


At the JAOO conference in Aarhus, Denmark this year, domain specific languages came up in virtually every conversation.
Every keynote mentioned them, a lot of sessions discussed them (including a pre-conference workshop by Martin Fowler and myself), and you could hear “DSL” in most of the hallway conversations. Why this, and why now?
To hear some people, DSLs solve world hunger, cure cancer, and make software write itself. Perhaps this is a bit of an exaggeration. DSLs are really nothing more than an abstraction mechanism. The current interest lies in the dawning realization that some abstractions resist easy representation in modern languages like C#. For the last 20 years or so, ’developers have used objects as their primary abstraction mechanism. Objects work really well because it turns out that much of the world is hierarchical. But edge cases still pop up. For example, what about querying relational data in a way that fits the object paradigm nicely? Of course, LINQ provides an elegant solution to that problem. And it’s a DSL, one for building queries for structured data in a way that fits in nicely with C#.
A more formal definition appears later, but, for now, a working definition for a Domain Specific Language is a computer language limited to a very specific problem domain. In essence, a DSL is an abstraction mechanism that allows very concise representations of complex data. This article covers some definitions of what constitutes a DSL, what kinds of DSLs exist, and how to build a particular type of DSL known as a fluent interface. First, though, let me define some terms.
Does Starbucks Use a DSL?
DSLs use language as an abstraction mechanism the way that objects use hierarchy. One of the challenges when you talk about an abstraction mechanism as flexible as language lies with defining it. The thing that makes a DSL such a compelling abstraction is the parallel with a common human communication technique, jargon. Here’s a pop quiz. What “languages” are these?
- Venti, half-caf no foam latte with whip
- Scattered, smothered, and covered
- Just before the Tea Interval, the batsman was out LBW.
The first is easy: Starbucks. The second you probably only know if you’ve ever eaten at a Waffle House: it’s the way you order hash browns (the Waffle House hash brown language consists of eight keywords, all transitive verbs: scattered, smothered, covered, chunked, topped, diced, peppered, and capped). I hear something like the third example all the time because I have lots of colleagues who play cricket, but it makes no sense to me. And that’s really the point: people have created jargon as a short-hand way to convey lots of information. Consider the Waffle House example. Here’s an alternative way to order hash browns:
There is a plant called a potato, which is a tuber, a root plant. Take the potato, harvest it, wash it off, and chop it into little cubes. Put those in a pan with oil and fry them until they are just turning brown, and then drain the grease away and put them on a plate. OK, next I want cheese. There’s an animal called a cow...
Don’t ever try to order hash browns like this in a Waffle House because the person who’s next in line will kill you. All these examples represent jargon-common abbreviated ways that people talk. You could consider this a domain specific language (after all, it is a language specific to a domain), but doing so leads to the slippery slope where everything is a DSL. Thus, I’m going to lean on Martin Fowler’s definition of a DSL, extracted from the book on DSL patterns he’s writing.
A domain specific language is a limited form of computer language designed for a specific class of problems.
He adds another related definition to this:
Language-oriented programming is a general style of development which operates about the idea of building software around a set of domain specific languages.
With this definition in hand, I’ll limit the scope of DSLs as a software terminology to keep it inside reasonable bounds.
Why use language as an abstraction mechanism? It allows you to leverage one of the key features of jargon. Consider the elaborate Waffle House example above. You don’t talk like that to people because people already understand context, which is one of the important aspects of DSLs. When you think about writing code as speech, it is more like the context-free version above. Considering ordering coffee using C#:
Latte coffee = new Latte();
coffee.Size = Size.VENTI;
coffee.Whip = true;
coffee.Decaf = DecafLimit.HALF;
coffee.Foam = false;
Compare that to the more human way of ordering in the example above. DSLs allow use to leverage implicit context in our code. Think about all the LINQ examples you’ve seen. One of the nicest things about it is the concise syntax, eliminating all the interfering noise of the actual underlying APIs that it calls.
Now let me offer some additional definitions before I delve into code examples. Two types of DSLs exist (again borrowing Martin’s terms): internal and external. Internal DSLs are little languages built on top of another underlying language. LINQ is a good example of an internal DSL because the LINQ syntax you use is legal C# syntax, but an extended (domain specific) syntax. An external DSL describes a language created with a lexer and parser, where you create your own syntax. SQL is a good example of an external DSL: someone had to write a grammar for SQL, and a way to interpret that grammar into some other executable code. Lexers and parsers make people flee in fear so I’m not going to talk about external DSLs here, but focus instead on the surprisingly rich environment of internal DSLs.
Fluent Interfaces
A fluent interface is just “regular” code, written in such a way to eliminate extra syntax and create sentences. In spoken languages, a sentence is a complete unit of thought. Fluent interfaces try to achieve the same effect by clever use of syntax. For example, consider this version of the coffee API shown above:
Latte coffee = Latte.describedAs
.Venti .whip .halfCaf .foam;
This description is almost as concise as the English version, yet it is valid C# code, with some creative indentation. Notice how fluent interfaces try to create a single unit of thought. In the API version above, you only know that you are finished defining a particular cup of coffee by the context of the code; you’re finished when the code switches to another object of some kind. By contrast, the fluent interface version is a complete unit of thought. In spoken languages, you use a period to indicate a complete unit of thought. In the fluent interface, the semi-colon is the marker to terminate the complete unit of thought.
Why would you create a fluent interface like this one? After all, for developers, the API version seems reasonably readable. However, a non-developer would have a hard time reading the API. I worked on a project recently that dealt with leasing rail cars. The rail industry has lots of really elaborate rules about uses for certain types of cars. For example, if you normally haul milk in a tanker car, if you ever haul tar in that car, you can no longer legally carry milk in it. While working on this project, we had really elaborate test-case setups (sometimes running to several pages of code), to make sure that we were testing the right characteristics of cars. We tried showing them code that looked like this:
ICar car = new Car();
IMarketingDescription desc = new
MarketingDescription();
desc.Type = "Box";
desc.SubType = "Insulated";
desc.Length = 50;
desc.Ladder = true;
desc.LiningType = LiningType.CORK;
car.Description = desc;
Our business analysts pushed back on this. While it’s perfectly readable by developers, the analysts had a hard time ignoring the noise introduced by the necessary code artifacts. To make it easier for them to read, we re-wrote the code into a fluent interface:
ICar car = Car.describedAs.
.Box
.Insulated
.Length(50)
.Includes(Equipment.LADDER)
.Has(Lining.CORK);
Our business analysts found this readable to the point where we no longer had to manually translate the meaning to them. This saved us time but, more importantly, it prevented a translation error causing us wasted time testing the wrong type of characteristics. The goal of fluent interfaces is not to get code to the point where non-technical people can write the code, but if they can read out code, it’s one less level of mismatch between developers and everyone else.
Let me show you an example of creating a fluent interface in C# using similar syntax to the example above but fleshed out with implementation details.
A .NET Bakery
Let’s say you run a bakery, and you are in cut-throat competition with the bakery across the street. To remain competitive, you need to have really flexible pricing rules for assets like day old bread (because every time you change your prices, the guys across the street do too). The driving force is really flexible business rules.
To that end, you create the idea of discount rules based on customer profiles. You create profiles that describe customers, and base discount incentives on those profiles. You want to be able to define these rules at the drop of a hat. Let’s solve this problem by composing a couple of DSLs.
A Profile Fluent Interface
I’ll write a bit of code that shows the first version of what I want my Profile DSL to look. Listing 1 shows a unit test for the syntax I want:
The source for the Profile class appears in Listing 2.
The Profile class uses a DSL technique called member chaining. Member chaining refers to methods and/or properties created with sentence composability in mind. From a C# standpoint, it’s as simple as creating properties and methods that return the host object, or this, instead of their typical return value. In this example, I’m playing simple games with case: the member chained methods start with lower case letters (having capital letters embedded within sentences would look a little odd) and the “normal” properties use the standard convention. Using syntactic tricks like this is fairly common in the DSL world; trying to bend the language to make it more readable.
Ideally, you want to remove as much syntactic noise as possible, and a little bit still lurks in the constructor invocation, creating a new Profile object before allowing the fluent methods to engage. One way to solve this is to create a static factory method on the class that serves as the first part of the chain. In this case, I’m going to create a describedAs method within Profile:
static public Profile describedAs
{
get
{
return new Profile();
}
}
This allows the consumption of the fluent interface to be more graceful, as illustrated in the unit test shown in Listing 3.
Notice that using chained properties violates a common rule of properties, the Command Query rule, which says that get properties shouldn’t make any modifications to the underlying object. However, to make this style of DSL work, you need to ignore the Command Query rule and allow get properties to set an internal field value and still return this.
A Discount Fluent Interface
From a technical standpoint, the Discount implementation looks pretty much like Profile, so I won’t show most of the code. Listing 4 shows the unit test that demonstrates the use of the class.
In this example, the Discount class relies on the Profile (which is created via the fluent interface described above). The other part of the Discount class sets threshold values based on the Profile, determining the amount of the discount for this profile. The implementation of the forXXX methods simply sets an internal value and then returns this to enable the fluent interface invocation. These methods appear in Listing 5.
The only other interesting part of Discount is the DiscountAmount property, which applies the discount rules to determine an overall discount percentage, shown in Listing 6.
The Rule List Class
The last piece is the class that builds lists of Discount rules, which is shown in Listing 7.
The only chained method here is the addDiscount() method. The unit test shows how all the pieces fit together; it appears in Listing 8:
Notice the conciseness of the above code. Yes, it looks a little odd if you are primarily used to looking at C# code, but when read as a non-technical person, there is very little syntactic cruft.
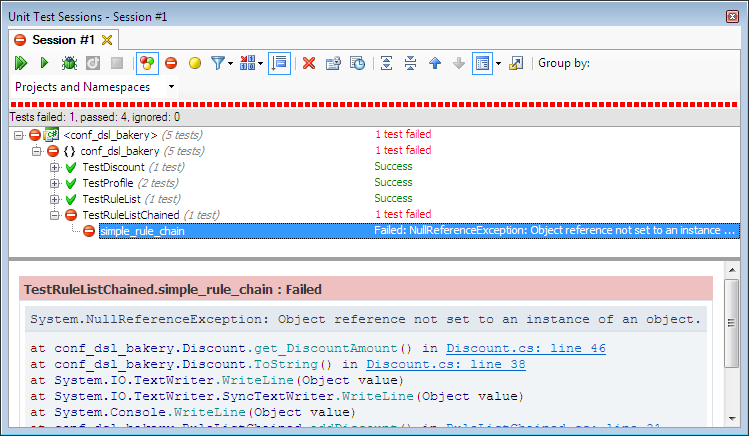
If you run the test you can see that you do indeed have a discount list. However, a lurking problem exists. In the RuleList, suppose you want to save the rules in a database during the add operation. Or, even simpler, suppose you just print out the rule as you add it. To that end, I’ve modified the addDiscount() method like this:
public Discount addDiscount()
{
var discount = new Discount();
_ruleList.Add(discount);
Console.WriteLine(discount);
return discount;
}
But the results surprise: see Figure 1.
The Finishing Problem
The problem with using member chaining for the RuleList class is called the finishing problem: when does the call “finish”? If you execute some code in the add() method, the rest of the members of the chain haven’t executed yet, causing an exception. How do you solve this problem?
One solution creates a special “finished” method at the end of the chain. For example, Listing 9 shows one way to re-write the test.
Adding a finishing marker works, but it harms the fluency of the interface. When you talk to someone, you don’t say, “Meet me at the place at 5 PM-SAVE!” The finishing should just work.
As an answer to this particular problem, you can use an alternative resolution technique with nested methods. Instead of implementing the add() method as a chained method, you’ll supply context by changing it to a more traditional method call, leaving the other chained methods in place.
public RuleList add(Discount d)
{
_ruleList.Add(d);
return this;
}
Changing the chained addDiscount() method to use method nesting allows you to write the rule list definition like the test shown in Listing 10:
This solves the finishing problem by controlling the completion by wrapping the chained methods in a nested method invocation. This is quite common in fluent interfaces. In fact, developers use this rule of thumb when building DSLs:
- Use method chaining for stateless object construction
- Use nested methods to control completion criteria
Summary
This example of fluent interfaces really just scratches the tip of the iceberg of DSL techniques. As you can see, you can stretch C# in interesting ways to create more readable code. In the next article, I’ll cover some more DSL techniques, and in particular the features added to C# on behalf of LINQ that makes building really rich DSLs.
