL Server's programming language, Transact-SQL, is straightforward.
But when you nest calls to stored procedures, and the procedures have SQL transactions, error handling becomes much more complex. In this article I'll show you some tried-and-true models for how to handle errors in nested stored procedures with transactions.
Over the past year I've worked on two projects that needed a strategy for handling errors in stored procedures where the procedures used transactions. My task was to come up with a way to gracefully exit from the stored procedures when non-fatal errors were detected so I could roll back the transaction. I'll present the result of that work in the two models you'll learn about in this article.
So how do you handle errors in your code when an error occurs? Unless it encounters a broken connection, SQL Server will return an error to the client application. When you work directly with your own client or middle-tier code, you have much more control over how you handle errors. So you could just issue all your queries to SQL Server discretely from your client code and let SQL Server errors throw you into your error-catching logic, thereby keeping all your error handling in your own calling code. However, encapsulating database-oriented code in SQL Server stored procedures offers a more efficient and elegant solution. In those cases, you need to consider what to do when SQL Server errors occur.
Let's look first at some general features of error handling.
Transact-SQL Error Handling
Transact-SQL error handling techniques are simple, but SQL Server's error-returning behavior can seem confusing and occasionally inconsistent. You can trap some errors in Transact-SQL code, but other errors are fatal to a batch or transaction. When SQL Server encounters a non-fatal error trying to execute a command, the @@ERROR system function captures the error message. If the error is fatal, you cannot catch the error in Transact-SQL at all; you'll have to rely on your client code's catch logic.
If a trappable error occurs, the @@ERROR function will have a value greater than 0. SQL Server resets the @@ERROR value after every successful command, so you must immediately capture the @@ERROR value. Most of the time, you'll want to test for changes in @@ERROR right after any INSERT, UPDATE, or DELETE statement. I prefer to capture the value of @@ERROR into a variable immediately, so I can use it later, as in the following snippet:
DECLARE @Error int
...
UPDATE ...
SET @Error = @@ERROR
IF @Error > 0 ...
Because SQL Server resets the @@ERROR with the next successful command, when the IF statement in the code snippet successfully executes, SQL Server will reset @@ERROR back to 0. This can cause a problem if you're also interested in getting the row count of a command, because most commands will also reset the @@ROWCOUNT system. You can capture them both simultaneously using the SELECT statement as shown in the following snippet:
DECLARE @Error int, @Rowcount int
...
UPDATE ...
SELECT @Error = @@ERROR
,@Rowcount = @@ROWCOUNT
IF @Error > 0 ...
IF @Rowcount = 0 ...
You can also capture @@ERROR to test for SELECT errors, with some limitations. For example, you can trap an error if at runtime some object (table or view) referenced by the SELECT is missing (Transact-SQL error message 208.) However, syntax errors in the SELECT command, or any other error that causes compilation of a batch to stop, are fatal and cannot be trapped.
It's much more efficient and elegant to encapsulate database-oriented code in SQL Server stored procedures, so you need to consider what to do when errors occur in your stored procedures.
It's more useful to capture @@ERROR after INSERT, UPDATE, and DELETE statements because, by default, constraint violations are not fatal. Foreign key and check constraints will not be fatal (meaning they will not abort the batch or transaction) unless SET XACT_ABORT is ON (see the section on XACT_ABORT below.)
The number of possible error messages is very large; over 3,800 error messages are stored in the master database's sysmessages system table (some are actually templates). Unfortunately, only a small number of the error messages are documented in Books Online; you can often get more complete explanations of errors in the Knowledge Base.
You can use the RAISERROR statement to generate your own errors in Transact-SQL code. You can also define your own error messages, starting with number 50001, using the system stored procedure sp_addmessage, which will add a message to the sysmessages table. You can then reference the error message in the RAISERROR statement. However, most developers prefer to insert a string message into the RAISERROR statement, because adding custom messages to the sysmessages table creates an additional dependency of your database on a table outside the database, thereby making it less portable.
Batches and Stored Procedures
SQL Server compiles and executes its code in batches of commands. When you work with SQL Server scripts, you use the GO statement for separating batches (it is not really an executed command.) Every stored procedure, trigger, and user-defined function can each consist of only one batch. SQL Server has some important restrictions on batches. For example, you must make the CREATE PROCEDURE the first statement in a batch, so you can create only one procedure per batch.
It's possible that an SQL Server error may abort the current batch (stored procedure, trigger, or function) but not abort a calling batch. In this article, I will focus primarily on stored procedures, with some remarks about triggers in the context of transactions.
You should consider two major points when you work with SQL Server stored procedures and errors:
- Does an SQL Server error abort a called batch or stored procedure?
- Does the error abort a set of nested (called) stored procedures?
Transactions
If you encapsulate any of your operations in database transactions, some errors will abort a transaction while others will not. When working with transactions, consider the following questions:
- Does the error abort the transaction?
- What type of transaction is it?
- Is the XACT_ABORT setting on?
When SQL Server aborts a transaction, it also aborts the current and calling batches or stored procedures. SQL Server has three types of transactions: Autocommit, Explicit, and Implicit.
Autocommit: All data-modification statements such as INSERT, UPDATE, and DELETE occur in a transaction. If you do not explicitly declare a transaction, or if you use an implicit transaction, SQL Server automatically uses a transaction for those commands. That is the autocommit mode. SQL Server ensures these data-modification commands either completely succeed or completely fail. If you UPDATE a million rows, and SQL Server cannot complete the UPDATE, it will not leave the database only partially updated. This keeps the database in a consistent state and assures the atomicity of the transaction. That is, all the steps of a transaction as a group must complete, or everything gets rolled back.
The number of possible error messages is very large; over 3,800 error messages are stored in the master database's sysmessages system table. Unfortunately, only a small number of the error messages are documented in Books Online.
Explicit: You can explicitly begin a Transact-SQL transaction with BEGIN TRANSACTION, optionally label it, and end the transaction with either COMMIT TRANSACTION or ROLLBACK TRANSACTION?but not both. A COMMIT statement instructs SQL Server to commit your changes, while a ROLLBACK statement results in all changes being removed. SQL Server can do this because it first writes all data changes to the transaction log before it changes any actual database data. If SQL Server needs to restore any data to its original state because of an error or a ROLLBACK, it can recover that data from the transaction log.
When you explicitly begin a transaction, the @@TRANCOUNT system function count increases from 0 to 1; when you COMMIT, the count decreases by one; when you ROLLBACK, the count is reduced to 0. As you see, the behavior of COMMIT and ROLLBACK is not symmetric. If you nest transactions, COMMIT always decreases the nesting level by one, as you can see illustrated in Figure 1. The ROLLBACK command, on the other hand, rolls back the entire transaction, illustrated in Figure 2. This asymmetry between COMMIT and ROLLBACK is the key to handling errors in nested transactions.
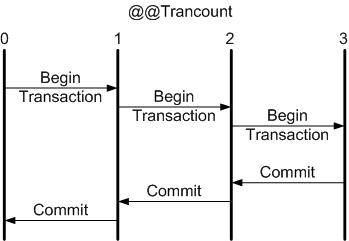
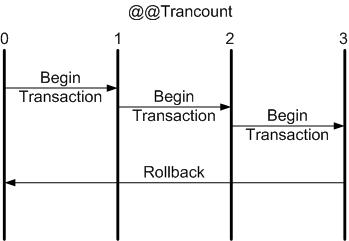
Some SQL Server errors will abort a transaction and some will not. There may be some errors that you want to detect using @@ERROR and roll back yourself, so often the error logic in Transact-SQL contains a ROLLBACK statement.
Implicit: If you want all your commands to require an explicit COMMIT or ROLLBACK in order to finish, you can issue the command SET IMPLICIT_TRANSACTIONS ON. By default, SQL Server operates in the autocommit mode; it does not operate with implicit transactions. Any time you issue a data modification command such as INSERT, UPDATE, or DELETE, SQL Server automatically commits the transaction. However, if you use the SET IMPLICIT_TRANSACTIONS ON command, you can override the automatic commitment so that SQL Server will wait for you to issue an explicit COMMIT or ROLLBACK statement to do anything with the transaction. This can be handy when you issue commands interactively, mimicking the behavior of other databases such as Oracle.
What's distinctive about implicit transactions is that reissuing SET IMPLICIT_TRANSACTIONS ON does not increase the value of @@TRANCOUNT. Also, neither COMMIT nor ROLLBACK reduce the value of @@TRANCOUNT until after you issue the command SET IMPLICIT_TRANSACTIONS OFF. Developers do not often use implicit transactions; however, there is an interesting exception in ADO. See the sidebar, Implicit Transactions and ADO Classic.
The XACT_ABORT Setting
You can increase the number of errors that will abort a transaction by using the following setting:
SET XACT_ABORT ON
Though seldom used, when XACT_ABORT is ON, errors associated with a data modification statement cause the entire transaction to abort. Recall that constraint violations are normally non-fatal errors. With XACT_ABORT on, they become fatal to the transaction and therefore to the entire set of stored procedures, triggers, or functions involved.
When will you use the XACT_ABORT setting? When you use Microsoft Distributed Transaction Coordinator (MS DTC) to enlist distributed transactions from any of the SQL Server ADO, ODBC, or OLEDB drivers, you cannot use nested transactions. Knowledge Base article 306649 "PRB: Error When You Implement Nested Transaction with OLE DB Provider for SQL Provider" describes this problem. The KB article recommends issuing the command XACT_ABORT ON to get around the nested transactions limitation. XACT_ABORT ON will cause failures in an INSERT, UPDATE, or DELETE statement to abort the transaction. However, there are numerous other non-fatal errors that can occur, so it does not remove the need for error handling.
Nesting Stored Procedures and Transactions
Nesting stored procedures and transactions present a special challenge, and SQL Server has additional rules and behavior changes to work with them. Some techniques that may work with just one stored procedure call, or one transaction level, will not work in a deeper nesting level.
An Error Behavior Matrix
To get an idea of what you're up against, Table 1 illustrates some common errors and how they behave with nested stored procedures and transactions.
I chose the error message samples in Table 1 to illustrate the varying effects that errors can have on a stored procedure or a transaction.
A lock timeout error occurs if you use a value for SET LOCK_TIMEOUT that is lower than the indefinitely long value, and a query times out. Note that the lock timeout error is not fatal, but if an INSERT, UPDATE, or DELETE error occurs, you may indeed want to abort the stored procedure or transaction yourself.
The constraint violations listed in Table 1 include foreign key and check constraint violations. When you use the command SET XACT_ABORT ON, these errors will abort the transaction. Table 2 shows how constraint violations change with XACT_ABORT ON.
The behavior of COMMIT and ROLLBACK is not symmetric.
An invalid object error will abort the current batch, so you cannot trap it. However, it will not abort the calling batch and it will not abort a transaction. If one stored procedure calls another and the called procedure fails because of an invalid object reference, the calling procedure continues to execute. Right after the failed call to the procedure, use @@ERROR to indicate that a failure occurred.
Some Rules for Handling Errors with Nested Stored Procedures
Nesting stored procedures means you have stored procedures that call stored procedures; each stored procedure may or may not have a transaction. To trap non-fatal errors in a called stored procedure, the called procedure must have some way to communicate back to the calling procedure that an error has occurred. To do this, pass a value back via the RETURN statement, or use an OUTPUT parameter. Either way works, but once you adopt a method, all the procedures in a system must use it. In this article, I'll use the RETURN statement and adopt the convention that a stored procedure returns a 0 for success and a -1 for a failure that is serious enough to abort a transaction and signal that the calling procedure should abort as well.
As you saw earlier (see Figure 1 and Figure 2), you can nest transactions and use the @@TRANCOUNT system function to detect the level. You also learned that COMMIT and ROLLBACK do not behave symmetrically; COMMIT just decreases the value of @@TRANCOUNT, while ROLLBACK resets it to zero. The implication is that a transaction is never fully committed until the last COMMIT is issued. No matter how deep you nest a set of transactions, only the last COMMIT has any effect.
When you issue COMMIT or ROLLBACK in any Transact-SQL code, and there is no transaction in effect, SQL Server will return the non-fatal error 3903, "The COMMIT TRANSACTION request has no corresponding BEGIN TRANSACTION." You can avoid this error by making sure you don't issue a COMMIT or ROLLBACK unless a transaction is really in effect. You can do this by testing the @@TRANCOUNT level, as ADO does (see the sidebar, "SQL Server Transactions and ADO: Good News and Bad News"). In other words, instead of issuing unconditional COMMIT or ROLLBACK, qualify them:
IF @@TRANCOUNT > 0
COMMIT
This will help ensure that you never issue a COMMIT or ROLLBACK without a transaction in place.
Suppose stored procedure P1 calls procedure P2. P1 begins a transaction (@@TRANCOUNT's value is 1) and calls P2, which also begins a transaction ((@@TRANCOUNT's value is now 2). Issuing a COMMIT in P2 will have no effect because P1 might still roll the transaction back. The bottom line:
Only the COMMIT at the outermost level of a set of nested transactions actually commits the transaction.
A ROLLBACK is an entirely different matter. Transact-SQL has an added condition: Every stored procedure must end with the same transaction count with which it entered. If the count does not match, SQL Server will issue error 266, "Transaction count after EXECUTE indicates that a COMMIT or ROLLBACK TRANSACTION statement is missing." This error is non-fatal; however, you should avoid this error because it returns an error to the Client.
So now you have a second rule:
If a stored procedure does not initiate the outermost transaction, it should not issue a ROLLBACK.
The upshot is that a transaction should be rolled back at the same level at which it was started, so only the calling procedure that starts a transaction should ever roll back. If the client code started the transaction, none of the procedures should roll back.
One final consideration: When an error occurs that aborts a transaction, the current and all calling batches abort as well. This occurs when you get a deadlock (see Table 1). It also occurs when a ROLLBACK occurs in a trigger. So far, I haven't seen any instances where a transaction was aborted but the procedures were not.
With these observations and rules in mind, I'll now show you two models of how you could implement error handling in nested stored procedures with transactions. I'll call them the single-level and multi-level models.
The Single-Level Model
In the single-level model, if a transaction is already in place, the procedure will not start a new one; instead, the transaction level remains unchanged (i.e., at a single level). If it has to roll back and it did not start the transaction, the procedure raises an error and returns an error message to the caller. In this model, the procedures do not take the transaction level beyond 1.
The basic strategy for the single-level model is to start by declaring a local variable to record whether this procedure should begin a transaction or not. If the transaction count is 0 when the transaction starts, the procedure issues a BEGIN TRANSACTION.
If you call another stored procedure, you should capture both the return value of the stored procedure and the value of @@ERROR. If the return value from the called procedure is -1, or if @@ERROR was greater than 0, the procedure assumes that an error has occurred that requires us to stop further processing and exit through an error path. If the return value from the called procedure is -1, the called procedure has already raised an error so there's no need to raise one again. However, if the stored procedure call failed, or there was a non-trappable error in the called procedure, you should raise an error and report it to the caller so that you'll know what procedure actually failed.
A stored procedure transaction should be rolled back at the same level at which it was started, so only the calling procedure that starts a transaction should ever roll back.
If the stored procedure has its own critical event, such as an INSERT, UPDATE, or DELETE, then you should test that command. Again, capture the value of @@ERROR; if it is greater than zero, the procedure should abort its processing. In this case you should raise an error indicating where the problem occurred, and exit through the error path.
In the procedure's error exit path, you test whether this procedure began a transaction. If it did, then the procedure issues a ROLLBACK, In either case the procedure should RETURN a -1 to tell a calling procedure that it should also exit through its error exit path.
When no errors occur, the procedure should exit through a normal exit path; if it started a transaction, the procedure should COMMIT and return a 0. If it did not start a transaction, there's no need to issue a COMMIT.
Listing 1 contains the outline of a stored procedure using the single-level model.
Listing 1 shows the code for the outermost procedure, but the same code works at any level. If a procedure is at the innermost level of a set of nested procedures, you can remove the code that traps for calling a stored procedure.
If a procedure does not begin a transaction, set the @LocalTran flag to 0. The procedure will never execute either a COMMIT or a ROLLBACK, but will still trap for errors calling other stored procedures and exit out its error path (the ErrExit label) if it detects a failure from called procedures.
I've used this model in production a couple times now, and it works well. When SQL Server returns errors from low in the procedure nesting, the error messages help to easily pinpoint the location.
The Multi-Level Model
SQL Server MVP Fernando Guerrero pointed out to me that there is an alternative approach that does permit transaction nesting. The overall algorithm is very similar. In the multi-level model, a procedure may begin a new transaction; but if it detects the need to roll back and the @@TRANSACTION value is greater than 1, it raises an error, returns an error message to the caller, and issues a COMMIT instead of a ROLLBACK. The multi-level model allows transaction levels to increase.
Both models only roll back a transaction at the outermost level. While the multi-level model explicitly begins a transaction, it makes sure that every procedure below the outermost one issues a COMMIT rather than a ROLLBACK, so the @@TRANCOUNT level is properly decremented even if the procedures are all exiting through their error path.
In this model, you do not need to keep track of whether this procedure began a transaction. Instead, just issue the BEGIN TRANSACTION. The error handling for calling other stored procedures and issuing critical commands remains the same.
If the procedure exits via its normal exit path, it should just issue a COMMIT and return a 0. But if the procedure exits out its error path (through its ErrExit label), there are two options. If the value of @@TRANCOUNT is greater than 1, this procedure did not initiate the transaction, so it should just COMMIT and return a -1. If @@TRANCOUNT is exactly 1, this procedure did initiate the transaction, so it issues a ROLLBACK and returns -1.
Listing 2 shows sample code using this strategy.
Again, if you are not calling other procedures, you can just remove the related code. However, if you are not using a transaction in this procedure, you'll also need to remove the COMMIT and ROLLBACK conditions from the code.
Comparing the Two Models
What's interesting about both models is that they can inter-operate. Both follow the rule that they will not roll back a transaction if they did not initiate it, and they both always leave the transaction level of a stored procedure the same as when they entered the transaction.
The advantage of the multi-level approach is that you can use code that is somewhat simpler. The advantage of the single-level approach is that you can easily turn the transaction handling on or off without removing or commenting out lines of code.
I've used the single-level model in two applications and it is working fine. Whichever model you choose, you'll have a solid approach to handling Transact-SQL errors in nested procedures that use transactions.
