





Testing computer software is more than just randomly executing portions of the software.
Professional-level testing uses industry-accepted practices to write tests that are the most likely to find bugs. This article will examine how to use a combination of several common testing methods to maximize the results of the time you spend on testing.
“A test that reveals a problem is a success. A test that did not reveal a problem was a waste of time.” ? Kaner
Software test teams are often referred to as Quality Assurance teams, and rightfully so. Our job is to make sure we find as many defects (bugs) as possible, and see that they get fixed before the product gets into the hands of the customer. However, we cannot find all of the bugs, so we need to choose our test cases carefully, ensuring that they find the highest possible number of bugs. Cem Kaner in his book, Testing Computer Software, says, “A test that reveals a problem is a success. A test that did not reveal a problem was a waste of time.” In *Effective Testing Strategies * in last month's Component Developer Magazine, Ellen Whitney covered some of the processes and techniques involved with testing computer software. This article will drill a little deeper into some of the testing techniques and areas that can help you make the most of your testing time.
You will not find all of the bugs
There are some folks who think that if they have enough testers and enough time, all of the bugs in a software product can be found. This is a silly assumption that is easily dismissed when one considers the complexity of computer software. Think of the last non-trivial program you wrote. How many possible inputs were there? How many possible outputs? Now, how many combinations of those inputs and outputs were there? Throw in the number of places the code can branch because of an IF or CASE statement, and you can be testing for a long time to get complete test coverage.
In 1975, Glenford J. Myers, author of The Art of Software Testing, wrote a “trivial” piece of code that would amount to about 20 lines in most languages. It had a few pieces of branching code, a loop, and that's about it. Myers calculated that it had 100 trillion different code paths. He estimated that a fast tester could test every possible code path in about a billion years.
Software can often fail after a number of iterations. Memory leaks add up and cause crashes, or sometimes something will fail after 1024 times, which just happens to be a whole hexadecimal number. But, you can't find all of those bugs, either. You can test something through a million iterations, but you would not have found the bug that fails on the millionth and first iteration.
Risk-Based Testing
Since we cannot test everything, we then need to prioritize what we can test. Using risk-based testing, we look for the biggest bang for our testing buck. This involves a two-pronged approach. First, we need to establish which code is most at risk in terms of potential bugs. What makes code risky? Here are a few items that I use to prioritize areas of code to test.
New code - Anything that has not been previously tested has no known level of quality.
Changed code - It has been estimated that the process of fixing a bug stands a 60% chance of breaking something else.
Complex code - Large, intricate sections of code are not only hard to write; they are hard to test.
Highly-dependant code ? If a function or other piece of code is called from many places in the program, we need to make sure it is stable.
Buggy code - If a lot of bugs have been found in an area of the program, there are probably still more bugs to be found.
Failing code - If there are regression bugs in some recently written code, there may be other bugs.
Next, we need to assess the impact potential bugs would have on users. Potentially risky areas are as follows:
Frequently used - Bugs that users see every day give the impression of instability in the product.
Critical areas - Users may close the general ledger in your accounting application only once a month, but it is crucial that the numbers balance.
Strategic features - If there is a feature in the product that makes the product stand above the competition, it had better work.
Once the risks have been established, they can be placed in a matrix from which test cases can be written (Figure 1**).**

As with test plans and test cases, it is important that this be documented. Inevitably, bugs will be found after the product is shipped, and management is going to want to know why the bugs were missed. Along with your list of test plans and test cases, the risk matrix can be used to demonstrate where your efforts were directed.
Functional Testing
This is probably the area of testing in which you will spend the most time. Functional testing establishes that the program does what the specification says it will do. Functional test cases are also probably the easiest to write, since there will be a one-to-one relationship between items in the specification and the test cases that are written. A functional test sends in some input and checks the output.
Code coverage testing is important because if a section of code has not been tested, it's a safe bet you have not found the bugs in that code.
When interviewing potential testers, I spend some time during the interview asking the interviewee to test an imaginary function after being given the specification. Because it is commonly thought that software testers spend their days breaking software, interviewees often write a lot of test cases that attempt to break the function. However, they often forget to check that the function actually does what it is supposed to. Do not make this same mistake when you are testing your software. As Kaner says, “the reason the program is in test is because it probably doesn't work.”
Again, we can use a matrix (Figure 2) to assure that functional tests are not missed. Based on the specification or a list of conditions, a list of testing tasks can be assembled. It does not have to be anything fancy; it could be as simple as a spreadsheet, or even a text file written using Windows Notepad. It does not matter what tool you use to assemble your list of tests, just as long as you do it.

To minimize the number of tests that have to be written, restrict your testing to significant cases. For instance, I have a function written in Visual FoxPro that I frequently use to convert a 32-bit integer to an ASCII representation of that integer in low-high format.
******************
Function LongToStr
******************
* Passed : 32-bit non-negative numeric value
* (lnLongval)
* Returns : ascii character representation of
* passed value in low-high
* format (lsRetstr)
Parameters lnlongval
Private i, lcRetstr
lcRetstr = ""
For i = 24 To 0 Step -8
lcRetstr = Chr(Int(lnLongval/(2^i))) + lcRetstr
lnLongval = Mod(lnLongval, (2^i))
Next
Return lsRetstr
To test this function, I could pass in 100 and I could pass in 102. Though these cases are not identical, they're close enough that I would probably want to skip one of them. Since I have no reason not to expect the same result from both tests, there is no need to waste time writing both of them. So, how do you decide which tests are significant enough to write? One way is to use boundary conditions.
Boundary Testing
Because it is not possible to test every possible input, you can use boundary inputs to narrow the number of test cases. Boundary conditions exist when very near the limit of a particular function. In my Visual FoxPro example above, I could pass the function 4294967295 (the largest 32-bit integer) to make sure it handles the largest possible value. I could then pass it 4294967295 + 1, and see how it handles an integer that exceeds the limit (not very well, as it turns out).
In software written in a language that allocates its own memory, such as C++, the boundaries may be a whole hexadecimal number. For instance, the software may have a dialog that accepts text in a textbox. If the developer only allocated 255 bytes to hold the string, and yet did not limit the textbox to 255 characters, it may be possible to crash the application by entering 256 characters into the text box. Entering 256 characters would be our boundary test.
There will be other boundary conditions that are not based on the allocation of memory. For instance, I got burned years ago when I did not boundary test part of an application I wrote for a client. Part of this client's business involved the sale of ¼ acre plots of land for residential housing. About the time I wrote this application, I had purchased a house sitting on a whole acre of land for about US$85,000. Therefore, I reasoned that a five-digit field to hold the price of a ¼ acre lot (with no house) ought to be enough for anybody. When the user went to enter the price of the first lot, which sold for well over US$100,000, the application failed in a spectacular fashion.
Boundary testing is best done by exceeding the boundary by one. If the application is going to fail anywhere past the boundary, it is going to fail at the boundary plus one, so further testing beyond the boundary is not necessary.
Code Coverage
Functional testing goes a long way toward assuring the stability of software, but it has a short-coming: it does not tell you if you have tested all of the code. Code coverage is the process of getting information on how much of the code your tests execute. This is important, because if a section of code has not been tested, it's a safe bet you have not found the bugs in that code. Visual FoxPro has a coverage profiler that is included with the product. There also tools from companies such as Rational (Pure Coverage), Bullseye Testing Technology (C-Cover) and NuMega (TrueCoverage) that provide code coverage analysis for Visual Basic, Visual C++, and other languages.
The program had a few pieces of branching code, a loop, and that's about it. Myers calculated that it had 100 trillion different code paths.
Typically, coverage profiling involves running your tests while a coverage profiler is running. Once your tests are complete, the coverage profiler will provide you with information about which lines of code your tests executed. Figure 3 illustrates how the Visual FoxPro Coverage Profiler marks lines of code that have been executed. The lines with vertical marks next to them have been executed; the ones without the mark have not. If there are lines of code that have not been executed, then tests need to be written to execute that code. A tester may have to work with a developer to find out how to get the code to execute. The tester may also find that there simply is no way to get to that code path.
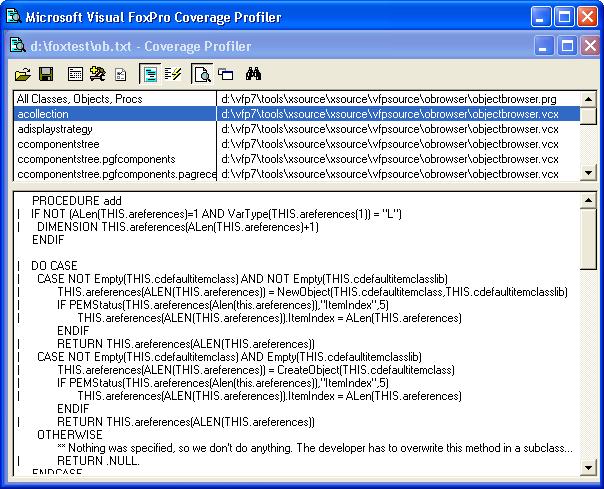
For a quick overview of how well your tests cover the code, most code coverage products will summarize the statistics (Figure 4). This is useful for a summarized report to management, for instance. Keep in mind that it is rare that you will hit 100% coverage. As a preventative measure, developers will frequently write code for conditions that theoretically should never occur, leaving you short of 100% coverage. Testers will need to work with the development team to determine a satisfactory percentage of coverage.
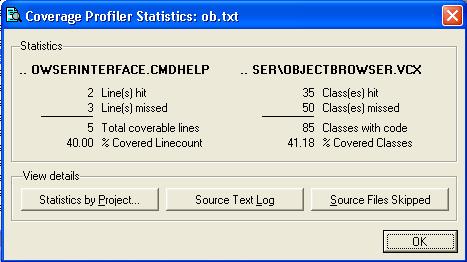
Once you reach a certain level of test coverage, do not make the mistake of thinking that you are done testing. Code coverage testing can tell you how much of the existing code you have executed, but it will not tell you about the missing code that will cause bugs. Functional testing is still required to find out what has been left out.
Exploratory Testing
With this type of testing, you are walking through the product, figuring out how to use it and how to test it. It is often the first testing that is done to a product because the testers are still learning how to use it. Exploratory testing takes more of a systematic approach than what is commonly known as “ad hoc” testing or “guerrilla testing.” Exploratory testing can be directed toward specific areas of the product, along with specific tasks and deliverables (say, a test plan that assesses how risky an area is).
Combining the
testingmethods in this article can give you a head start toward getting the most test coverage with the least amount of effort.
Unlike with functional testing, when doing exploratory testing you do not know up front what that testing will be. You are designing your tests, then immediately executing them, and the results can determine the direction future testing will take. If, while doing exploratory testing, you find a bug or do not get the results you expect, that may change the direction of your efforts. This is because the results may cause you to think about how a particular area of a program works, and change your thinking about that area and how to test it. On the other hand, if you do not find any problems with a particular area of the product, you may decide to move on to something else.
A tester may write down notes about how to go about testing the product and interesting ideas on what to try. Since these notes are written up front, this may look like scripted testing, but it's not. In fact, the reverse is true. When a problem is found, the steps to reproduce the problem are recorded, and thus a script is written.
The biggest disadvantage to exploratory testing is that large sections of the product may be missed. However, you will be doing this in conjunction with your functional testing and code coverage testing, right?
Regression Testing
Regression testing is done after bugs are fixed to make sure nothing was broken after changing the code. One figure I've seen stated is that there's a 60% chance of a bug fix breaking something else. It's a percentage I'm skeptical of, based on experience, but the point is that you can break other things while fixing bugs. After a new build, you can rerun your tests and make sure that not only the original bug was fixed, but that everything else works as expected. Regression testing is not very exciting, and it does not find a lot of bugs, but it needs to be done when code has changed.
Automation
Because regression testing gets to be horribly boring after a while, you should automate your tests at every opportunity. There are several good automation tools from Rational, Mercury Interactive and NuMega. There is also an automation tool included in Visual FoxPro 7.0, in the Tools/Test directory under the VFP directory (Figure 5).
Be careful how you write your automation tests. Automated tests should be self-verifying, meaning that someone should not have to look at the actual script to determine why a particular test passed or failed. The test log should say something meaningful, such as:
EXPECTED: return value of 10 from CalcDays()
RECEIVED: 12, test failed
If at all possible, any data that your tests need should be generated on the fly. If you make assumptions about the state of the data, it is possible that a previous test made changes to that same data, and your assumptions fail. If creating data at testing time is not possible, remember to account for the fact that data may not be static.
Just as with code in your product, I would recommend using a standard header and change marker in your test scripts. A tester who writes a test today may not be around next week and it is nice to be able to look at the comments and get an idea about what is going on.
Summary
No one, single testing technique can adequately test a software product, because testing computer software consists of more than just randomly pounding on a keyboard. Using systematic approaches to testing your software products can bring great gains in product stability. The testing methods above are by no means an exhaustive list of how you should test your application. You may still need to consider stress testing and performance testing, to make sure your application is robust enough for multiple users. However, combining the testing methods in this article can give you a head start toward getting the most test coverage with the least amount of effort.
