


You might have heard some things about NoSQL; how Google and Facebook are using non-relational databases to handle their load. And in most cases, this is where it stopped. NoSQL came about because scaling relational databases is somewhere between extremely hard to impossible.
In 2007, I started getting interested in NoSQL and NoSQL databases. I did it because it was interesting, and like most developers, I am somewhat addicted to the notion of faster and bigger. But something really strange happened along the way. Instead of focusing on those things that can make an application grow to a 100,000,000 users, I started noticing the problems in most NoSQL solutions.
In particular, most of them were so focused on scaling or performance that little or no thought was given for things like developer productivity. That bothered me because I could see that there are many advantages to NoSQL databases that I would have loved to use, if only it wasn’t so hard to perform many of the day-to-day operations.
We have grown used to equating a database with a relational database, and SQL has become one of the basic building blocks of software development. That is actually quite interesting, because in a sense, relational databases actually make it quite hard to work with them.
The first problem most of us encounter is the impedance mismatch between object-oriented modeling and relational modeling. In a relational database, you are limited to tables, columns and rows. In your objects, you typically have properties, collections and associations. We can map between the two, that is what object-relational mappers are all about, but it is neither trivial nor easy.
The next issue that usually trips people up is that relational databases are actually optimized to work in exactly the opposite way that we usually work with it. Relational databases are optimized to reduce the cost of writes at the expense of reads. In the vast majority of cases, the number of reads far outstrips the number of writes, but relational databases don’t work like that. It is easy to update things in a relational database because you need to update a single row on a single table. But in order to read meaningful data back, you often have to join across multiple tables.
The reason for this is quite obvious, if you cast your mind about 30 years into the past. At the time, the amount of space it would take to hold a single album’s worth of songs would cost about as much as the annual salary for a software developer. It made perfect sense to do anything possible to reduce the amount of data stored. Besides which, it was just fine to have the user wait for the machine; the machine was (by far) the more expensive of the two.
RavenDB came out of a set of realizations. Relational databases aren’t necessarily the start and end of all of our data storage needs, that most NoSQL solutions paid little if any attention to developer productivity and that there really was no reason to limit usage of NoSQL to high-scale projects.
Hello RavenDB
Before I get into the theory and design guidelines behind RavenDB, I think it is best to start off by showing how RavenDB works from the developer perspective.
I will assume that you are using Visual Studio 2010 and you have NuGet installed. If you don’t, you can install it from http://nuget.org/. If you need to download RavenDB, head up to http://ravendb.net and click on the download menu.
We’ll start with creating a simple console application project, and then install the RavenDB package. In the Package Manager Console, execute:
Install-Package RavenDB
You can also right-click the References node on the project and select Manage NuGet References and then search for and install the RavenDB package.
Along with the RavenDB package, the server is installed. You can go to PROJECT_DIR\packages\RavenDB.1.0.573\server and then execute:
Raven.Server.exe
You should now be able to go to http://localhost:8080 and open the RavenDB Management Studio. Your browser should look like Figure 1.
The RavenDB API
This is pretty much all the setup that we are going to need, so lets start doing some work with it. We start by creating and initializing the DocumentStore:
var documentStore = new DocumentStore
{
Url = "http://localhost:8080"
};
documentStore.Initialize();
The DocumentStore is the entry point into RavenDB. You typically have only one of them per application, as a singleton. The DocumentStore contains the RavenDB cache, optimization settings, conventions and much more.
If you are familiar with NHibernate, the DocumentStore is very similar to the SessionFactory. And while it is the entry point, it isn’t the main object through which you interact with RavenDB; this is what we have the IDocumentSession for:
using(var session = documentStore.OpenSession())
{
// Using the session
}
The session is a transient object, usually alive for a single operation or a web request. Like the NHibernate’s Session or an Entity Framework’s DataContext, the RavenDB’s Document Session is a Unit of Work. It keeps tracks of all the loaded entities and will save them to the database when you call SaveChanges.
Let’s just do something. For the rest of this article I will use a restaurant-themed example. The first thing that we are going to work with is the menu. You’ll start by defining some classes to hold the menu:
public class Menu {
public string Id { get; set; }
public string Name { get; set; }
public List<Course> Courses { get; set; }
}
public class Course {
public string Name { get; set; }
public decimal Cost { get; set; }
public List<string> Allergenics { get; set; }
}
I snipped the default constructors that initializes the lists to empty lists, but those are our model classes. We’ll discuss their structure more in just a bit, but for now, let’s start working with them!
session.Store(new Menu
{
Name = "Breakfast Menu",
Courses = {
new Course {
Name = "Waffle",
Cost = 2.3m
},
new Course {
Name = "Cereal",
Cost = 1.3m,
Allergenics = { "Peanuts" }
},
}
});
What does this code do? It creates a new Menu instance with two Courses and then stores them in the session. When you store an object in the session, you are merely asking the session to remember to save that instance later on, when you call SaveChanges. Until SaveChanges is called, nothing is actually going to happen. This allows RavenDB to optimize writes to RavenDB to the smallest possible number of requests.
Now you call SaveChanges:
session.SaveChanges();
And you can now go to RavenDB Management Studio and see the newly saved document. In fact, if you’ll look at Figure 2, you can see that there are now two of them.
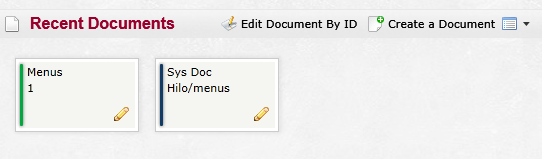
For now, we will ignore the Hilo document; I will discuss it in more detail later on. Let’s focus on the Menu document. Double-click it to see its content:
{
"Name": "Breakfast Menu",
"Courses": [
{
"Name": "Waffle",
"Cost": 2.3,
"Allergenics": []
},
{
"Name": "Cereal",
"Cost": 1.3,
"Allergenics": ["Peanuts"]
}
]
}
I hope that by now your curiosity is piqued. We just saved a fairly complex object graph into our database, and it saved cleanly and into a single document. Think about the implications of this for a moment. Consider what would happen if we were trying to work with a relational database here.
We would have needed to define a schema (requiring four tables to store the information), find a way to tie it to our source control history and deploy it.
When loading a menu, we would need to query four tables to show a simple menu. Whereas with RavenDB, we can load it all in a single command, as you can see here:
using (var session = documentStore.OpenSession())
{
var menu = session.Load<Menu>("menus/1");
Console.WriteLine(menu.Name);
foreach (var course in menu.Courses)
{
Console.WriteLine("\t{0} - {1}",
course.Name, course.Cost);
Console.WriteLine("\t\t{0}",
string.Join(",", course.Allergenics));
}
}
Here you can see another interesting benefit of using RavenDB. If you tried writing the same code using a relational database, it would suffer from the SELECT N+1 problem. For every Course in the Menu, you would issue a separate query. Because RavenDB stores the document as a single entity, you don’t have to deal with that, and you can efficiently load the entire entity in just one request to the server.
Querying with RavenDB
Now that we have some information in the database, it is time for us to get that data out. We have already seen that we can load entities using their ids (session.Load<Menu>(“menus/1”); ). But how about when we want to query based on the values of the entity, and not just its id? Let’s see how we can do that:
var menus =
from menu in session.Query<Menu>()
where menu.Name.StartsWith("Breakfast")
select menu;
This should look familiar to you; RavenDB supports LINQ and allows you to perform complex queries on your entities without any trouble at all. For that matter, let’s see how we can find a Menu that has a cheap course:
var menus =
from menu in session.Query<Menu>()
where menu.Courses.Any(c => c.Cost < 2)
select menu;
That leads to an interesting observation. Using our current model, we can’t really ask for a specific Course, because Course is actually part of a Menu. And this topic leads us from the RavenDB API to actual modeling with RavenDB.
Modeling with RavenDB
By far, the most significant challenge that most people have when moving to RavenDB is modeling. Relational modeling techniques have been deeply embedded in us from early in our careers. And in many cases, relational modeling techniques are exactly the wrong ones for RavenDB and the problem at hand.
With a relational database, we are used to splitting the data into many tables, into normalizing everything and into shaping the data using queries on the way out.
With RavenDB, we move the burden from the read side (which happens a lot) to the write side (which happens far less often). We are also dealing with entities that are far bigger than standard entities in relational database. Because we can store complex object graphs inside RavenDB easily, we no longer need to split an entity into multiple physical representations because the data store demands it.
If you are familiar with Domain Driven Design, all entities in RavenDB are Root Aggregate, and all other values are actually Value Objects.
Let’s go back to our restaurant example and look at how we would model an order. In a relational system, the order model would probably be composed of Orders, Customers, OrderLines, Products, etc.
Each of those would be a separate entity. But does it really make sense to store OrderItems outside of an Order, or is this just an aspect of the Order? What about Payments on the order? As you can see in Figure 3, modeling in RavenDB is quite different.
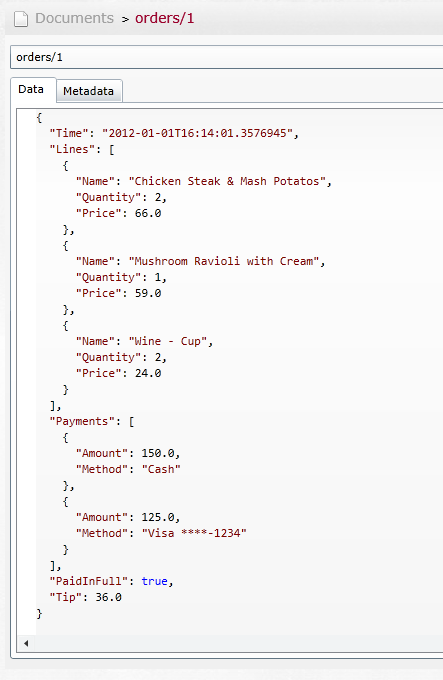
You can see the classes for this model in Listing 1. There are a few things to note. Both OrderLine and Payment are embedded inside the Order. In other words, it is nonsensical to talk about Payment #1 or OrderLine #45; they don’t have a separate existence outside for their order.
That leads to some very interesting observations. First, because we include those details inside the same document, accessing those details is now very cheap. Let’s look at the following code snippet:
public bool PaidInFull
{
get
{
return Payments.Sum(x => x.Amount) >=
Lines.Sum(x => x.Price*x.Quantity);
}
}
This is perfectly acceptable in RavenDB, all the data is already there. In a relational database, this sort of code (which is quite natural and elegant) would result in two separate queries to the database.
Concurrency
Another issue that no longer raises its ugly head is concurrency. In a relational database, the unit of concurrency is the row. But we usually have to store data in multiple tables. That makes it possible to update parts of the entity without proper concurrency control. Anyone who ever had to make sure that whenever an OrderLine or a Payment is updated, the Order is properly locked so we won’t have a race condition is intimately familiar with the problem.
With RavenDB we don’t have to worry about that. The unit of change is the document, and the document can contain complex objects, so changing an OrderLine or adding a Payment means that we don’t make any contortions with regards to concurrency control in non-trivial scenarios. What we need to do is simply ask for optimistic concurrency, like so:
session.Advanced.UseOptimisticConcurrency = true;
And any call to SaveChanges will use optimistic concurrency and throw a ConcurrencyException if someone went behind our back and changed the entities that we modified.
Schemaless Data Store
RavenDB is schemaless. That means that you can store data in any shape inside RavenDB. We usually work with RavenDB using a POCO (Plain Old Clr Objects) model, which means that we have a well-defined shape for the objects we work on (at the client side), but we can also take advantage of the schemaless nature in more explicit ways. For example, let’s say that we want to allow users to add arbitrary data to our entities.
In the restaurant example, we may want to be able to add things like IsAnnoyingCustomer and SatisfactionLevel to the Customer entity. Not as standard properties, but just things that the user can dynamically add to an entity on the fly.
Let’s see how this works. First, we define the Customer entity:
public class Customer
{
public string Id { get; set; }
public string Name { get; set; }
public Dictionary<string, object>
Attributes { get; set; }
}
And we can save it to RavenDB with the following code:
session.Store(new Customer
{
Name = "Joe Smith",
Attributes =
{
{"IsAnnoyingCustomer", true},
{"SatisfactionLevel", 8.7},
{"LicensePlate", "B7D-12JA"}
}
});
So far, this is very simple. You can see the resulting document in Figure 4.
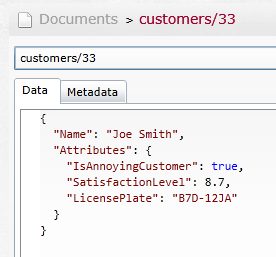
So far, so good. But the really fun part comes when we want to work with it. As you can see in Figure 4, we didn’t really care in RavenDB that this is a dynamic property. We just store the data, but that is just half of the job. How do we work with this information?
As it turns out, really easily:
session.Query<Customer>()
.Where(x => x.Attributes["IsAnnoyingCustomer"]
.Equals(true)
)
.ToList();
This will prodouce the right results, and give us a really nice interface to query dynamic properties without any problem at all.
Of course, I don’t recommend going that route unless you actually need dynamic properties. It is easier to work with static properties, not because of any RavenDB limitation, but simply because you can use the compiler to help you.
Indexing
We have been working with RavenDB for a while now. We have seen how we can store structured and unstructured data inside it, and how we can query it. But we have only been working with it on a surface level.
This is quite intentional. One of the guidelines in RavenDB’s design was that It Should Just Work. And for the simple CRUD tasks, which compose over 90% of our work, this is quite enough. For the remaining few percentage points, however, we need to go a bit deeper and discuss how RavenDB actually works.
There are actually two distinct parts inside RavenDB: storage and indexing. Storage is for actually storing the documents; we store them in a transactional store which is fully ACID. RavenDB ensures that when you save a document (or a set of documents) that happens in a transaction (yes, just like in a relational database). It either goes all the way in or gets rolled back completely.
Storage isn’t really interesting for external users. It works; it supports transactions, backups and so on. But that is pretty much it.
RavenDB’s indexing is a lot more interesting. RavenDB doesn’t require you to define any schema. You can store any document inside RavenDB. You can even store a Customers/1 and Customers/2 documents with totally different schema. But there is something that needs to add some order to this mix. Putting the data in is easy, and so is getting it out when you know the document id.
But what about querying? How can we query on such a schemaless data set? Are all queries in RavenDB effectively a “table scan” that gets progressively slower as the database grows?
In a word: No!
RavenDB supports the notion of indexes, but while they serve some of the same purposes as indexes in a relational database, they are actually quite different. RavenDB supports exactly two ways to query the data:
But what is an index? Here you go:
from customer in docs.Customers
select new { customer.Name };
This is a RavenDB index, indeed. “Wait!” I can hear you say, “This isn’t an index, this is a LINQ statement.” It is both.
The way indexes in RavenDB work, you construct a LINQ statement and hand it over to RavenDB. RavenDB will then execute this LINQ statement on a background thread, finding all the Customers in the database and projecting out their names. We can then take the names and store them in an index.
In fact, as you can see in Figure 5, because RavenDB can store arbitrary data, we need something else that will provide some structure for us.

The indexes provide us with this structure. Because a LINQ statement has a well-defined result type, we can build an index with a known shape, and query that efficiently.
Indexing Execution and Staleness
I find this to be a very elegant solution for the problem of dealing with unstructured data. But it is only part of what RavenDB actually does. You are probably used to indexes which are being updated whenever an update is made to the database, but RavenDB doesn’t work that way.
Instead, RavenDB indexes are always being updated in the background. Whenever there is a change to the database, the indexing thread wakes up and starts indexing the new updates. This allows us to significantly optimize indexing because it allows batching several updates at the same time. And it also means that we don’t have to wait for indexing to happen on every write.
This design decision has a few interesting implications when we start considering real-world systems. The most obvious one is that it is possible for us to query the database after an update but before it was indexed. What would happen then?
As you can see in the diagram in Figure 6, we are going to return a reply based on what is currently indexed. That might be a problem, as you can imagine, because we are returning data which is not correct.
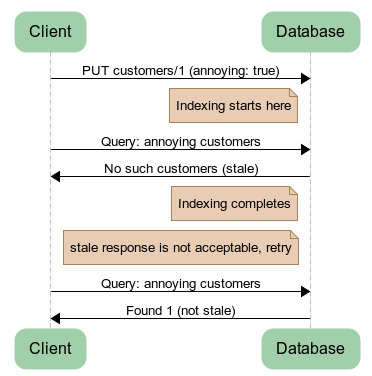
There are several reasons why this is the case and why for the most part, this is a good thing. As you can see in Figure 6, we don’t just return the wrong information. We return the information that we have at hand and tell you that it is stale.
This is important. By moving all indexing to a background task, we are able to complete write requests much faster, and batch all the indexing updates together. And because we tell you that the information might be stale, you now have the choice of what to do about it.
For a surprisingly large number of cases, returning stale information is perfectly fine. Just consider everywhere were you have ever applied caching. In those cases, you were explicitly deciding to return potentially stale information for the user in order to increase performance.
Along with reporting whether a response is stale or not, we report how stale it is. You can see a full example in Listing 2 where we show how you can get the statistics for a request and make a decision based on the information provided there.
Finally, remember that RavenDB is composed of two major components. Indexes can be stale, but documents never are. That means that if you make a request by id, you are guaranteed never to get old information.
Dynamic Indexes
You might have been wondering something by now. I said that you can only query RavenDB using an index, so how come we can do things like this?
session.Query<Customer>()
.Where(x => x.Attributes["IsAnnoyingCustomer"]
.Equals(true)
)
.ToList();
You might wonder if I pre-defined an index behind your back. Well, no, not really. What we actually did is ask RavenDB to query all Customers’ documents where Attributes.IsAnnoyingCustomer is equal to true. And because we didn’t explicitly specify an index, what happens is that the query goes to RavenDB and it is up to the Query Optimizer to decide what indexes is going to handle this query.
And what happen if there is no matching index? Let’s look at Figure 7 for an answer.
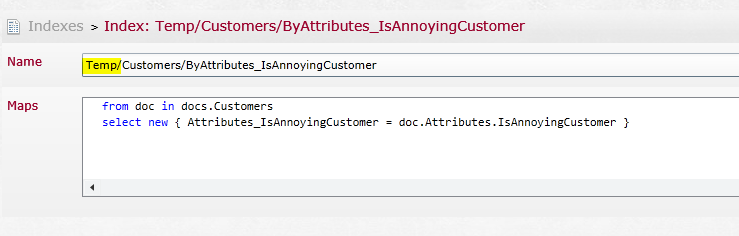
What is this index? Well, that is what happens when the Query Optimizer can’t find a matching index; it will create a temporary index that can answer the query. This is how RavenDB implements its ad-hoc queries capabilities.
Please see the sidebar about temporary indexes for additional discussion for how temporary indexes are managed. The short of it is that this is a production-ready feature, and it saves quite a lot of work, because you don’t have to define indexes ahead of time. RavenDB will create and manage them for you.
Static Indexes
Since RavenDB can create indexes for us on the fly, do you want to define your own static indexes? The answer is, as you might have imagined, yes.
Static indexes are useful in any number of scenarios, from full text searches to geo-spatial queries, from map reduce operations to event sourcing. I don’t have the space in this article to cover static indexes in enough depth (that can be an article or two all on its own), so I would just say that proper use of indexes can make your RavenDB applications shine.
Summary
One of the parts that is the most fun in building RavenDB applications is the attention given to actually making things works properly. All too often you see products that are truly awe inspiring, as long as you use them for a demo.
RavenDB took the approach that you can be a truly awesome product and still be something that doesn’t require a lot of tweaks to go to production.
I previous mentioned the notion of Safe by Default. RavenDB will actively monitor itself and stop and prevent misuses that could take down your applications early on. Having a safety net to catch you if you don’t notice that you missed something is quite nice.
In this article I have really been only able to touch RavenDB on the very surface. I have shown you how to do basic CRUD operations with RavenDB, a bit about the design approach and how indexes work.
There is a lot more to learn and do. RavenDB supports sharding, map reduce, spatial queries, replication and much more. It has a fully async API and is available for Silverlight as well.
You can read more about it at http://ravendb.net or join the discussions about it in the mailing list http://groups.google.com/group/ravendb/
Listing 1: A restaurant Order model
public class Order
{
public DateTime Time { get; set; }
public List<OrderLine> Lines { get; set; }
public List<Payment> Payments { get; set; }
public bool PaidInFull
{
get
{
return Payments.Sum(x => x.Amount) >=
Lines.Sum(x => x.Price*x.Quantity);
}
}
public decimal Tip
{
get
{
var tip = Payments.Sum(x => x.Amount) -
Lines.Sum(x => x.Price*x.Quantity);
if (tip <= 0)
return 0;
return tip;
}
}
}
public class Payment
{
public decimal Amount { get; set; }
public string Method { get; set; }
}
public class OrderLine
{
public string Name { get; set; }
public int Quantity { get; set; }
public decimal Price { get; set; }
}
Listing 2: Working with stale indexes
RavenQueryStatistics stats;
var queryable = session.Query<Customer>()
.Statistics(out stats)
.Where(x => x.Attributes["IsAnnoyingCustomer"].Equals(false));
var customers = queryable.ToList();
Console.WriteLine("Stale: {0}", stats.IsStale);
Console.WriteLine("Last update: {0}", stats.IndexTimestamp);
if((DateTime.UtcNow - stats.IndexTimestamp).TotalSeconds > 10)
{
// too old, we want to wait for indexing
queryable.Customize(x => x.WaitForNonStaleResultsAsOfNow());
customers = queryable.ToList();
}
