





Software development is a collaborative process.
This article is the second in a series focused on the tools and techniques developers use to effectively work in concert. This time, we look at a Web-based phenomenon, known generally as wiki, which has the potential to arm your distributed team with a fluid, open and low-noise forum for building and managing project artifacts as well as foster a collective knowledge and project continuity.
The last article in this series looked at source control tools that allow Web-based source control for disconnected teams. While source code is an important part of any software project, the resources that need to be shared do not end there. In any project, there is always a growing body of knowledge (including terms of reference, meeting notes, use cases, requirements, documentation, timelines, time sheets, milestones, results, etc). This article examines implementing a wiki website to share project information among developers and other project stakeholders.
What is a Wiki?
A wiki is basically an interactive website?a simple text-based repository of topics that can be created and hyperlinked simply and “in context” by peers over the Web. The data contained in wiki topics can be categorized, searched and accessed in unlimited ways. Due mostly to their simple text-based nature, wikis are accessible from any Web browser and, depending on what you require, wiki applications are free or are available for a fee.
When team members add, edit or remove content in a wiki, they are leveraging their knowledge among all users of the wiki.
A wiki is different from a message board, listserv or email folder in that it is “topic-centric” rather than “message-centric.” In a traditional wiki, all content is editable all the time. So any peer can edit and update content and this ongoing peer review applies continuously to all topics.
In a wiki, like all data and document systems, you reap what you sow. The end result of a wiki is a body of knowledge that all peers on a team contribute to, acknowledge and understand. At the outset, this is a lot to wish for any team?to be on the same page on as many facets as possible. This is what a wiki can bring to your development team.
So, Technically Speaking, What is a Wiki?
Specifically defining the technical aspects of a wiki is tough because there are many different flavors of wiki and there are even more “wiki-esque” technologies that blur the definition somewhat. However, here is our attempt at a generic definition:
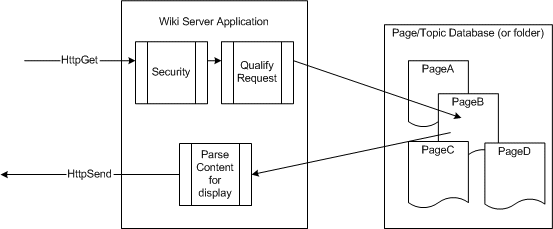
A wiki runs in a wiki server. A wiki is software that runs on a Web server to enable it to store and respond to requests for wiki content. “Wiki Content” can best be described as a set of pages (also called topics), which are plain text and may be hyperlinked. The typical wiki server provides the following base set of features:
- Pages may be manipulated in any standard Web browser.
- Requested pages are parsed before they are served for viewing. This parsing allows for simplifying nomenclature to be used in place of more traditional HTML markup.
- Pages, and hyperlinks between pages, may be added or modified in any browser.
- Change logs are maintained and content rollbacks are possible for any edited pages.
- A global search form enables users to search for any word or phrase in all wiki topics.
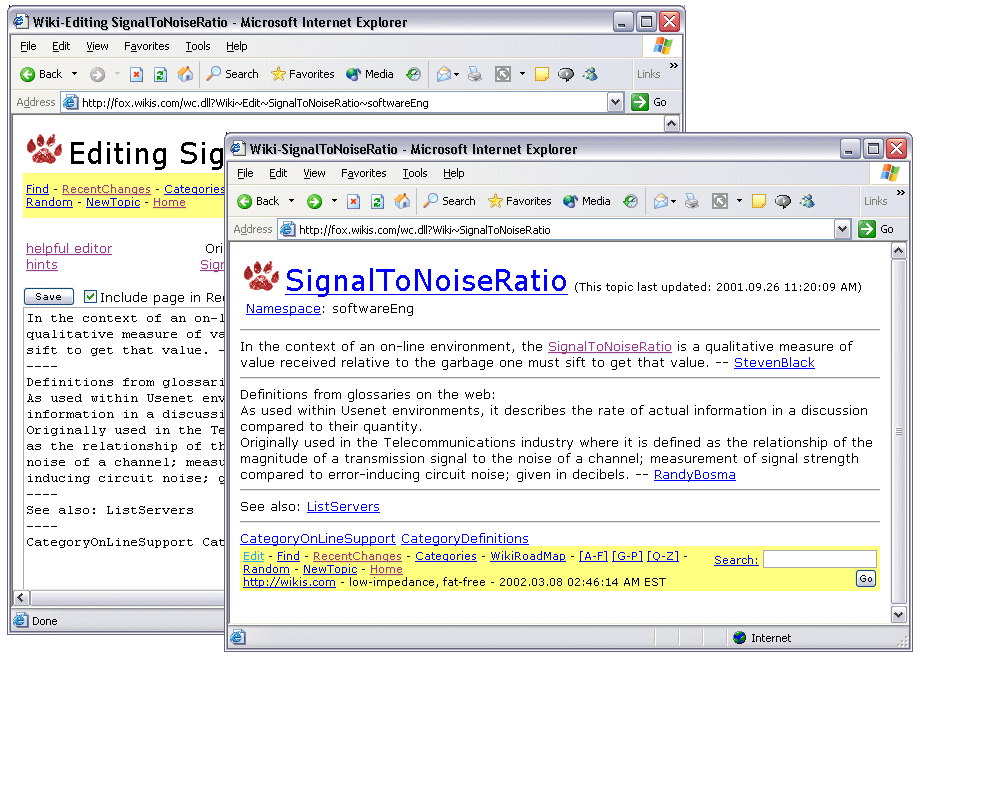
Figure 1 provides a schematic of the architecture of a basic wiki server. In short, you have a set of linked hypertext documents that can be edited from any browser by people who do not posses knowledge of the finer points of HTML markup. Figure 2 shows a typical wiki page, as seen in view and edit modes.
The Development Case for Project Wiki
Because they are Web-based, wikis offer great value to groups who design and build software. For example, we typically start a wiki with each major project and give all stakeholders access to it. As the development proceeds from inception to implementation, all stakeholders are able to click directly into a context-sensitive discussion of the tasks at hand and to add their comments as appropriate.
With its fluid structure, a wiki provides a globally accessible project scrap book that can grow and mirror your development project.
With its fluid structure, a wiki provides a globally accessible project scrapbook that can grow and mirror your development project. Because everyone is an editor, dated content can be revised at will.
Here are some of the so-called project artifacts that may be formally or informally stored, versioned, and kept alive and relevant using a wiki. These items are listed by who normally maintains these artifacts, though, of course, everyone has access to them.
Project sponsor: Project vision, business process documentation, project boundaries and identification of stakeholders.
Project support personnel: IT infrastructure documentation (lists of servers, IP addresses, drive mapping procedures, server configuration procedures and server configuration history). Links to third-party software installations, license keys and patches. Documentation of remote access procedures and timelines.
Project manager: Software development plans (iteration and phase plans, deployment plans, schedules, testing plans, training plans. acceptance tests, risk lists). Development reports, status assessments and problem resolution plans. Time reporting procedures and templates for claims and expenses, checklists, disaster recovery procedures and FAQ's.
System analyst: Business glossary, business rules, use cases, software architecture documents, detailed design models, detailed data models and supplementary specifications, including references to models and other documents kept in the file system and accessed by other applications.
Developers and subcontractors: Meeting notes, prototypes, interface mockups and walkthroughs, component documentation, to-do lists, done tasks lists, time sheets, availability, personal schedules and information, and release notes. Other uses include heads-up “whiteboard” and sundry housekeeping topics, documentation of build procedures and documentation of supporting tools.
It's All in the Parsing
It is likely that most readers of CODE Magazine are familiar with using and building dynamic websites, where the content sent to the user is pulled from a database, transformed on the fly and sent to the user. In dynamic websites, the complete document does not actually exist on the server; rather it is re-composed for each request by a server-side software application.
A wiki's back-end data structure is simple. The content is text, usually stored exactly as a user has entered it, which otherwise contains no HTML markup or other special encoding. Most of the work done by a wiki server is parsing patterns in the text into display markup, such as HTML.
This intelligent use of parsing is important because it allows content creators (which, remember, are the readers of the wiki) to concentrate on content and not on the vagaries of encoding and markup. The server does the work of parsing to create suitable display markup, automatic link creation and summarization.
There are limitless sorts of parsing that may take place in a wiki. For example, if a person were to enter:
Important things to remember:
* document **why** not what
* run unit tests prior to check in
* program to interface not implementation
* practice ManualGarbageCollection
* don't burn popcorn in the microwave
When this content is requested, a typical wiki server might parse it as follows:
Important things to remember:<br>
<ul>
<li>document <strong>why</strong> not what
<li>run unit tests prior to check in
<li>think interface not implementation
<li>practice Manual Garbage Collection
<li>don't burn popcorn in the microwave
</ul>
The code would then be rendered in the browser, as seen in Figure 3. If you look carefully at the pre- and post-parse content above, you'll note at least three different parsing tasks.
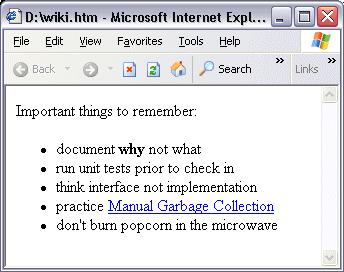
Table 1 shows a partial list of some of the parsing we've seen in various wikis on the Web.
Each wiki seems to have its own parsing idioms. Some wikis allow embedding HTML markup, XML islands and <SCRIPT> segments, while others don't. But the rules of individual wikis are typically simple and quick to learn.
The result of all the automated parsing is that content is easily authored and modified, and the rendered content looks nice in a browser and automatically contains useful hyperlinks to other topics and resources. For users who do not know HTML, you can imagine that using * for a bullet rather to than
Extending Wiki
An important attribute of a typical wiki is the fact that the content repository is kept in plain-text. This allows you to utilize an entire field of plain text-based open technologies: XML, Latex and MathML to name a few. Mining information and extending a wiki repository is often simply a matter of parsing text.
The extent to which your team can share, transfer and act upon corporate knowledge will have a direct impact on how effective your team is.
Depending on the accessibility of the wiki data, ambitious parsing and services are possible. For example, topics whose names fit a pattern, such as beginning with “UC” to identify a use case, and coupled with text templates to which writers adhere, can be specially treated by different parsing technologies. We've seen a wiki parser able to summarize hundreds of use case topics into a single summary view, as well as create a Rational Rose use case model from which all use case interrelationships and dependencies are grouped. Consider tools like this, combined with the flexibility of XML, and the possibilities are endless.
Say, for example, your firm uses a standard format for its software requirements documents. You could develop an XML template for requirements that would help users comply with the agreed format. Of course, that template would include areas for free-form notes and discussion on the requirement, but the basic structure would serve to remind people what the base components of a requirement are. Clearly, it would be counter-productive to have users editing raw XML, so variations on edit forms would be required. Some sort of “smart edit form rendering” is needed to present users with a logical edit form for each topic type.
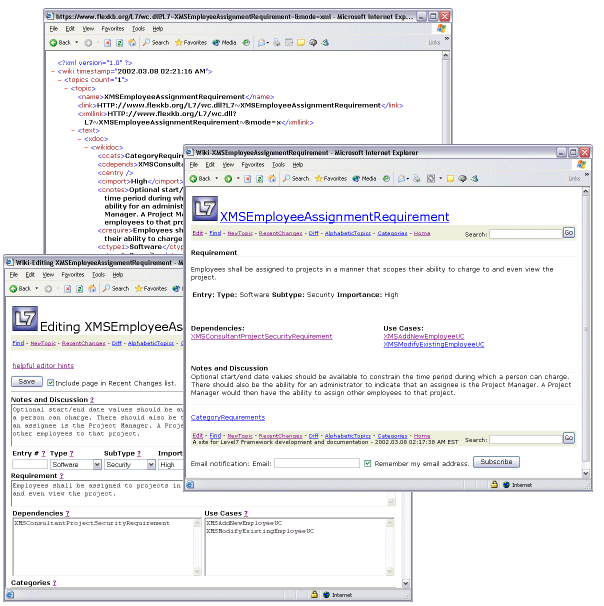
Figure 4 shows one such topic, the edit form provided for it, and the underlying XML stored in the page repository. If XML is used to persist the structure in the page repository, the wiki server can, in turn, provide value-added services, such as reports of software requirements organized by importance, number of use cases and other criteria. The wiki server can generate these reports or, with the use of client-side XSL, they can be generated remotely, even automatically, on a daily basis for project sponsor updates.
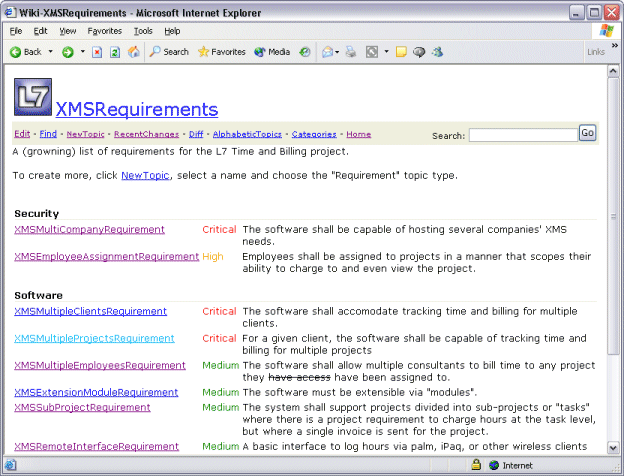
Another example of where a little structure can pay great dividends is bibliography management. Rather than entering lists of references needed for your knowledge base into free-form text, you can take advantage of a structure for “reference” topics. This would allow, for example, searches by “author” and automatic topic footnoting, and even full bibliography generation to be provided by the wiki server.
No Silver Bullet (as usual)
As always, you get out of knowledge management what you put into it. Introducing an established team to “the wiki way” can be an exciting exercise in office politics. However, if key players agree to participate, and a workable strategy is identified, it can be a successful transition. Keep in mind that it can be difficult to motivate people to change their work habits.
E-mail is such an easy medium: you send a message and now the ball is in the other person's court, so you can move on. Encourage your team to realize that by writing e-mail messages they are generating mostly noise and very little usable knowledge, and that knowledge is difficult to share later as it lies in someone's inbox. When team members add, edit or remove content in a wiki, they are leveraging their knowledge among all users of the wiki.
And that, in our opinion, is the crux of the matter. Since wikis are topic-based, everything about a particular topic can be found in one place. Items related to a topic are links. It's easier for everyone to be “on the same page” if there is a clearly defined place where everyone can share the same information.
Wikis are accessible from any Web browser and, depending on what you require, wiki applications are available free or for a fee.
As always, there are downsides to this form of knowledge management. Like all information repositories, if people don't actively update, edit and organize the information, then what you get isn't the best quality. So, if you collect requirements but then don't update them as the requirements change, you find the wiki contains outdated requirements. At least the problem is not inconvenience or otherwise difficult access when such documents are kept in a wiki.
Conclusion
Perhaps the most compelling argument for wikis as a collaborative tool is that they work now. They are not based on some upcoming standard waiting to be adopted by industry; they work now with readily available and low-cost technology. If you have a Web server, you can set one up in literally five minutes. For inexpensive, effective Web-based collaboration that works today, it's difficult to beat a wiki.
Table 1: Parsing in various wikis on the Web
| User Enters | Parser Renders | Comment |
|---|---|---|
| A CamelCaseWord | A link to another wiki topic. | All wikis. |
| Words starting with "http://" or "www." or "ftp://" | Links to the implied address | All wikis. |
| Lines starting with "----" | Insert a graphical line | All wikis. |
| Strings like "RecentChanges" | Links to trigger generative reports and specialty processing. | All wikis. |
| Words containing "@" and "." | Email links. | Some wikis. |
| Strings like "D:`\xxx\xxx.xx` | File links | Some wikis. |
| Lines starting with * | List item | Some wikis. |
| Words surrounded with "**" | tag around the word | Some wikis. |
| Strings like "ISBN NNN..." | Links to a bookseller. | Some wikis. |
| Strings like "QNNNNNN" | Links to MS Knowledgebase articles | Some wikis. |
| Strings like "Message NNN" | Links to associated message boards | Some wikis. |
| Strings like "Category%" | Special cross-referencing and aggregation. | Some wikis. |
| Malformed HTML | Well formed HTML | Some wikis. |
| Strings like "xx::XxxXxx" | Links to topics in other wikis | Some wikis. |
