


As an Italian student, I spent my high school years trying to please teachers with my understanding of Dante's “The Divine Comedy.” As Wikipedia explains, “The Divine Comedy” is an epic poem written by Dante Alighieri in the early 1300s. Unanimously seen as one of the greatest pieces of the world literature, the poem has inspired many other books - even in modern literature, such as latest Dan Brown's novel, “Inferno.” The poem's substance is quite out of the ordinary: It offers an allegorical vision of the afterlife as it was perceived at the time.
Mindful of the poem, I thought out this article as a modern developer's journey toward code of quality. In analogy with the poem, this article will go through Hell, Purgatory, and Heaven of software. Opinions may be quite strong and, while I'll try to argue each, there's nothing wrong if you happen to disagree with some of them. If that happens, don't hesitate to get in touch via Twitter (my handle is @despos) or my blog at software2cents.wordpress.com.
A modern software comedy may begin like the original poem. Midway in the journey of our careers, we find ourselves in an intricate dark forest where the clear path of writing software is lost. It's really hard to tell the nature of the forest - it's messy, dense, and harsh - and the very thought of it renews my fear.
Software Hell
Hell is a place of eternal torment. In many religious traditions, Hell is a place that some reach in their afterlife. For developers, Hell is a place on earth. A few technologies as well as some approaches and methodologies, contribute to torment developers. Sometimes, developers are responsible for their own pain; sometimes they passively suffer the consequences of other developers' choices with no real power of intervening and changing things. Here's my current list of seven core issues of software development that can lead the world of software shortly to be a less than an ideal place.
#1 NuGet is Down. Long Live NuGet!
NuGet is the de-facto package manager for the .NET Framework. NuGet acts as a repository for frameworks of any type and allows you to add source files and binaries directly to your Visual Studio project. In this regard, NuGet provides the foundation for solving a fairly thorny problem: simplifying and automating the configuration of projects and streamlining the reuse of code and services. Introduced some four years ago, NuGet today is a widespread ecosystem of components. The overwhelming success of NuGet - over 20 million downloads per month as of Spring 2014 - definitely changed the way organizations work. NuGet definitely impacts the application lifecycle management in a company, including source control, continuous integration and delivery settings. The most popular slogan used to advocate NuGet in companies is “it solves the dependency Hell;” the version for executives is slightly different and sounds like “a way to automate our development process.”
I do use NuGet and I'm happy to have it. The world is a better place with NuGet used as a central repository of components. It's great to have a well-known place to go to grab, say, the jQuery library. And it's great that such a repository is fully integrated into Visual Studio. You don't need to surf the Web to find the exact website from which jQuery can be downloaded, not to mention all the dependencies that a particular package can have.
So why am I - a latter-day Dante - treating NuGet as a potential threat for the future of software and placing it in software Hell? It's because of the concept of “contrapasso” being used to determine punishment in the Divine Comedy. Contrapasso is a sort of counter-penalty and consists of a punishment that's the opposite of the sin. What's the sin of NuGet then?
Call me an old-fashioned guy, but I still believe that nearly all aspects of software development should be taken under control by human developers. I can accept that SQL and x86 code are generated for me by some tools. Auto-generated SQL and x86 code comes out of years of experimentation. Furthermore, I can still control those processes via switches and command line parameters. I consider NuGet a tool; as a developer I use tools but I don't like to have tools use me.
Recently, in a conversation with a friend, I shared similar ideas about NuGet. “What?” he said. “You don't like NuGet? Are you aware that in this new world, that's like saying that you don't like assemblies? How can you write .NET applications without assemblies? Similarly, you soon won't be able to handle projects without NuGet. All dependencies will come in the form of NuGet packages. NuGet is going to be mainstream. You'll have to get used to it. You have no chance to avoid it.”
That's precisely what scares me: It's not NuGet per se as a package manager; it's the deep binding between development and such pervasive tools. What if NuGet servers go down? What if NuGet fails in some other way?
My worries are that complexity can explode and make the whole thing painful to manage. One thing is that Nuget acts as a plain and simple package manager; another thing is the message out of TechEd 2014 that all future .NET bits and pieces will come through NuGet. I recently ran into a couple of situations that scare me if I imagine projecting them into even more widespread use. I can't say why that happened, but a package of mine just disappeared overnight and a customer pointed that out on a forum. We had to republish. No big deal, but its 100% dependency on NuGet that gives me cold shivers down my spine.
Then, a developer on my team released a buggy version of a product; he said the bug was triggered by updating a NuGet package. Clearly, NuGet has no responsibility in this - we blamed the developer - but what gives me even more cold shivers is that we grew up a generation of developers that blindly depends on tools to manage dependencies. And we blindly install updates as soon as they become available and only because they're available. I really don't know if one day we'll build software by plugging black-box components in and out. That kind of dream has been in the works for at least two decades. We never had anything like NuGet, but we probably had something (and I think of VBX components of the 1990s) that really looked like true software black-boxes.
Imagine the Hell of having NuGet down when you're configuring your project.
Today, I see the software industry midway in the journey towards happiness. NuGet seems to show the way; we all wish to get there, but at the moment, I honestly think that today's NuGet is too green for such a responsibility. But feel free to think that it's just me getting too old too fast!
#2 A Word or Two about ASP.NET vNext
The future of .NET is before us. More than a decade after its introduction, the .NET Framework is widely used and alive and kicking. The world of a decade ago was completely different. The theme of scalability was rising, testability and dependency injection were merely abstract concepts, and a cloud was a mass of water drops suspended in the atmosphere, hiding the sun. In addition, the crystal balls of the time were inspired by the YAGNI principle - you aren't going to need it - so the .NET machinery was devised irrespective of forthcoming scalability, dependency injection, and cloud concerns. Some fifteen years later, it's time for a redesign: this is vNext, which was first unveiled at TechEd 2014.
The key thing that's going to change is the landing of .NET on the server through a new wave of ASP.NET and .NET services specifically devised in light of use in a server environment - any server environment that is foreseeable at this time.
According to disclosed information at the time of this writing, the pillars of vNext for both .NET and ASP.NET can be summarized in the following three points:
- Lean and mean .NET stacks that are tailor-made for use in the cloud
- ASP.NET and .NET stacks are designed end-to-end in a loosely coupled way
- .NET components are available as NuGet packages (including Base Class Library and CLR)
I completely understand the good sense of the first point and couldn't agree more. Having a cloud-optimized design for the entire .NET stack is a move toward the future, rather than in the right direction. Right or wrong as the cloud can be, it's going to be in our future for the next few years. Adapting the .NET machinery to the cloud is timely and just right. Without beating around the bush, scalability today passes through replicating the Web stack via Azure roles rather than building an insanely powerful - but single - Web stack. As I see it, the cloud-optimization of ASP.NET vNext just makes this scenario easier to achieve and more effective than ever.
In addition, the redesign of .NET vNext builds on composability applied to the CLR. The CLR of the future will be articulated in composable building blocks so that each .NET application - possibly in individual Azure roles - can pick up only the core CLR parts it really needs. This fact triggers a couple of interesting and pleasant side-effects. One is the efficient use of resources and the subsequent achievement of the highest level of performance and scalability possible. The other pleasant side-effect is a better way to handle breaking-change scenarios in large Web applications. The new .NET architecture enables true side-by-side execution for different configurations of the .NET Framework, even those self-contained per application.
The entire .NET and ASP.NET stacks were designed paying particular attention to dependencies. Dependency injection is ultimately the most popular pattern that turns the Dependency Inversion principle - the D in the SOLID acronym - into reality. Dependency Injection is not the only pattern you can use - another equally effective pattern is Service Locator, also from the SOLID acronym. The main difference between Dependency Injection and Service Locator lies in the fact that the former is more suitable for newly built frameworks. The latter lends itself more to expanding and extending existing software. Both patterns allow you to inject dependencies into a stack and in so doing, enable you to unplug the default implementation of some existing functionality and roll your own.
Injectable dependencies bring the level of coupling in a software system down to a bare minimum. This improves the overall testability of the system but also makes it possible to turn on and off undesired features. Specifically related to ASP.NET, this also means that dependencies on IIS and the old core of ASP.NET are being removed.
#3 Over-Design (and Lack Thereof)
Software isn't math, although math is at the foundation of all software. When you study math, it's all about taking an idea to its root. In math, abstraction and theoretical demonstrations are often the sole goal. Software is a different world. When object-oriented methodologies got introduced, it took a few months for some people to dream of a perfect world in which everything was an object with properties and methods. Any object had its parent and its relationships. The resulting Web of objects for a domain looked like a well-balanced graph with objects down the stack inheriting from parents. A developer at work was like a god creating the world.
It didn't stay like this; only a couple of years after being used, one of the pillars of object-oriented programming - inheritance - was labeled as “unfit” in a landmark book, “Design Patterns: Elements of Reusable Object-Oriented Software” written by the popular Gang of Four (Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides). In that book, the Gang of Four say that you'd better use composition over inheritance. Composition is safer for the resulting code especially when developers play God at work.
More recently, when service-orientation was in primetime news, someone attempted to sow the provocative seeds of every class as a service. That didn't work either. I guess the next up is NuGet being sold in some way as the future of software. The funny thing is that the future of software is constantly being redefined according to slogans like “use our framework for the rest and just do your own things yourself.” Periodically, the number of things to do yourself reduces and the “rest” grows bigger and bigger. It's as if all real-world software could be reduced to a mass of similar-looking procedures and processes.
While the role of software in everyday life is growing overwhelmingly big, we tend to have a single runtime to take care of most things and limit our domain-specific efforts as much as possible. To keep up with literary references, the unified runtime that takes care of the rest looks like Big Brother in the “1984” novel by George Orwell.
Software is about design; neither over-design nor under-design are suitable options. Over-design results from the attempt to generalize a domain to abstract specific aspects to a more general behavior. Concretely, extensive use of IoC frameworks is a sign of possible over-design. Let me give you an example taken from personal experience. My son is the classic teenager who attempts to get summer jobs to cover expenses that the strict policies of the family budget won't otherwise cover. So he's now busy writing a Windows 8 application. He's a child of his time and nobody is able to write code without Google or StackOverflow anymore. Searching for help on a particular issue, he ran into a framework wrapping up a popular IoC framework. The code presented in the post worked well, so my son incorporated the wrapper and the IoC. When he proudly showed me his work, I questioned the use of the IoC. He couldn't justify why he needed it because all he needed was the code within the demo using the IoC framework and related wrapper. To cut a long story short, all that my son needed was something like this:
var navigator = new DefaultStartupNavigator(settings);
He ended up with something like this instead:
var navigator = IoC.Get<IStartupNavigator>();
There were no tests in the code and nothing that could really justify the use of an IoC instead of a plain New statement. When I asked him why he opted for an IoC, the answer was “I think this is what professional developers do; I just want to learn. I could even change the interface name and still get an instance.” Right, this is what an IoC does for you. Unfortunately, in the specific scenario, instead of a plain constructor call passing a collection of cached settings, he was going through a lot of reflection to figure out convention class names that could match IStartupNavigator, and instantiating one of them after having resolved dependencies on the constructor. This is over-design: a mess done with the best intentions.
My son is, at the moment, just a hobbyist, although he's published a few apps in various marketplaces. Other junior developers, and even a couple of young architects, around my company take a similar approach to coding. They Google for examples and bring in whatever they find that makes it work. Or, they search NuGet for a suitable package and bring whatever it links in. It can still be manageable if it's one application and only a few additional packages. If this becomes the canonical way of working, well, the future is not going to be any fun. But, again, I hope it's just me getting too old too fast!
Today's youngsters are, as users, much less forgiving with applications than any previous generation of users.
What about under-design? It's still a mess, but done with worst intentions; almost deliberately. However, I'd say that under-design can be more easily improved than over-design.
#4 Misunderstanding Domain-Driven Design
Software mirrors real life and life follows well-known rules defined in the context of some model. Rather than looking for increasingly powerful runtime environments that work for many applications, as I see things, it's more crucial to learn as much as possible about the specific domain. If I have to indicate a factor to improve the overall quality of code, then that would be deep understanding of the domain and appropriate modeling. Domain-Driven Design (DDD) is a particular approach to software design and development that Eric Evans introduced over a decade ago. Details of the DDD approach to software development are captured in the book “Domain-Driven Design” that Evans wrote for Prentice Hall back in 2003. DDD is about crunching knowledge about a given business domain and producing a software model that faithfully mirrors it. The business domain is how a company does its own business: it's about organization, processes, practices, people, and language. The business domain lives in a context.
DDD exists to give you guidelines on how to model business domains. DDD is easy and powerful if you crunch enough knowledge and can build a model faithfully. DDD is painful and poor if you lack knowledge or fail when it comes to turning knowledge into a model for the business domain. Not coincidentally, DDD initially developed in the Java space, where, in the beginning of the last decade, the adoption of advanced design techniques was much higher than in the .NET space. Actually, for many years, the relevance of DDD as a design methodology was not really perceived in the .NET space. Probably, it was because there was really no need for it for a long time. One question I've been asked about DDD - and I've asked myself - many times: Do I really need it?
In general, DDD isn't for every project because it requires mastery and, because of that, it may have high startup costs. At the same time, nothing in DDD prevents the use of it in a relatively simple project. The two biggest mistakes you can make about DDD are jumping on the bandwagon because it sounds cool and stubbornly ignoring it because you think that all in all your system is only a bit more complex than a plain CRUD.
In addition, DDD is often misunderstood as only being an object-oriented domain model. On the way to finding the plusses of a DDD approach compared to a canonical database-driven approach, many times, I failed because I put the whole thing down as objects versus data readers. DDD is much more than modeling a business domain via objects. There are two distinct parts in DDD: the analytical and the strategic. You always need the former and may sometimes happily ignore the latter.
The analytical part sets an approach to express the top-level architecture of the business domain in terms of distinct and isolated bounded contexts. The strategic part relates to the definition of a supporting architecture for each of the identified bounded contexts. The real value of DDD lies in using the analytical part to identify bounded business contexts and their relationships. This phase is known as context mapping. In DDD, context mapping is paramount and modeling the domain through objects is only one of the possible options, although it's the one the most broadly used. Put another way, you can do DDD to analyze the system and then decide that a given bounded context is best built as a plain two-tier data-bound system that uses ADO.NET and stored procedures for data access: no O/RMs, no LINQ providers, no aggregates, and no events.
Let's find out more about the analytical part of DDD and the tools it offers to understand the business domain and possibly model it through an object-oriented domain model.
The analytical part of DDD consists of two correlated elements: one is the ubiquitous language and the other is the aforementioned bounded context. The ubiquitous language is a vocabulary shared by all parties involved in the project and ideally used in all forms of spoken and written communication within the project. The ubiquitous language has the purpose of speeding up the acknowledgment of requirements and avoiding misunderstandings, bad assumptions, and translations from one jargon to another. As an architect, you identify verbs and nouns that form the vocabulary as you digest the domain, read requirements, and talk to domain experts and actual customers. More importantly, the ubiquitous language is also the template that inspires the names and structures of the classes you end up writing in a possible domain model.
Initially, there's just one ubiquitous language and a single context to understand and model within the business domain. As you explore the domain further, you may discover some overlapping between nouns and verbs and find out that they are used in different contexts of the domain with a different meaning. This may take you to see the original domain split into multiple subdomains.
Bounded context is the term that DDD uses to refer to areas of the domain that are better treated independently because of their own ubiquitous language. Put another way, you recognize a new bounded context when the ubiquitous language changes. Bounded contexts are often related to each other. In DDD, a context map is the diagram that provides a comprehensive view of the system being designed and expresses the relationships between bounded contexts. Relational patterns between DDD-bounded contexts are of two main types: upstream and downstream. The upstream context influences the downstream as its implementation and interface may force the downstream context to change. The downstream context, by contrast, is passive and undergoes changes made on the upstream context.
Figure 1 presents a diagram representing a sporting club business domain where some overlapping exists between subdomains. The overall domain is split in two contexts - Backoffice and Club site. A couple of entities - specifically Member and Payment - exist in both contexts. Defining the contours of both contexts gets a bit problematic and requires deep analysis of requirements and understanding of the domain. Anyway, that's the idea of domains and bounded contexts.
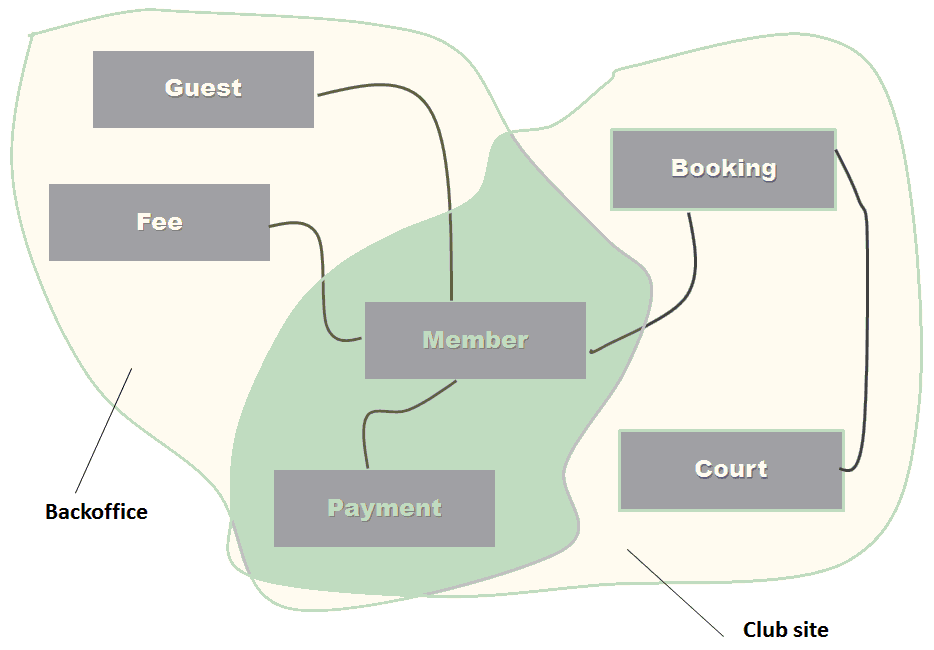
In a software world for which applications serve the purpose of driving business, an architect that misses some of the points of a business domain makes a mortal sin that deserves punishment in the software Hell.
#5 Too Rigid is Too Bad
Another mortal sin of software development is insisting on a technology regardless of the problem. General wisdom puts this aspect down as “if all you have is a hammer everything looks like a nail.” Let's see a few instances of this problem.
One of the biggest changes in the recent history of software computing is the advent of document databases as an alternative way of storing data in the data-access layer of systems. As usual, some developers just love it and some are skeptical. In a company, there are commonly two or three developers on the team that push it forward and usually older developers that slow it down. Nobody has arguments that are completely unbiased and objectively valid. I'd say that this just one of those situations in which everybody is right and the solution is doing the right thing at the right time. When it comes to persistence, the ideal thing these days, given the type of applications we may be called to write, is polyglot persistence. Polyglot persistence is a fancy term that simply refers to using the most appropriate persistence tool for each scenario. As an example, let's consider an online store.
Some of the ideas in this article are inspired by recently released book “Microsoft .NET: Architecting Applications for the Enterprise”, 2nd edition, Microsoft Press, 2014, by Dino Esposito and Andrea Saltarello.
In such a system, you might want to persist business transactions and related information whether they be customers, orders, products, or payments. This type of information fits quite easily into a classic relational database and can be comfortably accessed via any other O/RM framework. Entity Framework, in particular, can also be used to transparently access an instance of an Azure SQL Database in the cloud. User preferences can go to the Azure table storage and be accessed through an ad hoc layer that consumes Azure JSON endpoints. Invoices, maps, pictures, receipts of delivery, etc. can go, say, to MongoDB or another document store. A graph of users who bought similar products and other products the user might also be interested in buying, and users in the same geographical area, are all examples of hierarchical information that can be stored to a graph database such as Neo4j through its .NET client.
Polyglot persistence is a great resource but its setup costs might be high at times. For the most part, you end up working with .NET clients that are relatively straightforward to use. Yet, when performance issues show up, you may find that shortage of documentation is the norm rather than the exception.
Another example of design rigidity - or lack of flexibility - can be found in relation to the overall architecture of storage. When you save data, what are you actually saving? Is it a snapshot of the current state of the system? Or is it just a log of whatever happens within the system? For many years, we just saved the last known good state of a system - for example, a recently created order. At some point, though, the state of the order changed because the order is served, then delivered, and archived. Multiple operations occur on the same order; by just tracking the last known good state, you potentially lose details of when the order got served, delivered, and archived. Is this information vital to your customers? If so, then you have two possible options: Figure out an alternate way to track key events in the lifetime of an order, or completely rewrite the architecture of storage and log all events rather than a single snapshot for each instance of an entity. The former option goes under the fancy name of Event Sourcing.
Treating observable business events as persistent data adds a new perspective to development. There's no doubt that events play a key role in today's software development. But are events and Event Sourcing really a new idea? As mentioned, the modeling problems they help to address have been in the face of developers for decades. If we look back, we find out that approaches very similar to what we today call Event Sourcing - storing events instead of data - have been used for more than 30 years in banking and using languages like COBOL.
Event Sourcing works as an alternative to or in conjunction with classic relational storage of snapshots of the system's state, as in a plain CRUD system. When is Event Sourcing really compelling? The most compelling scenario is when the business demands that the intent and purpose of data operations are captured. For example, if you are requested to display the activity of a user within a booking system–all bookings that she made, modified, or canceled–then it's key that you track any operation and save proper data. Another suitable scenario for Event Sourcing is when you need to perform some work on top of recorded events. You might want to be able to replay events to restore the (partial) state of the system, undo actions, roll back to specific points, and compensate actions. In general, Event Sourcing works well for all situations in which you need to decouple the storage of raw data from materialized data models. You have data stored, but can build any data model that suits the application from there.
This is really powerful. Where might you want a field where this aspect is so powerful? In Business Intelligence. In addition, Event Sourcing may also save you from the burden of controlling conflicting updates to data. You let each concurrent client record an event and then replay events to build the resulting state of the involved aggregate. Event Sourcing is appropriate not only when a basic CRUD system does its job well and serves all purposes of the application.
In these days of complex software whose specifications change frequently and significantly, not being ready to catch the essence of things and not being sufficiently flexible in the use of the technologies as well as in the architecture and design can lead to exceeding budgets. It's enough to condemn you eternally to Hell.
#6 Sinking with Async
With the brilliant excuse that human beings are asynchronous by default, especially in WinRT, most (if not all) of the API has been made asynchronous. I wouldn't be too much surprised if, in WinRT, getting the current time from the system is an async operation. I haven't checked this one in particular and I daren't, but how about the pleasure of one day writing some code like this?
// Hopefully fake code snippet
var now = await DateTime.NowAsync();
I've been advocating async Web page requests since ASP.NET 2.0 came out about a decade ago, so I think I know very well that asynchronous operations are an aspect of programming. Some operations are definitely better coded asynchronously and there's nothing weird or wrong with this. What I miss is the point of turning a large part of the system API into an async API. Frankly, I find any of the following “official” reasons a bit specious:
- Users expect apps to be responsive to all interactions.
- You don't want to indefinitely see the spinning donut after you click a button.
- You lose customers and billions of dollars if your app doesn't reply in half a millisecond.
Of course, I'm not questioning that I/O bound operations may affect the perceived performance of the application. Frankly, I find it to be an exaggeration that every piece of the API has been made async in WinRT. Humans might be async by default, but developers aren't because developers have been thinking synchronously for ages. I would have preferred to have async facilities as an option, rather than enforced in the name of some alleged performance improvement.
In general, I'm worried that enforcing async misses the primary point that authors of the API likely wanted to achieve: helping developers write better code for the next Windows. As I see things, it's essential to let people understand what's wrong and find a better way of doing things. If you code an operation synchronously and it blocks or significantly slows down the application, then you understand that you must find a better way of performing the task and you understand why the async API exists.
When I question the decision of making the whole API asynchronous, I often receive the argument that I'm not a true Windows Phone or Windows 8 mobile developer. I then look into the iOS and Android SDKs, and I find synchronous APIs for things like reading the local storage and making Web requests. Who's right then?
But it's not a matter of being right or wrong. The point is to give developers tools for doing their jobs in the best possible way. In iOS and Android, setting up an asynchronous call is up to you through threads. In Windows, it's much easier because of async/await and ad hoc API. But I still wish I could place a trivially stupid synchronous call when I think I need it.
#7 One (Responsive) Site Fits All (Devices)
A new generation of users has appeared on the horizon and will be using our software in the future. Today's youngsters are less forgiving with applications than any previous generation of users. At a time in which most of the software is on the Web and is consumed through mobile devices, the emphasis on device-independent design of Web pages seems just out of place–to say the least. Yet this is the message we're receiving from many authorities: be smart, be responsive, but ignore the device.
There was a time, and it was not that many months ago, in which the Web was split in two: desktop and mobile sites. Recently, the umbrella of mobile has grown significantly and now encompasses any sort of devices - smartphones, tablets of any size, smart TVs, and next up are Google glasses and wearable devices. In general, I'd say that anything is a device, including the old faithful personal computer. And any device can be used at any time to access a website.
Regardless of how many different devices are out there, the common sentiment about Web development today is that there's nothing that a rather sophisticated style sheet can't fix. So developers say Thank You to browsers for supporting CSS media queries and boldly proceed in the name of “one site fits all devices.” I see this as the seventh mortal sin.
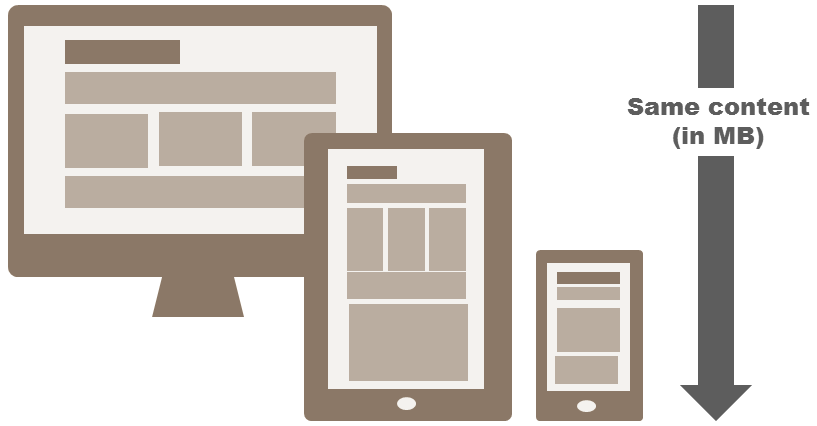
People buy many different types of devices but developers boil it down to adjusting the same content to any screen. Can any given content really fit any screen size? Or, better yet, does it really make sense to fit any content to any size? A laptop device has an average screen width of 13 inches; a smartphone is around 5. The difference is huge, physics say. A golden rule of mobile Web development says that on a smartphone, you need approximately 20% of the content of the full site. This is a great point; by fitting some specified content to any screen size, you set yourself up for throwing 80% of that content out of the window. At the end of the day, the whole concept that one bit of content can be adapted via CSS to any device of the present and future smells more every day. Look now at Figure 2. You may have seen similar diagrams many times already, and you've been told that it was a desirable thing to have. The perspective I offer is different: you can grab it by looking at the extra arrow.
Is the landscape of browsers and screen sizes ever-changing? Be smart then and bypass the problem by working out a fluid layout that adapts content to nearly any screen. This is the message of Responsive Web Design (RWD). The magic potion that gives life to responsive Web design is CSS Media Queries - essentially a form of conditional CSS styling. (See https://www.w3.org/TR/css3-mediaqueries/.)
The RWD approach works and using it is not, per se, a sin and won't condemn you to afterlife Hell. The sin consists in blindly ignoring the role of devices and the limited reach of RWD as an approach. I suggest that you make yourself aware of the pros and cons and then responsibly decide what works best for you. There's some advice that bounces here and there: do feature detection and avoid device detection. Overall, I think this is a rather simplistic way of looking at things. How would you detect actual features without knowing about the device? Programmatic feature detection works for browser functionalities (support for local storage, Web sockets, and the like). It doesn't tell you whether a browser is within an app or about the operating system behind. Often, all you need to know is the class of the device - not the specific device. All you need to arrange effective views is to know whether the device is a smartphone or a tablet. And you don't want to force users to type a different URL for that. Whether you have a single website for multiple devices or just redirect to an optimized site, you need to know about the requesting device. Recognizing the device can only be done looking at the user agent string. Looking at the user agent string is not work you can honestly do in-house; not today. You need expert help in the form of external frameworks like WURFL. (See http://www.scientiamobile.com/.)
The WURFL framework comes in various flavors - free and with a commercial license. Let me briefly recap the latest additions to the framework, both of which are client-side and free for everybody to use. One is the WURFL.IO JavaScript library.
<script type="text/javascript"
src="http://wurfl.io/wurfl.js"></script>
The net effect is that the DOM of the page is enriched with JavaScript like this:
var WURFL = {
"complete_device_name":"generic web browser",
"is_mobile":false,
"form_factor":"Desktop"};
The form_factor property is what you use if you want to know the class of the device. Feasible values of the form_factor property are: Desktop, App, Tablet, Smartphone, Feature Phone, Smart-TV, and Robot. If you're writing a JavaScript-intensive Web client application, you can use WURFL.js to make a further call to the server and dynamically download the proper view.
In a world in which applications drive business, an architect that misses some of the points of a business domain makes a mortal sin.
The major benefit of detecting the actual device is that you can serve up intelligent markup and minimize the data to download. When you use RWD, the displayed content adapts to the size of the screen, meaning that there's nearly no difference between an 800px wide screen whether it comes from a tablet or a resized desktop browser window. One of the most painful points of RWD is the handling of images. When you set up the site, you necessarily target the largest screen and remove pieces as the size reduces. What about the size of the images? Is there a way to automatically resize images instead of having them loaded in multiple resolutions on the server and referenced individually? WURFL Image Tailor (WIT) is a free service that detects the device, figures out its known screen size, and then resizes and serves the image accordingly. All of this is transparent for the developer and, of course, the user. Here's how to use it.
<img src="//wit.wurfl.io/http://.../images/a.jpg">
You pass the full URL of the original image and receive a properly resized image that's tailor-made for the capabilities of the requesting device. Find out more about WIT at https://web.wurfl.io/#wit.
What about Purgatory and Heaven?
The Divine Comedy proceeds through Purgatory and up to full happiness in Heaven. In software, it's all about Hell. We just survived the notorious DLL Hell, but several other forms of Hell are looming. Let's do all we can to avoid or at least indefinitely postpone that. The Hell for developers is a place on earth; but we can bring also Heaven down to earth by avoiding mortal development sins.
I don't expect you all agree with the list of sins and also with the idea that there are developer's sins. Well, that's the point - let's talk!
