


Both ASP.NET MVC and the ADO.NET Entity Framework are both very popular topics right now in the developer community.
Having spoken at various user group meeting and code camps it is very obvious to me what topics a lot of developers are interested in. I see that sessions about ASP.NET MVC or the Entity Framework are always packed with developers eager for more information. The focus of this article is the Entity Framework, but in the context of an ASP.NET MVC application. As such, I am assuming at least basic understanding of ASP.NET MVC but little-to-none with Entity Framework.
ASP.NET MVC really is a game changer in the .NET web development community. Although Web Forms has its place and has served developers well in allowing them to create applications quickly, ASP.NET MVC gives developers a new way to do things. ASP.NET MVC follows the MVC (Model View Controller) pattern that is extremely popular in the development community because of its success. It allows for a clean separation of concerns and makes code easier to read and maintain. One could argue that code maintainability is probably the single most important thing that developers need to take into account when creating applications but is sadly one of the things that is left in the dust due to deadlines and laziness. With the exception of a few very small throw-away applications, maintainability needs to be key when writing code.
A lot of concepts that ASP.NET MVC brings to the table complement each other extremely well. For example, the fact that it uses the MVC pattern gives you a clean separation of concerns which by its very nature leads to better code maintainability. Developers (especially newer developers) tend to stuff everything in code behind with ASP.NET Web Forms. While this approach does work and it gets the job done, it can make your application more difficult to maintain down the road. There are many reasons why I think ASP.NET MVC is a solid choice for building web applications in .NET, but code maintainability is one of the highest on my list. That’s not to say that ASP.NET Web Forms is completely outdated and should never be used under any circumstances. I do believe that there is still a place for them. If I am going to build an application that is largely form driven and especially if I need to use existing third-party controls, ASP.NET Web Forms may be a perfect way to build my application. But in this article, I’ll show you why ASP.NET MVC may be a better choice for many common situations.
The ADO.NET Entity Framework at 10,000 Feet
The ADO.NET Entity Framework is an ORM (Object Relational Mapping) tool and is Microsoft’s main data access strategy moving forward. Microsoft released version 1 with Visual Studio 2008 SP1 with the .NET Framework 3.5 SP1. They released version 4 with Visual Studio 2010 and the .NET Framework version 4. The product team decided to sync the version number with the version of the .NET Framework. You may see references to v1 as Entity Framework v3.5 as well as v1 to reflect this.
ORM tools allow you to work with your relational database in a way that makes more sense to you as a developer and doesn’t require you to hand code SQL (which is something I don’t think many developers ever actually want to do on a regular basis). You work with a set of objects in your application that represent the database and an ORM tool will generate dynamic SQL that is sent to the database and executed. I have heard it said that ORM tools have an 80/20 use ratio, meaning that on average an ORM tool will solve 80% of your database access issues and the other 20% will likely need to be done with stored procedures or some other method. I think this is a solid ratio, but the ratio tends to be more like 95/5 for me. The real ratio will ultimately depend on the type of applications that you write. For quite a few of the projects I work on, the Entity Framework solves 100% of my data access problems. On average, I would say that just by using an ORM, my data access development time is cut by at least 75%. Since the ORM tool handles all of my CRUD (Create Read Update Delete) operations, I don’t have to write and debug SQL code for basic data access. This is, of course, the beauty of ORM in general and the Entity Framework fills this space nicely.
I have used many ORM tools over my development career and have personally found the Entity Framework to be my favorite and the one I use by choice in all new applications. I found v1 to be very usable (despite what others may think) and have several applications currently in production using it. There is no denying, however, that v4 is a game changer and as a developer, you should take a few minutes to check it out. I don’t think there is anything wrong with the other ORM tools out there and they are certainly viable tools for doing the job, I just prefer Entity Framework.
Entity Framework uses LINQ (Language INtegrated Query) and Entity SQL to query, but you will likely be using LINQ primarily. Entity SQL can fill some nice gaps where your query is a little too complex for LINQ but can give you another option before going to a stored procedure. I use a combination of full LINQ queries and lambda functions depending on the need, but my tendency is more towards lambdas. Entity Framework gives you the ability to easy navigate between relations using Navigation Properties so I rarely need to write joins in LINQ. This ultimately leads to cleaner code and more maintainable code, which is why I think it is a good fit with building ASP.NET MVC applications.
Entity Framework 4 introduced several new features that made working with ASP.NET MVC easier and cleaner. One of the really nice things about the fact that you have greater separation of concerns easier with ASP.NET MVC is that unit testing is infinitely easier. While you could technically unit test Entity Framework v1, v4 makes it much easier to do since mocking is easier. This is all accomplished by using my favorite feature of Entity Framework v4 - the POCO support. POCO (Plain Old Clr Object) allows you build a persistent ignorant data access layer, which is by nature better for testing. Without POCO, the classes you would work with are objects derived from actual Entity Framework classes. Using the Entity Framework classes makes mocking more difficult and thus testing is more difficult. The classes also carry a dependency on the Entity Framework so you would have to reference the System.Data.Entity assembly whenever you use them. While this is not a major issue, it does make things like Dependency Injection more difficult. POCO solves this by giving you classes that are completely independent of the Entity Framework. POCO thus allows for easy use of Dependency Injection and other patterns for building modular applications. For example, later in the article I’ll show you how to implement the Repository and Unit of Work patterns. Both made easier with POCO due to Entity Framework v4.
A Quick Overview of the ObjectContext
When working with the Entity Framework, the core class that you must use is the ObjectContext. This is the object that does all interaction with the database. It manages your database connection and handles all reads and writes as well as takes care of change tracking. It is probably the singular most important object when working with the Entity Framework but is also probably the most abused. The subject of the ObjectContext is a topic for an entire article on its own, but there are a few key things that will help keep you from running into trouble.
Because the ObjectContext does change tracking it is the source of most weird issues that people encounter when using the Entity Framework. Those new to ORM tools may not realize what is actually happening when change tracking is used. The Entity Framework makes it really easy to query objects, change them and then save them back to the database without you having to worry about insert order and writing update statements. The ObjectContext is smart enough to know what order things need to be done and generates SQL to make sure that all operations get completed as quickly as possible. The very nature of how change tracking works, however, is what can trip up developers.
When you query an object with the ObjectContext, information about the object is stored in the ObjectContext state manager. Reverences are held in memory so that when you make a change to the object, the ObjectContext has a reference point to know what needs to be changed. If you query a lot of objects, a lot of objects will be held in the state manager until the context is disposed. The ObjectContext implements IDisposable to make the process of cleaning up more straightforward. The problems start happening when you have too many objects in the context at one time. When you call SaveChanges() on the ObjectContext, it will look at all of the objects in the state manager and decide what needs to be done to them. As you can imagine, having more objects in the state manager will simply cause more resources to be used. If you have objects there you are currently not using, you are wasting memory and CPU cycles. There is no hard and fast rule on how many objects can be on the context at any given time but my recommendation is to keep as small as possible. The rule I follow is:
Use a new ObjectContext for each logical set of operations.
Basically what I am referring to is if you need to query a few objects for display on a web page, query only what you need and keep the ObjectContext around only as long as necessary to manage those objects. I’ll touch on this in more detail when I show the code in the demo project.
Use a new ObjectContext for each logical set of operations
The actual entities are accessed through properties on the ObjectContext called an ObjectSet. This will be more important later on but remember that an ObjectSet<T> is the actual collection of entities in the database where T is an actual entity class. The ObjectSet implements IQueryable and is the property that is used when making queries that get processed by the ObjectContext.
Setting Up the Project and Building the Data Layer
I am using Visual Studio 2010 so that I can take advantage of both ASP.NET MVC2 and Entity Framework v4. I created a new ASP.NET MVC2 project called EfMvcCodeMag.Web with a separate directory of EfMvcCodeMag. Then I created a class library project called EfMvcCodeMag.Data. I’ll use this second project to house the data access layer that I will create. I personally am a big fan of separation of concerns (in case you haven’t noticed) and while I do not necessarily write N-Tier applications all of the time, I like to have my application separated out into layers. These layers are usually separated by assemblies, but I would at least make sure you have separation by namespaces so that you can have the option of separating into assemblies later. There are a host of reasons for doing this that I won’t touch on here as it is a topic for another time.
To get started I am going to add a new ADO.NET Data Model to my data layer. To do this, right-click on the data layer project file and select “Add” then “New Item…” This will bring up the Add Item dialog box that you know so well. Under the Data tab there will be an option for “ADO.NET Entity Data Model”. I called mine “DataModel.edmx” and I’ll click “Add”. The Entity Data Model Wizard dialog box will appear to ask you if you want to start from an existing database or start with a blank model. I used the Model First features of Visual Studio 2010 so I selected “Empty Model” and clicked “Next” (Figure 1). Visual Studio 2010 has some nice features for Model first so you could start there with your project or if you have a database already, you can import it. Both are very good options, they just depend on your need. Since I started with an empty model, the wizard ends and I have a blank model to work from.
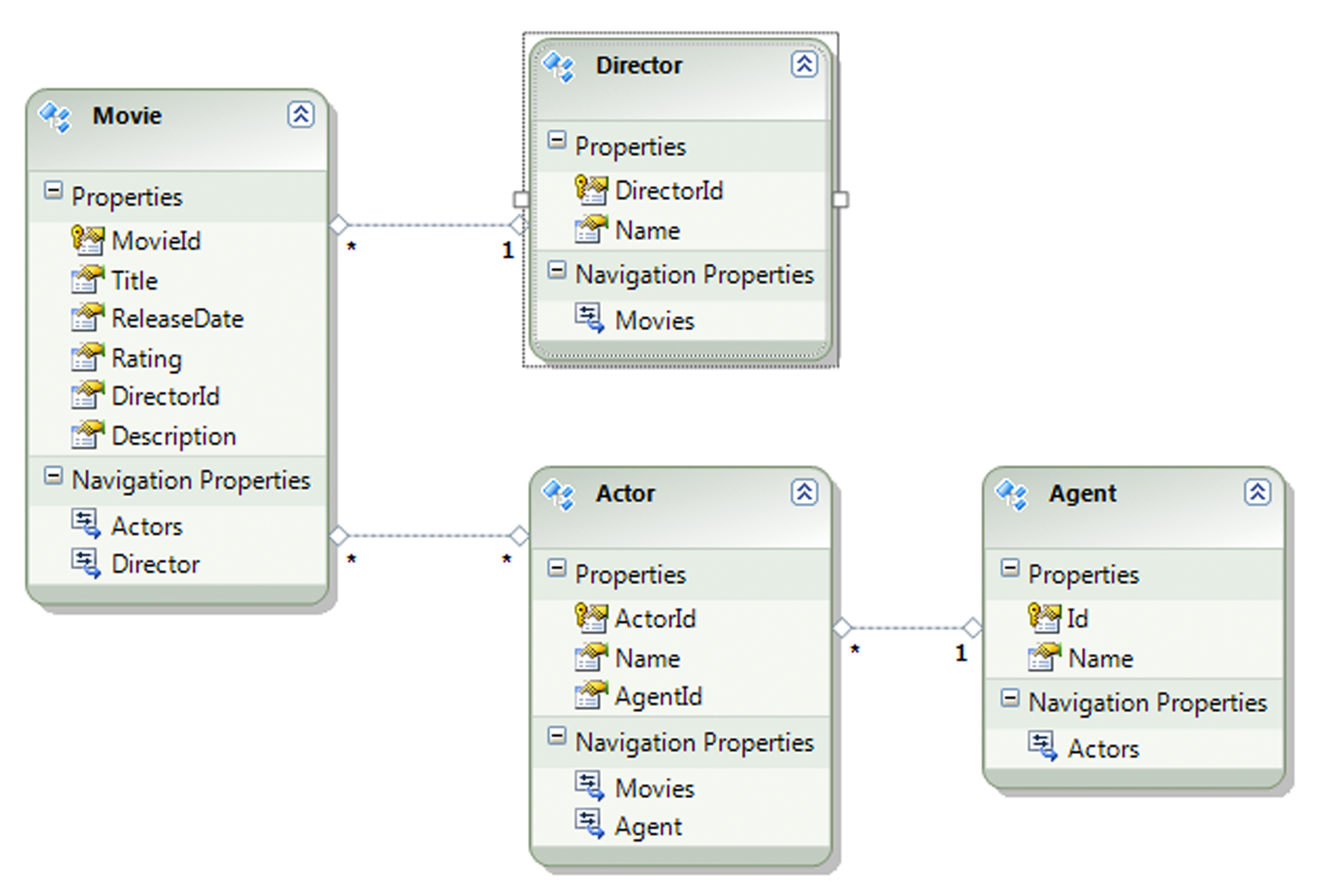
The data model I will work from is a simple movie database that tracks movies and the associated directors and actors. The actors also have their associated agents as well. Figure 2 shows the data model as it appears within the design surface in Visual Studio. As you can see, the Movies entity has a many-to-many relationship with Actors and Directors has a one-to-many relationship with Movies. Agents have a one-to-many relationship with Actors. This means that Movies can have multiple actors and Actors can be in multiple moves. Each actor has exactly one agent and an agent can have multiple actors. Each movie can have exactly one director but a single director can be tied to multiple movies. With the Entity Framework data model set up, we now have everything to start building the application.
First I want to get POCO classes in place of the current Entity Framework classes. Microsoft includes a nice POCO T4 (Text Template Transformation Toolkit) template that will generate this for you from the model. From your model surface, right-click in an open area and select “Add Code Generation Item…”. This will open the Add Item dialog box. Under the Code section, select “ADO.NET POCO Entity Generator”. This will add two .tt files to your project and will contain the new POCO-based ObjectContext and new POCO classes. If you expand the two .tt files you will see the generated files.
In ASP.NET MVC to fulfill the MVC pattern you have models, views and controllers. The model portion of the pattern is where you define the data that gets passed to the view. I am personally a fan of strongly typed views where possible as it adds some additional testability and can make the view easier to work with in code. When using the Entity Framework, you have two options for using models. You can either use the Entity Framework classes as your model or you can build custom model classes. Either option will work well; it just depends on your application architecture. I tend to lean towards custom models as it adds greater flexibility, especially if you decide sometime down the road that you need to add additional items to your model that aren’t part of your Entity Framework classes. If you have an instance where you need to pass an entity and also pass data to be used to fill a select list, you really don’t have much of a choice but to use a custom model.
Once I decide how I am going to build my models, I need to start fleshing out my data access strategy. There are a few different options here. I could make the Entity Framework calls right inside the controller, but I would recommend against that in most cases due to the fact that it makes testing and mocking more difficult. I normally will use a separate set of classes to make up my data layer. This gives me several options for use down the road. If I want to focus on unit testing first, then I can stub the classes out so that I can mock them easily. This will allow me to write unit tests with mocked data without having to build the implantation first. Once I have the functionality built that actually uses the data, I can then go in and build the data code itself. Since I am using POCO with separate data layer classes I could technically change my entire persistence engine and switch to a different ORM or even a different data access strategy altogether if I wanted. There are plenty of good reasons for wanting to separate your code out into multiple layers and I would recommend that if you are not in the habit of doing so, that you start right away. It can seem like extra unnecessary code at first, but it is well worth it in the end.
I like to follow the Repository pattern when building my data layer which adds a layer between your business logic and the actual data-specific code. The actual layer doesn’t necessarily mean a whole set of classes, but is normally how it is implemented. The trick is to build a layer that is ignorant of data persistence, which means that this layer shouldn’t expose the persistence method. I am going to create a Repository class for each entity which will aptly be named {Entity}Repository so we will have a MovieRepository, ActorRepository and so forth. This set of classes can be in the same assembly as the Entity Framework classes or they can be in their own assembly depending on how you wish to separate your application. In this instance I will have them in the same folder as the .edmx file and POCO classes. It tends to make the Repository classes easier to manage while still being able to keep them ignorant of the Entity Framework. I have a CodePlex project that will give generate the Repository classes for you that I will touch on towards the end of the article. Before that though, let me show you a simple way to build the necessary data access layer.
Let me start with movies as it is really the central purpose behind the application I am building. The first page that loads in the site will use the HomeController and the Index action which will subsequently load the Index view for presentation. I want to show a full list of movies on this page so the model needs to have the necessary information to display a list of movies. To accomplish this I will create a class called HomeModel and give it a property to store a list of movies:
public class HomeModel
{
public List<Movie> Movies { get; set; }
}
Since a movie object has the necessary information to reference the actors and director associated, you don’t need to explicitly include them here. There are a few options for loading the associated data which I will cover shortly. First, let’s look at the repository class that would supply this data:
public class MovieRepository
{
public List<Movie> GetMovies()
{
using (var context = new DataModelContainer())
{
var movies = context.Movies.ToList();
return movies;
}
}
}
The class and method names are pretty straightforward, but let’s examine the body of the GetMovies method. I’ll first start off by spinning up a new ObjectContext. The ObjectContext for the model I am working with is DataModelContainer. This is the name given to the ObjectContext when I created the data model. Notice it is wrapped in a using statement. This is because it implements IDisposable and I want to make sure it gets disposed properly. The next line creates a movies variable and sets the Movies property off of the DataModelContainer and then pushes it out to a generic List. The Movies property will give us access to all movies stored in the database. I could constrain this down using a Where clause as I will show momentarily. By default, the Movies property is an IQueryable because it is actually an ObjectSet<Movie**>.** Since I don’t need to perform any additional querying operations, I will push it out to a list which triggers the database call.
A couple things to note here is that this method as it is will only return movie data. This call does not return any actor or director data. Once the context has been disposed, you also cannot use lazy loading to fill the missing data should you need it. This leads us to some options. How you decide to load the data will depend greatly on exactly what data you want. If I know that I always want actor and director data, I can pre-load the data using the Include method:
var movies = context.Movies
.Include("Actors").ToList();
This is known as eager loading and will create a join when the SQL gets generated and all data for both the movies and their associated actors will be returned from the database. If I also want to include the director data I’ll just add another Include statement:
var movies = context.Movies
.Include("Actors")
.Include("Director").ToList();
The string that is passed to the Include method is the navigation property and not necessarily the entity or table name. Since this is a string, if you change the navigation property, you won’t get an error at compile time if it is incorrect in the Include method. If you wanted to also include the actor’s agent you can pass the combined navigation property by separating the secondary with a period:
var movies = context.Movies
.Include("Actors.Agent")
.Include("Director").ToList();
This gives you the movies with all of their actors and the actor’s agents as well as the director of the movie. I now have everything I need to display the data for the view. Note, however, that if you had a lot of movies the result set could be rather large so you only want to pre-load the data that you want.
If you don’t want to preload, you can either write additional methods to pull back the information you want when you need it or you can call the Load method on a collection to load. This method of loading is known as deferred loading. As long as you are still within scope of the ObjectContext you could iterate through the movies and load the Actors property by the Load method:
foreach (var movie in movies)
{
movie.Actors.Load();
}
Using deferred loading would allow you to make a decision on if you wanted to actually load the Actors data or not. This will, however, result in an additional trip to the database, but each trip will be significantly smaller than the large trip that would be done when using eager loading.
The last data loading option is to let lazy loading do the work for you. Lazy loading will kick in when you first try to iterate over the Actors property of a movie and if it has not been loaded, the Entity Framework will make a trip to the database and load the data. This has some pros and cons. On the good side, it lets you not worry about whether your data is loaded or not because it will all be taken care of for you. On the bad side, it will increase your trips to the database and you are not necessarily directly controlling them. Lazy loading will not work once the ObjectContext is disposed so unless you iterate over the Actors property while the ObjectContext is still in scope, it will not work. This means that if you use the above repository class and pass the method result down to your view, lazy loading will not work in the view. If you have done any work with Ruby on Rails, this is a feature that you would likely expect. There is a bright side though as you can make lazy loading work inside the view. It’s a really simple trick. All you have to do is not call the Dispose method by not wrapping the ObjectContext in a using statement. When doing this you are not taking direct advantage of the IDispoable interface, but are rather just letting the .NET Framework dispose the object when you are done using it.
My decision on which method I choose depends on the nature of the application and how much data I can expect it to handle. If it is a smaller application or one where I don’t expect a great deal of data to be processed, lazy loading is a very viable option. I don’t have to worry about making sure my data is pre-loaded and can focus on presenting the data to the user. If it’s the opposite and I want to have more control over the data being loaded, then I will likely opt for a non-lazy loaded approach. There really is no hard and fast rule about which to use. It all really depends on your application and what your data access needs are. Some developers I know swear by lazy loading and others are generally more cautious and less trusting of it. It is really the classic developer answer of “it depends”.
The ObjectContext contains options that can be turned on and off at each call level so you can enable or disable lazy loading on a call-by-call basis. This is done through the ObjectContext.ContextOption.LazyLoadingEnabled property. It can also be turned off globally by changing the option in the property window of the data model or if you are using POCO, you can modify the T4 template. The key to know when working with lazy loading is knowing that it is on and being prepared for any adverse effects it may have on performance.
Dealing with creating the data layer methods, especially for simple CRUD operations, can still be tiresome, although less so than hand-crafting SQL. I have a T4 template up on CodePlex that will make this whole process much simpler. I have always been a fan of code generation where it makes sense but doesn’t also add multiple layers of obscurity. My recommendation to you is if you are going to use any code generation at all (even what is built directly into Visual Studio), learn as much as you can about the generated code. Making yourself more familiar with what the generated code looks like and does will make it easier for you to use and infinitely easier to debug should you run into trouble.
My T4 template is up at http://efrepository.codeplex.com and you can download it for free. It is open source under the MIT license so feel free to use it in commercial applications. There is detailed usage information and several samples on the CodePlex site in the downloads and on my blog (http://www.geekswithblogs.net/danemorgridge) that will give you the information you need to use it beyond what I am showing in the scope of this article.
I like to use Dependency Injection (DI) and I built my t4 template with this in mind. I personally use StructureMap but I have samples working with Ninject as well with samples with different DI frameworks coming in the future. Dependency Injection is not required to use the template, but it can make the testing process much cleaner and it is a method I prefer to use. Basically what DI gives you is a way to resolve the dependencies of classes at runtime. You define interfaces that get used by classes and the DI framework will resolve those for you. There are multiple versions of the template that have the DI baked right in to provide helpers. The basic template is DI ready, but doesn’t have anything baked in. There is one for StructureMap, which is the same as the base template but contains a RepositoryHelper class that makes working with DI simpler by wrapping some StructureMap constructs for you.
To get started with the template, simply copy it into your project in the same folder as a .edmx file and it will do the rest. While there is much more to the templates than I will show here, the classes I will focus on the most are the {Entity}Repository classes that get generated. They are generated as partial classes with a few basic CRUD methods exposed for you. As such, there are two files generated for each entity type:
{Entity}Repository.cs
{Entity}Repsotory.generated.cs
The {Entity}Repository.generated.cs file contains the constructor and all common implementation logic. This file will get overridden every time the T4 generation is run on the template. The {Entity}Repository.cs file is generated only once and is where you will want to store your actual data layer methods. It should never get overridden.
There is an All method that will return all of the entities for that repository. While you can use it directly, I would recommend wrapping it so that you can add additional logic later if necessary. This would change the GetMovies() method to:
public List<Movie> GetMovies()
{
return Repository.All().ToList();
}
The Repository object is a type of IRepository<Movie> with the concrete class of EFRepository<Movie>. The All method is wrapping a call that returns all of the entities of a particular ObjectSet. Calling the All method is effectively doing a select * from table in SQL. The SQL code that gets generated isn’t exactly a select * from table, but it has the same result.
The Repository object also contains a Find method that you will find to be very useful:
public IQueryable<T> Find(Func<T, bool>
expression)
{
return ObjectSet.Where(expression).
AsQueryable();
}
The Func<T, bool> parameter type is actually just a lambda expression so you will pass a lambda directly to this method. We will need a method in our data layer to query a single movie by the movieId so we will add the following method to the MovieRepository class:
public Movie GetMovie(int movieId)
{
return Repository
.Find(m => m.MovieId == movieId)
.FirstOrDefault();
}
As you can see we are passing the movieId and doing a lambda to find the results. This will create a SQL query that will return all entities that match that condition. Since MovieId is the primary key there should only ever be one row returned. Notice that the Find method actually returns an IQueryable, but I only want one movie to come back so I’ll call FirstOrDefault off of the Find method. The FirstOrDefault method will give us the first entity in the result set or return null if it is empty. There is also a First method, but it will throw an exception if the result set is empty. I normally use the FirstOrDefault over First because I would personally rather do a null check than have to handle an exception in most cases. This is, of course, up to you based on your coding practices.
You may also notice that the code calls AsQueryable on the Where method inside the Find method. This is because Where will return an IEnumerable, not an IQueryable. The template also implements the Unit of Work pattern so you need to have the ability to refine the query before it generates SQL and gets executed which cannot be done unless it is an IQueryable. I won’t cover the Unit of Work portion in detail in this article, but you need to know that the IUnitOfWork interface has an ObjectContext property and that is where the real context is stored. This allows you to work with multiple {Entity}Repository classes but still be dealing with one ObjectContext. Most of the time you will only need one {Entity}Repository class, but there will be times when you will need to use more. The CodePlex site and my blog have samples explaining this usage.
The template includes the interfaces and concrete classes that are used. I mentioned the IRepository<T> and the EFRepository<T> briefly. The IRepsoitory<T> is, of course, the interface, but the EFRepository<T> is the actual implementation and is tied to the Entity Framework classes. The EFUnitOfWork is the implementation of IUnitOfWork and contains the actual ObjectContext that is used by the .edmx file. You can use the concrete classes directly or use dependency injection to resolve the dependency at runtime.
To use the StructureMap template, you will need to obviously download StructureMap (http://structuremap.github.com/structuremap), but you will also need to initialize it. Since it is a Dependency Injection framework, it has to know what dependencies it is resolving for and what to resolve them to. For the template you will need to put the following line of code in your Global.asax.cs file in the Application_Start method:
ObjectFactory.Initialize(
x =>
{
x.For(typeof(IRepository<>))
.Use(typeof(EFRepository<>));
x.For<IUnitOfWork>()
.Use<EFUnitOfWork>();
}
);
This tells StructureMap that when I am asking for an IRepository<T> give me an EFRepository<T> and for IUnitOfWork give me an EFUnitOfWork. In your test project, you will want to initialize with your mock objects as EFRepository and EFUnitOfWork contain the Entity Framework specific implementation code. I don’t want to go crazy into detail about how StructureMap works, but if you want to get an instance MovieRepository it has some dependencies that StructureMap can help with. Here is the constructor for it:
public MovieRepository(
IRepository<Movie> repository,
IUnitOfWork unitOfWork)
Notice this takes a IRepository<Movie> and an IUnitOfWork. Now that you have wired up StructureMap to know how to resolve those dependencies you can have StructureMap do that for you. To get a new instance of MovieRepository call the ObjectFactory.GetInstance method in StructureMap:
var movieRepository =
ObjectFactory.GetInstance<MovieRepository>();
The GetInstance method looks at the constructor and sees that it takes interfaces that StructureMap has been wired to resolve and does it for us. You don’t have to worry about messing with the interfaces or the concrete classes directly, which can simplify things greatly. To further simplify this for you, the RepositoryHelper class wraps this functionality for you:
var movieRepository =
RepositoryHelper.GetMovieRepsoitory();
The GetMovieRepsository method makes the same ObjectFactory.GetInstance call so you don’t have to remember to use StructureMap. There are helper methods generated by default for every {Entity}Repository class.
The {Entity}Repository classes also don’t directly call the Dispose method on the ObjectContext so you can use lazy loading in MVC when populating data for your views.
The ASP.NET MVC Side of Things
Now that we have our data layer methods in place it’s time to turn back to the ASP.NET MVC side of the project. On the home page of the app I want to list all of the movies with their respective director. I want to show movie title, director and release year. In the HomeController class I’ll have the Index action which will render the Index view. The action method is very simple:
public ActionResult Index()
{
var movieRepository =
RepositoryHelper.GetMovieRepsoitory();
var model = new HomeModel();
model.Movies = movieRepository.GetMovies();
return View(model);
}
The Index view is strongly typed, which is why you pass the HomeModel as a parameter. This will make the model strongly typed in the view so you have full support for IntelliSense and compile time checking. Note that by default Visual Studio doesn’t build views, but you can turn this feature on. If you unload the MVC Project in Visual Studio and edit the project file you will find a line in the project under the Debug configuration:
<MvcBuildViews>false</MvcBuildViews>
You can also just edit the file with any text editor, but you will have to reload it in Visual Studio anyway if you do it while Visual Studio has the project open. Setting this to true will cause the view to be built with the code and it will give you compile time checking of your views as well. It does take longer for your builds so it is something I normally turn on in my CI (Continuous Integration) server builds. I have a separate target normally for CI so I can skip this option while developing, but I can make sure that the build server checks it as a backup in case something slips through local testing.
Now it’s time to build the view itself. I have the code for the view in Listing 1. Notice it loops through each movie and calls the Director property to access the director name by accessing movie.Director.Name. If the data layer is built to bring back the director there shouldn’t be any problems accessing this data. Movie has a non-nullable foreign key to Director so you know that each movie will have a director; you just have to make sure that this information is actually loaded into the model using whichever technique you wish. This code uses lazy loading since we didn’t explicitly turn it off so if the Director is not already loaded it will be by the Entity Framework when it is first accessed. Both the movie name and the director are links that will take them to each detail page respectively.
The movie detail page is displayed through the Index action on the MovieController as you can see from the Html.ActionLink helper method. This page shows the details for a single movie and lists the actors and the director. The action code looks like this:
public ActionResult Index(string id)
{
int movieId = 0;
int.TryParse(id, out movieId);
var movieRepository =
RepositoryHelper.GetMovieRepository();
var model = new MovieModel();
model.Movie = movieRepository.GetMovie(movieId);
return View(model);
}
The URL this would come on would be /Movie/{id} so assuming that the id is 1, the number 1 would be passed as a string to the Index method. The id comes from the route and will always come through as a string. Because it is a string you’ll need to convert it to an int. I prefer the int.TryParse method to do this. You will want to add some checking here because if the TryParse call fails, you will not have a valid id and will need to handle that by throwing an exception or redirecting the page. I’ll spin up a new MovieRepository and MovieModel. The GetMovie method from the MovieRepository takes the movieId int we got from the string id passed in. You will also need to do some checking here to make sure that the Movie instance returned is actually a real movie and not null. If you passed in either a non-integer value to the action or the id passed in didn’t exist, it would still return the view, but the model in the view would be null and would have to be handled there. I’ll leave it up to you to determine what actions you would want to take and where you want to take them.
Listing 2 shows the code for the view. You can see that I am displaying the movie details, then below that will show the director accessed through the Director property of the movie. Then the actors are listed through the Actors property. Lazy loading will take place here unless you preload the data so you don’t have to worry about not getting the data you need to display. Each actor is linked to the Index view in the ActorController where you’ll do similar methods as we did for movies. This view will list the actor and their details along with their agent all of the movies associated with them. There is also a DirectorController and AgentController that performs the same types of display functions and the implementation is the same as with the MovieController.
Editing Data
We have the code necessary to display the data so now we need to be able to make changes to the data. I’ll show you how to build an add and edit page for movies. This will add two new actions and views to the project. Listing 3 & Listing 5 show the four new actions added to the MovieController. Their methods are Add, AddSubmit, Edit and EditSubmit. The Add method is parameterless but notice the attribute of [HttpGet]. This signifies that this action will only get called when the HTTP verb is “GET”. The AddSubmit has the [HttpPost] attribute and also has several parameters. This will only get called when the HTTP verb is “POST”. The parameters to this action method are the form variables from the form in the Add view.
The Add method simply displays the view which contains the form. Here is the first time we have a model that contains more than just the entity we want to work with:
public class MovieAddModel
{
public SelectList Directors { get; set; }
public MultiSelectList Actors { get; set; }
}
The model contains directors and actors because we want to be able to set the directors and actors that are to be associated with this movie. We need the data passed to the view so that we can populate select lists. Listing 4 shows the Add view. We want to generate a single-item select list for the directors and a multi-select select list for the actors since a single movie will have one director and multiple actors. We’ll use the data from the model to create those lists.
A form submit on the Add view will execute the AddSubmit action method which takes in all of the form variables to create a new Movie entity. Here is where the MovieRepository comes back into play. We know since we are adding a new entity and don’t have an id we can just create a new entity. You may want to add checking here to make sure you are not indeed adding a duplicate and you may want to check on movie title or such. Looking back to Listing 3, you can see that we create a new Movie entity and fill the parameters from the form variables. It would be wise to add validation to this, but for the simplicity of the example I have left that out.
Once I have the new Movie entity, I need to make sure it is referencing the associated director and actors. With EFv4, we now have access to the foreign keys so we can simply set the DirectorId property of the movie to the id that came through the form post. With the actors, however, it’s not that simple since there are multiples. We also don’t want to create new actors since they already exist. What we will do is loop through the ids that came back from the form post and get the actors associated with those ids so we can associate them with the new Movie entity. We will inherently run into an issue here if we use the repository classes as we have been since the ActorRepository would be using a different unit of work and thus a different ObjectContext. With Entity Framework, you cannot combine objects with one context into those from another. So what you have to do is create a unit of work separately and make sure that each repository class uses that unit of work.
Each Get{Entity}Repository method in the helper has an overload that will take an IUnitOfWork. There is also a helper class to get an IUnitOfWork. In Listing 3 you will see that the first three lines are:
var unitOfWork = RepositoryHelper.GetUnitOfWork();
var movieRepository =
RepositoryHelper.GetMovieRepository(unitOfWork);
var actorRepository =
RepositoryHelper.GetActorRepository(unitOfWork);
This method has one IUnitOfWork that gets passed to both repository classes and thus, both classes share the same object context. Now when you loop through the actor ids from the form post you can query for an actor and then add that actor entity to the Actors property on the Movie entity. When you’re all done, you simply call the unitOfWork.Save() method, which will call SaveChanges on the ObjectContext and persist the data to the database. Each {Entity}Repository class has a Save method also that will in turn call the Save method on the associated IUnitOfWork, so you could call save on either the MovieRepository or the IUnitOfWork, or “technically” you could call it on the ActorRepository, but that would add unneeded visual complexity to the code. Once save is called, the action method will return and display a view that simply displays a message saying that the save was successful.
The edit methods are very similar. An Edit method takes in a string id parameter with the movie id. The model also has a Movie parameter along with the directors and actors:
public class MovieEditModel
{
public Movie Movie { get; set; }
public SelectList Directors { get; set; }
public MultiSelectList Actors { get; set; }
}
The Movie parameter is added because you want to pre-fill form fields with the data from the existing movie. The rest of the process is pretty much the same. The code fills the form with the data from the model. Now, however, you’re setting the selected states on the director and actor select lists (see Listing 6 for the view). If the form were submitted and no changes were made you should expect no changes to the data.
Since we are dealing with a many-to-many relationship between the movie and actors we need to be careful that we don’t duplicate data and that if an actor is removed from a movie that it gets handled properly. To handle this we need to check the existing Actors property when looping through the actor ids to ensure that an actor doesn’t get added twice. We also need to make sure that any actors that have been removed are properly removed from the data. The easiest way to meet both requirements is to clear the Actors property before adding the ones that were selected on the form.
Once the form is submitted and the movie has been saved a view will be displayed similar to the AddSubmit that will state that the data has been successfully saved. Similar forms are also setup for directors, actors and agents, but will function the same as the Add and Edit for movies.
Summary
Just as ASP.NET MVC has made building web applications easier, the ADO.NET Entity Framework has made building data connected applications easier. The Entity Framework is not the only ORM tool out there, but it is Microsoft’s data access strategy moving forward so it is something that you want to keep an eye on. The Entity Framework team made a lot of good changes and I am excited to see the path it will continue to make. If you haven’t taken the time to really dig into either ASP.NET MVC or the Entity Framework, now is the time.
Listing 1: Home/Index.aspx View
<%@ Page Language="C#" MasterPageFile="~/Views/Shared/Site.Master"
Inherits="System.Web.Mvc.ViewPage<EfMvcCodeMag.Web.Models
.HomeViewModel>" %>
<asp:Content ID="Content1" ContentPlaceHolderID="TitleContent"
runat="server">
Home Page
</asp:Content>
<asp:Content ID="Content2" ContentPlaceHolderID="MainContent"
runat="server">
<h2>Movie List</h2>
<table>
<tr>
<th>Title</th>
<th>Release Year</th>
<th>Director</th>
</tr>
<% foreach(var movie in Model.Movies) { %>
<tr>
<td><%= Html.ActionLink(movie.Title, "Index",
"Movie")%></td>
<td><%= movie.ReleaseDate.Year %></td>
<td><%= Html.ActionLink(movie.Director.Name, "Index",
"Director")%></td>
</tr>
<% } %>
</table>
</asp:Content>
Listing 2: Movie/Index.aspx View
<%@ Page Language="C#" MasterPageFile="~/Views/Shared/Site.Master"
Inherits="System.Web.Mvc.ViewPage<EfMvcCodeMag.Web.Models
.MovieModel>" %>
<asp:Content ID="Content1" ContentPlaceHolderID="TitleContent"
runat="server">
Movie : "<%= Model.Movie.Title %>"
</asp:Content>
<asp:Content ID="Content2" ContentPlaceHolderID="MainContent"
runat ="server">
<h2><%= Model.Movie.Title %></h2>
<%= Model.Movie.Description %>
<br />
Rating: <%= Model.Movie.Rating.ToString() %>
<br />
Release Date: <%= Model.Movie.ReleaseDate.ToShortDateString() %>
<br /><br />
Director: <%= Html.ActionLink(Model.Movie.Director.Name, "Index",
"Director") %>
<br /><br />
Cast:
<br />
<% foreach (var actor in Model.Movie.Actors) { %>
<%= Html.ActionLink(actor.Name, "Index", "Actor") %><br />
<% } %>
</asp:Content>
Listing 3: MovieController.cs - Add & AddSubmit methods
[HttpGet]
public ActionResult Add()
{
var model = new MovieAddModel();
var directorRepository =
RepositoryHelper.GetDirectorRepository();
var actorRepository = RepositoryHelper.GetActorRepository();
model.Directors = new
SelectList(directorRepository.All().ToList(),
"DirectorId", "Name");
model.Actors = new
MultiSelectList(actorRepository.All().ToList(),
"ActorId", "Name");
return View(model);
}
[HttpPost]
public ActionResult AddSubmit(string title, string releasedate,
string rating, string description, int director, int[] actors)
{
var unitOfWork = RepositoryHelper.GetUnitOfWork();
var movieRepository =
RepositoryHelper.GetMovieRepository(unitOfWork);
var actorRepository =
RepositoryHelper.GetActorRepository(unitOfWork);
var movie = new Movie();
movie.Title = title;
movie.ReleaseDate = DateTime.Parse(releasedate);
movie.Rating = double.Parse(rating);
movie.Description = description;
movie.DirectorId = director;
foreach( int actorId in actors)
{
var actor = actorRepository.GetActor(actorId);
if (actor != null)
movie.Actors.Add(actor);
}
movieRepository.Add(movie);
unitOfWork.Save();
return View();
}
Listing 4: Movie/Add.aspx View
<%@ Page Language="C#" MasterPageFile="~/Views/Shared/Site.Master"
Inherits="System.Web.Mvc.ViewPage<EfMvcCodeMag.Web.Models
.MovieAddModel>" %>
<asp:Content ID="Content1" ContentPlaceHolderID="TitleContent"
runat="server">
Add Movie
</asp:Content>
<asp:Content ID="Content2" ContentPlaceHolderID="MainContent"
runat="server">
<h2>Add Movie</h2>
<% Html.BeginForm("AddSubmit","Movie"); %>
<table>
<tr>
<td>Title</td>
<td><%= Html.TextBox("title") %></td>
</tr>
<tr>
<td>Release Date</td>
<td><%= Html.TextBox("releasedate") %></td>
</tr>
<tr>
<td>Rating</td>
<td><%= Html.TextBox("rating") %></td>
</tr>
<tr>
<td>Description</td>
<td><%= Html.TextArea("description") %></td>
</tr>
<tr>
<td>Director</td>
<td><%= Html.DropDownList("director", Model.Directors)
%></td>
</tr>
<tr>
<td>Actors</td>
<td><%= Html.ListBox("actors", Model.Actors) %></td>
</tr>
<tr>
<td></td>
<td><input type="submit" /></td>
</tr>
</table>
<% Html.EndForm(); %>
</asp:Content>
Listing 5: MovieController.cs - Edit & EditSubmit methods
[HttpGet]
public ActionResult Edit(string id)
{
int movieId = 0;
int.TryParse(id, out movieId);
var movieRepository = RepositoryHelper.GetMovieRepository();
var directorRepository =
RepositoryHelper.GetDirectorRepository();
var actorRepository = RepositoryHelper.GetActorRepository();
var movie = movieRepository.GetMovie(movieId);
var model = new MovieEditModel();
var selectedActors = (from a in movie.Actors
select new {a.ActorId}).ToList();
model.Directors = new
SelectList(directorRepository.All().ToList(),
"DirectorId", "Name", movie.DirectorId);
model.Actors = new
MultiSelectList(actorRepository.All().ToList(),
"ActorId", "Name", selectedActors);
return View(model);
}
[HttpPost]
public ActionResult EditSubmit(string id, string title,
string releasedate, string rating, string description,
int director, int[] actors)
{
var unitOfWork = RepositoryHelper.GetUnitOfWork();
var movieRepository =
RepositoryHelper.GetMovieRepository(unitOfWork);
var actorRepository =
RepositoryHelper.GetActorRepository(unitOfWork);
int movieId = 0;
int.TryParse(id, out movieId);
var movie = movieRepository.GetMovie(movieId);
movie.Title = title;
movie.ReleaseDate = DateTime.Parse(releasedate);
movie.Rating = double.Parse(rating);
movie.Description = description;
movie.DirectorId = director;
movie.Actors.Clear();
foreach (int actorId in actors)
{
var actor = actorRepository.GetActor(actorId);
if (actor != null)
movie.Actors.Add(actor);
}
unitOfWork.Save();
return View();
}
Listing 6: Movie/Edit.aspx View
<%@ Page Language="C#" MasterPageFile="~/Views/Shared/Site.Master"
Inherits="System.Web.Mvc.ViewPage<EfMvcCodeMag.Web.Models
.MovieEditModel>" %>
<asp:Content ID="Content1" ContentPlaceHolderID="TitleContent"
runat="server">
Edit Movie
</asp:Content>
<asp:Content ID="Content2" ContentPlaceHolderID="MainContent"
runat="server">
<h2>Edit Movie</h2>
<% Html.BeginForm("EditSubmit","Movie"); %>
<table>
<tr>
<td>Title</td>
<td><%= Html.TextBox("title",Model.Movie.Title) %></td>
</tr>
<tr>
<td>Release Date</td>
<td><%= Html.TextBox("releasedate",
Model.Movie.ReleaseDate.ToShortDateString()) %></td>
</tr>
<tr>
<td>Rating</td>
<td><%= Html.TextBox("rating", Model.Movie.Rating) %></td>
</tr>
<tr>
<td>Description</td>
<td><%= Html.TextArea("description",
Model.Movie.Description) %></td>
</tr>
<tr>
<td>Director</td>
<td><%= Html.DropDownList("director", Model.Directors) %>
</td>
</tr>
<tr>
<td>Actors</td>
<td><%= Html.ListBox("actors", Model.Actors) %></td>
</tr>
<tr>
<td></td>
<td><input type="submit" /></td>
</tr>
</table>
<% Html.EndForm(); %>
</asp:Content>
